Allows loading the contents of clipboard as a Spark data frame. This is targeted for testing and e.g. Stack Overflow users. Given a printed data frame
+----+----+
|foo |bar |
+----+----+
| 1| a|
| 2| b|
+----+----+
it requires some overhead to load that as a spark data frame.
This project contains two components to help developers.
- A hadoop file format that can read clipboard. This allows reading the contents without storing it as an intermediate file.
- A Spark input format that can parse the
Dataset.showoutput string as a data frame. The idea is based on discussion in this thread https://stackoverflow.com/questions/48427185/how-to-make-good-reproducible-apache-spark-examples/48454013#48454013
The file system needs to be registered when creating the Spark session:
val spark = SparkSession
.builder()
.master("local")
.config("fs.clipboard.impl", "com.github.ollik1.clipboard.ClipboardFileSystem")
.getOrCreate()
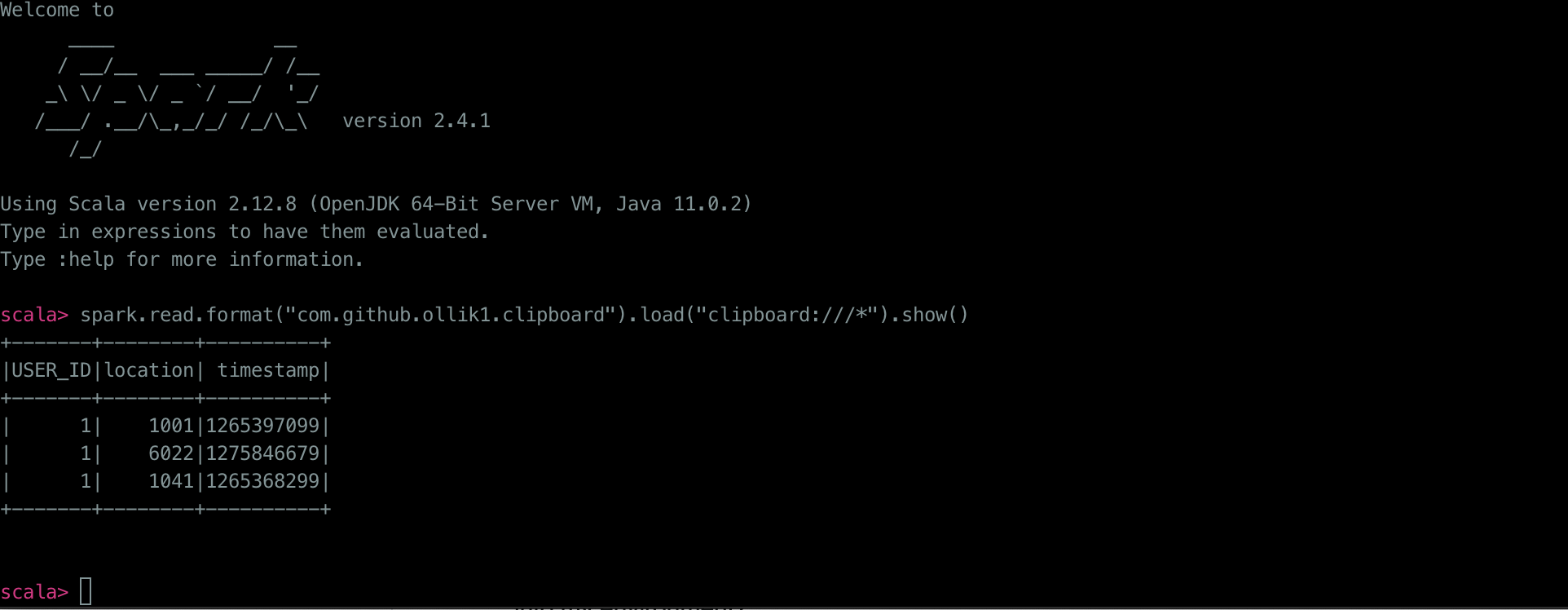
After this, it is possible to create data frames from copied print outputs:
val df = spark.read
.format("com.github.ollik1.clipboard")
.load("clipboard:///*")
Naturally, the components are independent from each other and it is possible to read files containing Spark show outputs or read pure CSV or any other supported format from clipboard.
Make sure jcenter resolver is enabled
resolvers += Resolver.jcenterRepo
and add the dependency
libraryDependencies += "com.github.ollik1" %% "spark-clipboard" % "0.1"
Similar steps apply for maven, gradle, etc.
Add the following lines to conf/spark-defaults.conf
spark.jars.repositories=https://dl.bintray.com/ollik1/spark-clipboard/
spark.jars.packages=com.github.ollik1:spark-clipboard_2.12:0.1
and conf/core-site.xml
<configuration>
...
<property><name>fs.clipboard.impl</name><value>com.github.ollik1.clipboard.ClipboardFileSystem</value></property>
...
</configuration>
Consider this question on Stack Overflow https://stackoverflow.com/questions/55387384/more-convenient-way-to-reproduce-pyspark-sample
After following the installation steps, we can now go to the post and copy the printed data frame from the question to system clipboard

and then go to Spark shell to create a data frame based on the contents