{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
An AI that learns to be a Jedi on its own. All feedback comes from within the agent itself. Specificaly, it learns to predict the future and rewards itself for finding (image/pixel-based) states that it cannot anticipate -- i.e. "curiosities". Uses 3 neural networks (actor-critic, inverse dynamics, and future-predicting).
[Demo Video 1] (pure curiosity; explores tattooine main area, ship area, and bar area in a few minutes)
[Demo Video 2] (curiosity + momentum reward)

Simply change:
hwnd = win32gui.FindWindow(None, 'EternalJK')to
hwnd = win32gui.FindWindow(None, 'YOUR GAME WINDOW NAME HERE')The system makes no game-specific assumptions besides the window name and optional momentum reward component (which gracefully defaults to 0 when the OCR fails).
first time:
1. Run EternalJK game and join a multiplayer server.
3. Configure your game controls to be the same as mine (see first 2 hyperparameters below).
3. python jka_noreward.py new
4. let it play
5. press c to stop
options:
python jka_noreward.py new
python jka_noreward.py
python jka_noreward.py new sign
python jka_noreward.py view
python jka_noreward.py show
- new = don't load a saved model
- sign = use sign gradient descent optimizer instead of adam optimizer
- view = save the agent views as pngs (good for confirming window capture is working properly)
- show = show the parameter counts of each of the 3 neural networks
- Windows
- Python
python -m pip install gym torch win32gui pillow torchvision numpy keyboard mouse ctypes pynput win32ui win32con win32api easyocr matplotlib
The things that you usually tune by hand. For eaxmple, I'm running this on a laptop GPU, someone with many high-end GPUs might wish to increase the size of their neural networks. Alternatively someone running on CPU might want to decrease their sizes in order to achieve an agent framerate of at least 10 iterations per second.
# Hyperparameters
key_possibles = ['w', 'a', 's', 'd', 'space', 'r', 'e'] # legend: [forward, left, back, right, style, use, center view]
mouse_button_possibles = ['left', 'middle', 'right'] # legend: [attack, crouch, jump]
mouse_x_possibles = [-1000.0,-500.0, -300.0, -200.0, -100.0, -60.0, -30.0, -20.0, -10.0, -4.0, -2.0, -0.0, 2.0, 4.0, 10.0, 20.0, 30.0, 60.0, 100.0, 200.0, 300.0, 500.0,1000.0]
mouse_y_possibles = [-200.0, -100.0, -50.0, -20.0, -10.0, -4.0, -2.0, -0.0, 2.0, 4.0, 10.0, 20.0, 50.0, 100.0, 200.0]
n_actions = len(key_possibles)+len(mouse_button_possibles)+len(mouse_x_possibles)+len(mouse_y_possibles)
n_train_processes = 1 # 3
update_interval = 10 # 10 # 1 # 5
gamma = 0.98 # 0.999 # 0.98
max_train_ep = 10000000000000000000000000000 # 300
max_test_ep = 10000000000000000000000000000 #400
n_filters = 64 # 128 # 256 # 512
input_rescaling_factor = 2
input_height = input_rescaling_factor * 28
input_width = input_rescaling_factor * 28
conv_output_size = 34112 # 22464 # 44928 # 179712 # 179712 # 86528 # 346112 # 73728
pooling_kernel_size = input_rescaling_factor * 2 # 16
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print('using device:', device)
forward_model_width = 4096 #2048
inverse_model_width = 1024 #2048
mouse_rescaling_factor = 10
dim_phi = 100
action_predictability_factor = 100
n_transformer_layers = 1
n_iterations = 1
inverse_model_loss_rescaling_factor = 10
jka_momentum = 0
reward_list = []
average_reward_list = []
learning_rate_scaling_factor = 10 ** -10 # 0.01- https://github.com/pathak22/noreward-rl for the general concept of curiosity-driven learning and its formalization
- https://github.com/seungeunrho/minimalRL for the A3C actor-critic reinforcement learning algorithm
- https://github.com/pytorch/examples/blob/main/mnist/main.py for the convolutional neural network setup
- https://github.com/TeaPearce/Counter-Strike_Behavioural_Cloning for the non-uniform bucketing of mouse movements
Here reward is the intrinsic reward as described in figure 2 of https://pathak22.github.io/noreward-rl/resources/icml17.pdf:
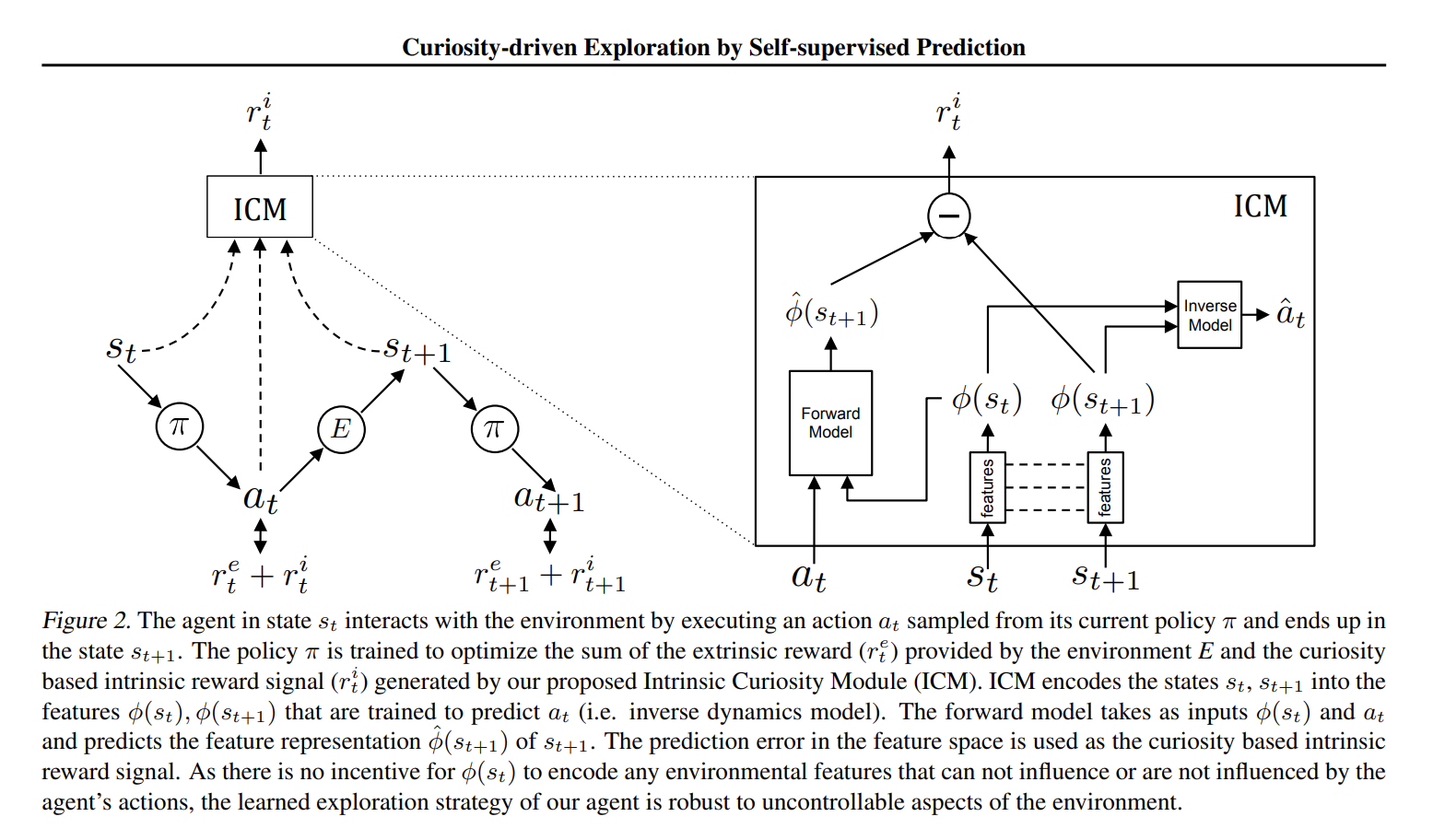
- R is the cumulative expected future rewards (with exponential decay factor gamma = 0.99, ie future rewards are less desirable than the same immediate rewards)
- so for example if the AI is playing at 10 frames per second then a reward of 100 two seconds into the future is worth gamma^(2*10) * 100 = (0.99)^20 * 100 = 8.17
- the key difference here is that the rewards are not external (eg via a game score) but internal (ie "curiosity" as computed by the agent)
- to quote the paper: "We formulate curiosity as the error in an agent’s ability to predict the consequence of its own actions in a visual feature space learned by a self-supervised inverse dynamics model."
- intuitively this means the agent is drawn towards outcomes it cannot itself anticipate
- theoretically this motivates the agent to not stand still, to explore other areas of the map, and to engage with other players
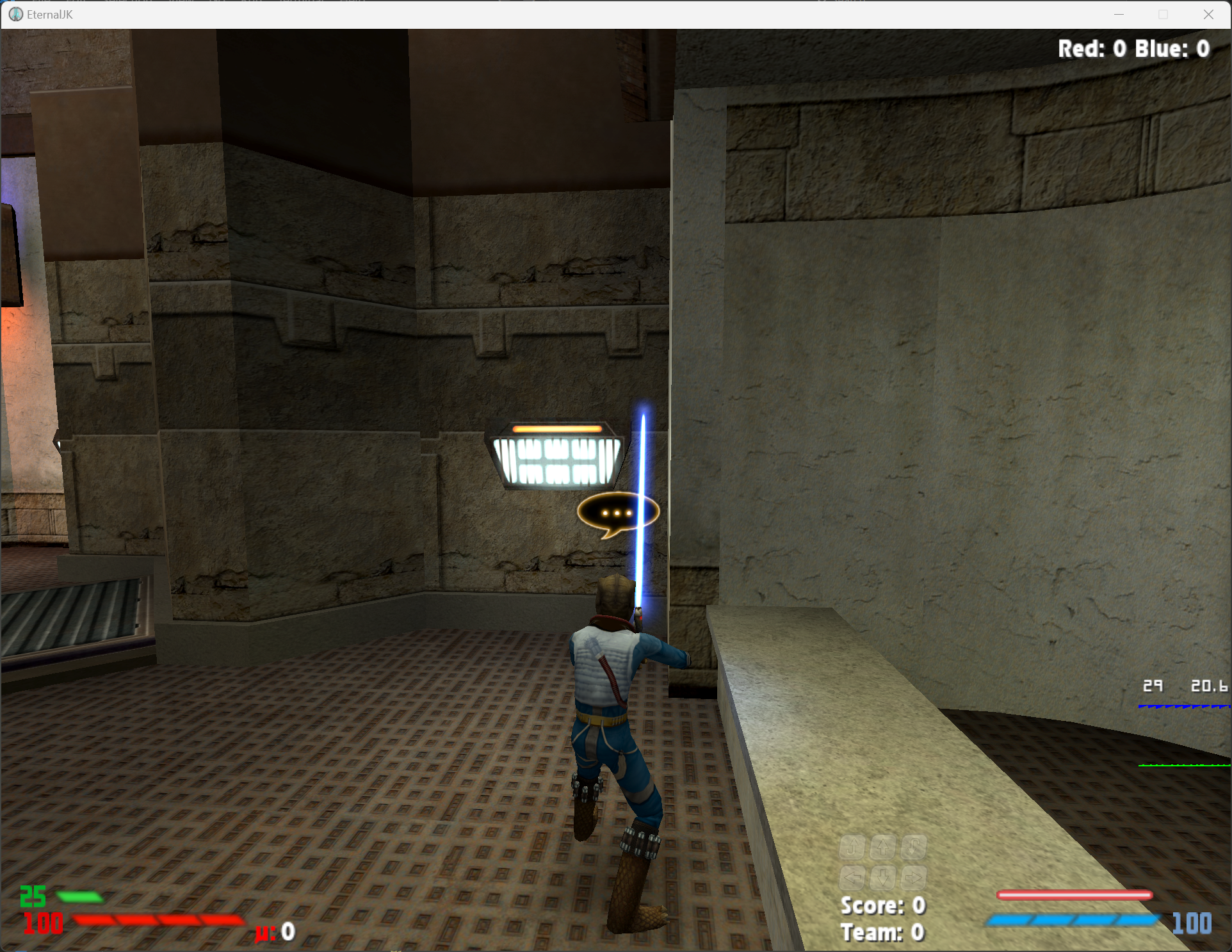
- for the momentum reward, Jedi Academy/EternalJK has a hud option to display momentum (mu, bottom left), this is then scraped using optical character recognition and added to the reward
Here is a plot of the agent reaching an average momentum of 125.28 over the course of 4924 iterations at 12.58 frames per second (so in about 7 minutes).
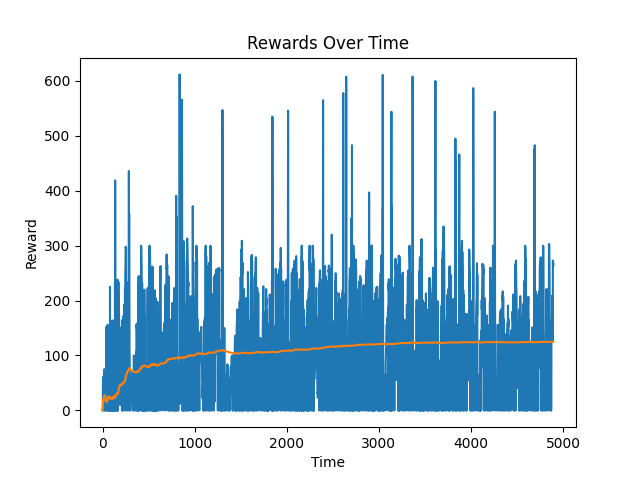
--------- n_iterations: 4924
framerate: 12.576528699083365
mouse_dx: 954.0
mouse_dy: 56.0
take action time: 0.0039446353912353516
jka_momentum: 223
confidence: 0.9996992385578382
screenshot time: 0.05179238319396973
imprecise (Windows) time between frames: 1.00000761449337e-07
error_inverse_model: 6.621382713317871
error_forward_model: 5.904290676116943
reward components: 5.904290676116943 6.621382713317871 223
reward: tensor(222.2829, device='cuda:0', grad_fn=<AddBackward0>)
average momentum: 125.28060913705583
For comparison here is a plot of the agent with zero learning rate which maintains an average momentum of 78.87 over the same duration.
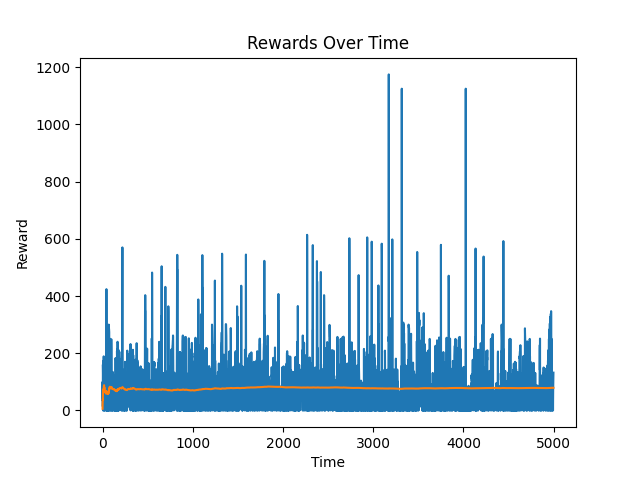
--------- n_iterations: 5017
framerate: 12.430374905295569
mouse_dx: 1222.0
mouse_dy: -14.0
take action time: 0.0030913352966308594
jka_momentum: 7
confidence: 0.9999712707675634
screenshot time: 0.04767346382141113
imprecise (Windows) time between frames: 1.00000761449337e-07
error_inverse_model: 7.6601433753967285
error_forward_model: 15.940906524658203
reward components: 15.940906524658203 7.6601433753967285 7
reward: tensor(15.2808, device='cuda:0', grad_fn=<AddBackward0>)
average momentum: 78.86927062574759
- stacked frames for better time/motion perception ✅
- a memory of the past via LSTM (as done in the curiosity paper) or transformer
- integrate YOLO-based aimbot: https://github.com/petercunha/Pine
- add multiprocessing, especially for taking screenshots (12 fps -> >18 fps)
- ensure all cpus are being utilized
before resizing:
after resizing (ie true size agent view), but before grayscaling: