Node CPU/Memory metrics differ from kubectl describe #27262
Assignees

Labels
Comments
|
Pinging code owners:
See Adding Labels via Comments if you do not have permissions to add labels yourself. |
|
Please assign this to me. |
This was referenced Sep 29, 2023
This was referenced Oct 3, 2023
|
This issue has been inactive for 60 days. It will be closed in 60 days if there is no activity. To ping code owners by adding a component label, see Adding Labels via Comments, or if you are unsure of which component this issue relates to, please ping Pinging code owners:
See Adding Labels via Comments if you do not have permissions to add labels yourself. |
TylerHelmuth
pushed a commit
that referenced
this issue
Dec 8, 2023
…st metrics. (#27299) **Description:** The `node_<cpu|memory>_request` metrics and metrics derived from them (`node_<cpu|memory>_reserved_capacity`) differ from the output of `kubectl describe node <node_name>`. This is because kubectl [filters out terminated pods](https://github.com/kubernetes/kubectl/blob/302f330c8712e717ee45bbeff27e1d3008da9f00/pkg/describe/describe.go#L3624). See linked issue for more details. Adds a filter for terminated (succeeded/failed state) pods. **Link to tracking Issue:** #27262 **Testing:** Added unit test to validate pod state filtering. Built and deployed changes to cluster. Deployed `cpu-test` pod. 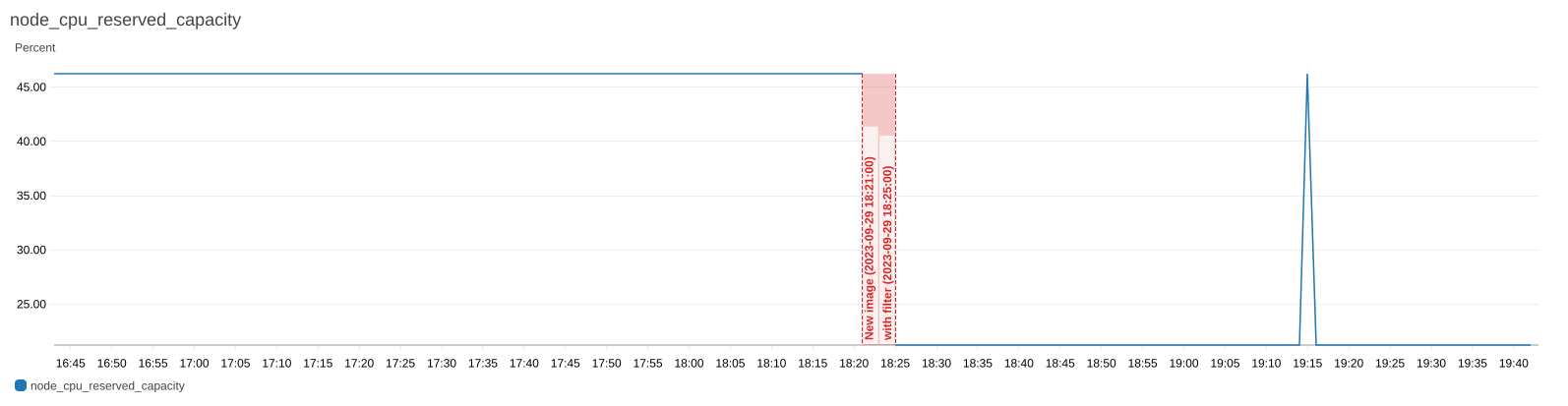 The gap is when the change was deployed. The metric drops after the deployment due to the filter. The metric can be seen spiking up while the `cpu-test` pod is running (~19:15) and then returns to the previous request size after it has terminated. **Documentation:** N/A
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Component(s)
receiver/awscontainerinsight
What happened?
Description
In certain scenarios where there are terminated pods that are not cleaned up, the
node_cpu_requestandnode_cpu_reserved_capacitydo not match the outputs ofkubectl describe node <node_name>. The main reason is due to the differences in the way thenode_cpu_requests are calculated (node_cpu_reserved_capacityis derived from thenode_cpu_request). In the receiver, the CPU request is an aggregate of all pods on the node.opentelemetry-collector-contrib/receiver/awscontainerinsightreceiver/internal/stores/podstore.go
Lines 268 to 271 in 6f1fcba
Whereas in kubectl, describe node filters out terminated pods.
https://github.com/kubernetes/kubectl/blob/302f330c8712e717ee45bbeff27e1d3008da9f00/pkg/describe/describe.go#L3624
The same behavior is present for memory requests metric.
Steps to Reproduce
Create a k8s cluster and run
kubectl apply -f cpu-test.yamlwherecpu-test.yamlisThis will create a pod that will request CPU and then timeout and terminate.
With
kubectl describe node <node-name>:While the
cpu-testisRunningAfter the
cpu-testhasCompletedExpected Result
The expectation is that the metric would match kubectl and drop back down to 425/22% after the pod has completed.
Actual Result
In this case, the metric remains at 925/47%.
Collector version
v0.77.0
Environment information
Environment
OS: (e.g., "Ubuntu 20.04") AL2
Compiler(if manually compiled): (e.g., "go 14.2") go 1.20
Basic EKS cluster created with eksctl.
OpenTelemetry Collector configuration
No response
Log output
No response
Additional context
No response
The text was updated successfully, but these errors were encountered: