Fix memory unbounded Arrow data format export/import #1169
Merged
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
7c0e5b6 to
138cfcc
Compare
Signed-off-by: Kim, Vinnam <vinnam.kim@intel.com>
Signed-off-by: Kim, Vinnam <vinnam.kim@intel.com>
…impl-arrow-data-format Signed-off-by: Kim, Vinnam <vinnam.kim@intel.com>
Codecov ReportAttention:
Additional details and impacted files@@ Coverage Diff @@
## releases/1.5.0 #1169 +/- ##
==================================================
+ Coverage 79.95% 79.97% +0.01%
==================================================
Files 267 265 -2
Lines 29981 29706 -275
Branches 5898 5833 -65
==================================================
- Hits 23972 23756 -216
+ Misses 4650 4617 -33
+ Partials 1359 1333 -26
Flags with carried forward coverage won't be shown. Click here to find out more.
☔ View full report in Codecov by Sentry. |
wonjuleee
reviewed
Oct 18, 2023
wonjuleee
reviewed
Oct 18, 2023
Signed-off-by: Kim, Vinnam <vinnam.kim@intel.com>
wonjuleee
approved these changes
Oct 19, 2023
yunchu
pushed a commit
to yunchu/datumaro
that referenced
this pull request
Oct 23, 2023
…#1169) - Ticket no. 122601 - Version up Arrow data format export/import from 1.0 to 2.0 to make them memory bounded | | Before | After | | :-: | :-: | :-: | | export |  | 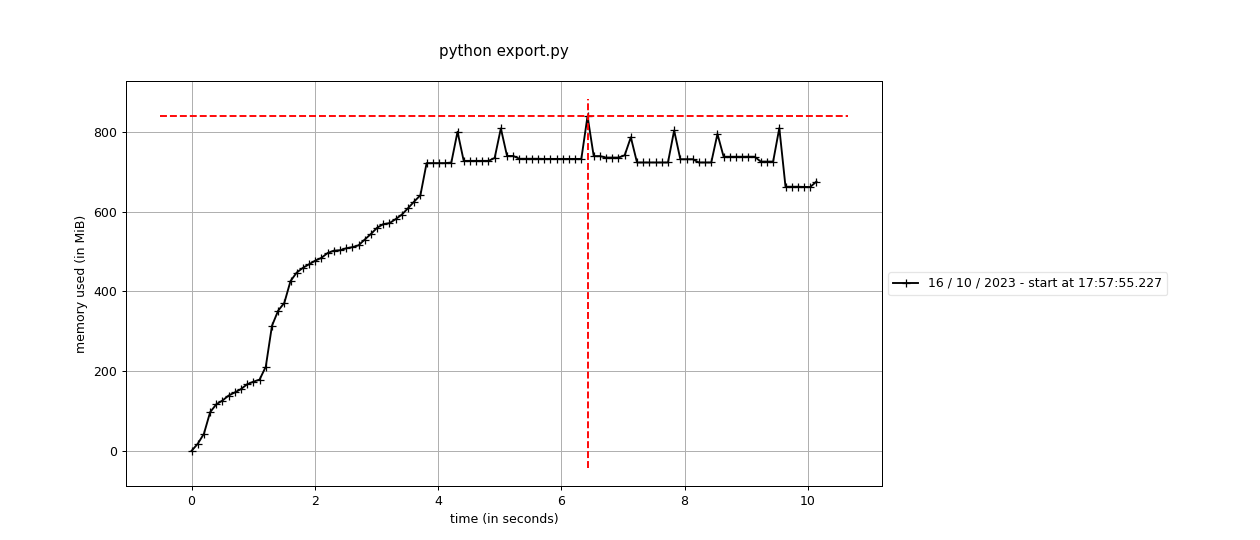 | | import |  |  | Used the following script for the above experiment. <details> <summary>1. Synthetic data preparation (10000 items with a 224x224 image and a label are exported to Datumaro data format)</summary> ```python import numpy as np from datumaro.components.media import Image from datumaro.components.project import Dataset import os from datumaro.components.dataset_base import DatasetItem from datumaro.components.annotation import Label from datumaro.util.image import encode_image from tempfile import TemporaryDirectory from datumaro.components.progress_reporting import TQDMProgressReporter def fxt_large(test_dir, n=5000) -> Dataset: items = [] for i in range(n): media = None if i % 3 == 0: media = Image.from_numpy(data=np.random.randint(0, 255, (224, 224, 3))) elif i % 3 == 1: media = Image.from_bytes( data=encode_image(np.random.randint(0, 255, (224, 224, 3)), ".png") ) elif i % 3 == 2: Image.from_numpy(data=np.random.randint(0, 255, (224, 224, 3))).save( os.path.join(test_dir, f"test{i}.jpg") ) media = Image.from_file(path=os.path.join(test_dir, f"test{i}.jpg")) items.append( DatasetItem( id=i, subset="test", media=media, annotations=[Label(np.random.randint(0, 3))], ) ) source_dataset = Dataset.from_iterable( items, categories=["label"], media_type=Image, ) return source_dataset if __name__ == "__main__": source_dir = "source" os.makedirs(source_dir, exist_ok=True) with TemporaryDirectory() as test_dir: source = fxt_large(test_dir, n=10000) reporter = TQDMProgressReporter() source.export( source_dir, format="datumaro", save_media=True, progress_reporter=reporter, ) ``` </details> <details> <summary>2. Export 10000 items to Arrow data format</summary> ```python import shutil import os from datumaro.components.progress_reporting import TQDMProgressReporter from datumaro.components.dataset import StreamDataset if __name__ == "__main__": source_dir = "source" source = StreamDataset.import_from(source_dir, format="datumaro") export_dir = "export" if os.path.exists(export_dir): shutil.rmtree(export_dir) reporter = TQDMProgressReporter() source.export( export_dir, format="arrow", save_media=True, max_shard_size=1000, progress_reporter=reporter, ) ``` </details> <details> <summary>3. Import 10000 items in the Arrow data format </summary> ```python import pyarrow as pa from random import shuffle from datumaro.components.progress_reporting import TQDMProgressReporter from time import time from datumaro.components.dataset import Dataset import memory_profiler import shutil if __name__ == "__main__": source_dir = "source" dst_dir = "source.backup" shutil.move(source_dir, dst_dir) export_dir = "export" reporter = TQDMProgressReporter() start = time() dataset = Dataset.import_from(export_dir, format="arrow", progress_reporter=reporter) keys = [(item.id, item.subset) for item in dataset] shuffle(keys) for item_id, subset in keys: item = dataset.get(item_id, subset) img_data = item.media.data dt = time() - start print(f"dt={dt:.2f}") print(memory_profiler.memory_usage()[0]) print(pa.total_allocated_bytes()) shutil.move(dst_dir, source_dir) ``` </details> Signed-off-by: Kim, Vinnam <vinnam.kim@intel.com>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Summary
Used the following script for the above experiment.
1. Synthetic data preparation (10000 items with a 224x224 image and a label are exported to Datumaro data format)
2. Export 10000 items to Arrow data format
3. Import 10000 items in the Arrow data format
How to test
It can be covered by the existing tests.
Checklist
License
Feel free to contact the maintainers if that's a concern.