
![]()
![]()
![]()
Atree provides scalable arrays and scalable ordered maps. It is used by Cadence in the Flow blockchain.
Inspired by patterns used in modern variants of B+ Trees, Atree provides two types of data structures: Scalable Array Type (SAT) and Ordered Map Type (OMT).
-
Scalable Array Type (SAT) is a heterogeneous variable-size array, storing any type of values into a smaller ordered list of values and provides efficient functionality to lookup, insert and remove elements anywhere in the array.
-
Ordered Map Type (OMT) is an ordered map of key-value pairs; keys can be any hashable type and values can be any serializable value type. It supports heterogeneous key or value types (e.g. first key storing a boolean and second key storing a string). OMT keeps values in specific sorted order and operations are deterministic so the state of the segments after a sequence of operations are always unique. OMT uses CircleHash64f with Deferred+Segmented BLAKE3 Digests.
Atree uses new types of high-fanout B+ tree and some heuristics to balance the trade-off between latency of operations and the number of reads and writes.
Each data structure holds the data as several relatively fixed-size segments of bytes (also known as slabs) forming a tree and as the size of data structures grows or shrinks, it adjusts the number of segments used. After each operation, Atree tries to keep segment size within an acceptable size range by merging segments when needed (lower than min threshold) and splitting large-size slabs (above max threshold) or moving some values to neighbouring segments (rebalancing). For ordered maps and arrays with small number of elements, Atree is designed to have a very minimal overhead in compare to less scalable standard array and ordermaps (using a single data segment at start).
In order to minimize the number of bytes touched after each operation, Atree uses a deterministic greedy approach ("Optimistic Encasing Algorithm") to postpone merge, split and rebalancing the tree as much as possible. In other words, it tolerates the tree to get unbalanced with the cost of keeping some space for future insertions or growing a segment a bit larger than what it should be which would minimize the number of segments (and bytes) that are touched at each operation.
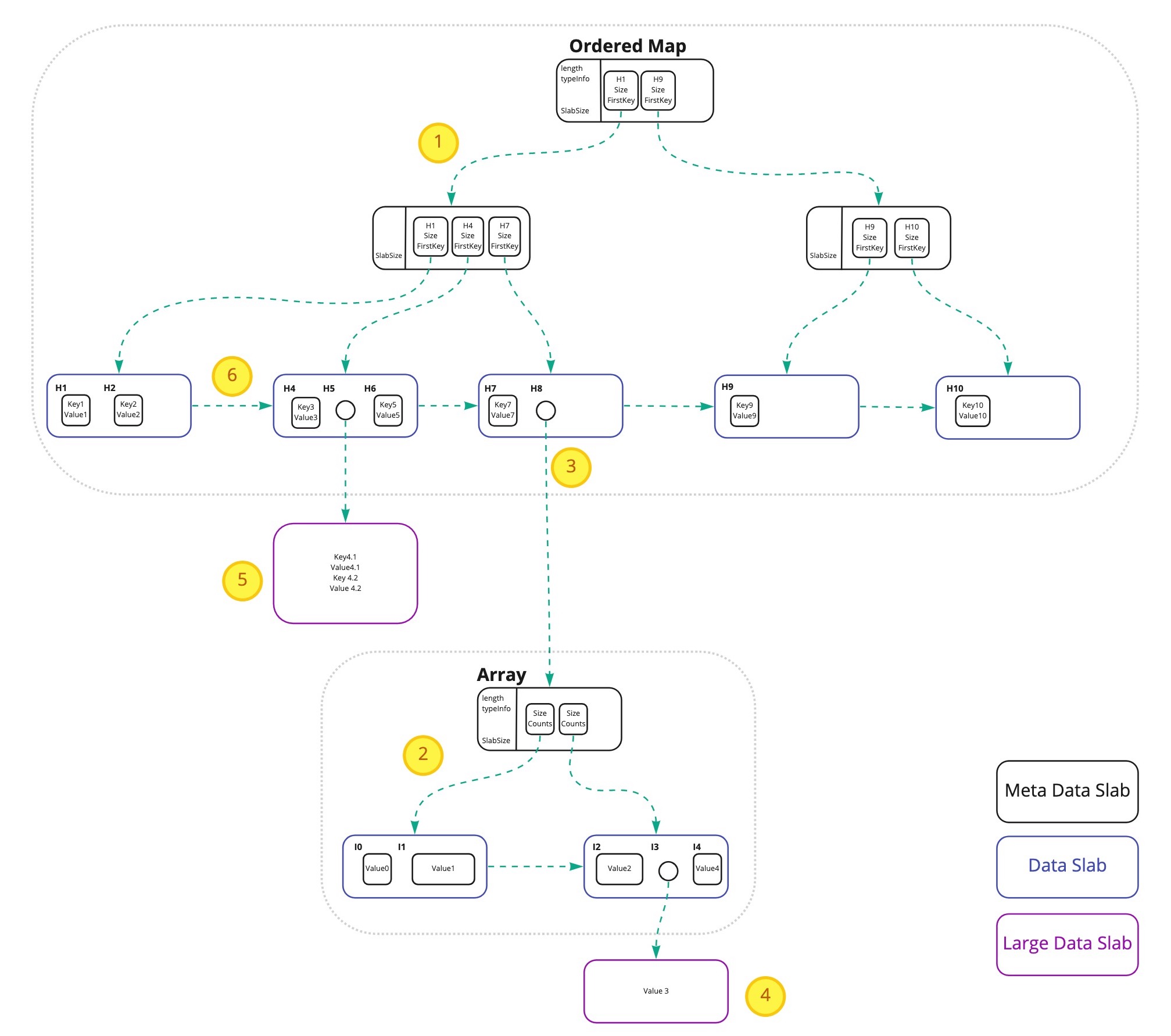
1 - An ordered map metadata slab keeps the very first key hash of any children to navigate the path. It uses a combination of linear scan and binary search to find the next slab.
2 - Similarly the array metadata slab keeps the count of each child and uses that to navigate the path.
3 - Nested structures (e.g. map holding an array under a key) are handled by storing nested map or array as separate objects and using a one-way reference from parent to the nested object.
4 - Extremely large objects are handled by storing them as an external data slab and using a pointer to the external data slab. This way we maintain the size requirements of slabs and preserve the performance of atree. In the future work external data slabs can be broken into a sequence of smaller size slabs.
5 - Atree Ordered Map uses a collision handling design that is performant and resilient against hash-flooding attacks. It uses multi-level hashing that combines a fast 64-bit non-cryptographic hash with a 256-bit cryptographic hash. For speed, the cryptographic hash is only computed if there's a collision. For smaller storage size, the digests are divided into 64-bit segments with only the minimum required being stored. Collisions that cannot be resolved by hashes will eventually use linear lookup, but that is very unlikely as it would require collisions on two different hashes (CircleHash64f + BLAKE3) from the same input.
6 - Forwarding data slab pointers are used to make sequential iterations more efficient.
Inputs hashed by OMT are typically short inputs (usually smaller than 128 bytes). OMT uses state-of-the-art hash algorithms and a novel collision-handling design to balance speed, security, and storage space.
| CircleHash64f 🏅 (seeded) |
SipHash (seeded) |
BLAKE3 🏅 (crypto) |
SHA3-256 (crypto) |
|
|---|---|---|---|---|
| 4 bytes | 1.34 GB/s | 0.361 GB/s | 0.027 GB/s | 0.00491 GB/s |
| 8 bytes | 2.70 GB/s | 0.642 GB/s | 0.106 GB/s | 0.00984 GB/s |
| 16 bytes | 5.48 GB/s | 1.03 GB/s | 0.217 GB/s | 0.0197 GB/s |
| 32 bytes | 8.01 GB/s | 1.46 GB/s | 0.462 GB/s | 0.0399 GB/s |
| 64 bytes | 10.3 GB/s | 1.83 GB/s | 0.911 GB/s | 0.0812 GB/s |
| 128 bytes | 12.8 GB/s | 2.09 GB/s | 1.03 GB/s | 0.172 GB/s |
| 192 bytes | 14.2 GB/s | 2.17 GB/s | 1.04 GB/s | 0.158 GB/s |
| 256 bytes | 15.0 GB/s | 2.22 GB/s | 1.06 GB/s | 0.219 GB/s |
- Using Go 1.17.7, darwin_amd64, i7-1068NG7 CPU.
- Results are from
go test -bench=. -count=20andbenchstat. - Some hash libraries have slowdowns at some larger sizes.
Atree's API is documented with godoc at pkg.go.dev and will be updated when new versions of Atree are tagged.
If you would like to contribute to Atree, have a look at the contributing guide.
Additionally, all non-error code paths must be covered by tests. And pull requests should not lower the code coverage percent.
The Atree library is licensed under the terms of the Apache license. See LICENSE for more information.
Logo is based on the artwork of Raisul Hadi licensed under Creative Commons.
Copyright © 2021-2022 Dapper Labs, Inc.