This is the implementation for the paper Enhancing Zeroth-order fine-tuning for language models with low-rank structures.
In this paper, we design a low-rank gradient estimator for the zeroth-order (ZO) method and propose a novel low-rank ZO-SGD (LOZO) algorithm for fine-tuning large language models (LLMs). Additionally, we introduce an approach to combine our LOZO algorithm with the momentum technique, resulting in the low-rank ZO-SGD with momentum (LOZO-M) algorithm, which incurs almost no additional memory overhead compared to the LOZO algorithm.
Compared to existing ZO methods for LLM fine-tuning, such as MeZO, the LOZO and LOZO-M algorithms achieve superior performance across a range of tasks and model scales, along with faster convergence rates.
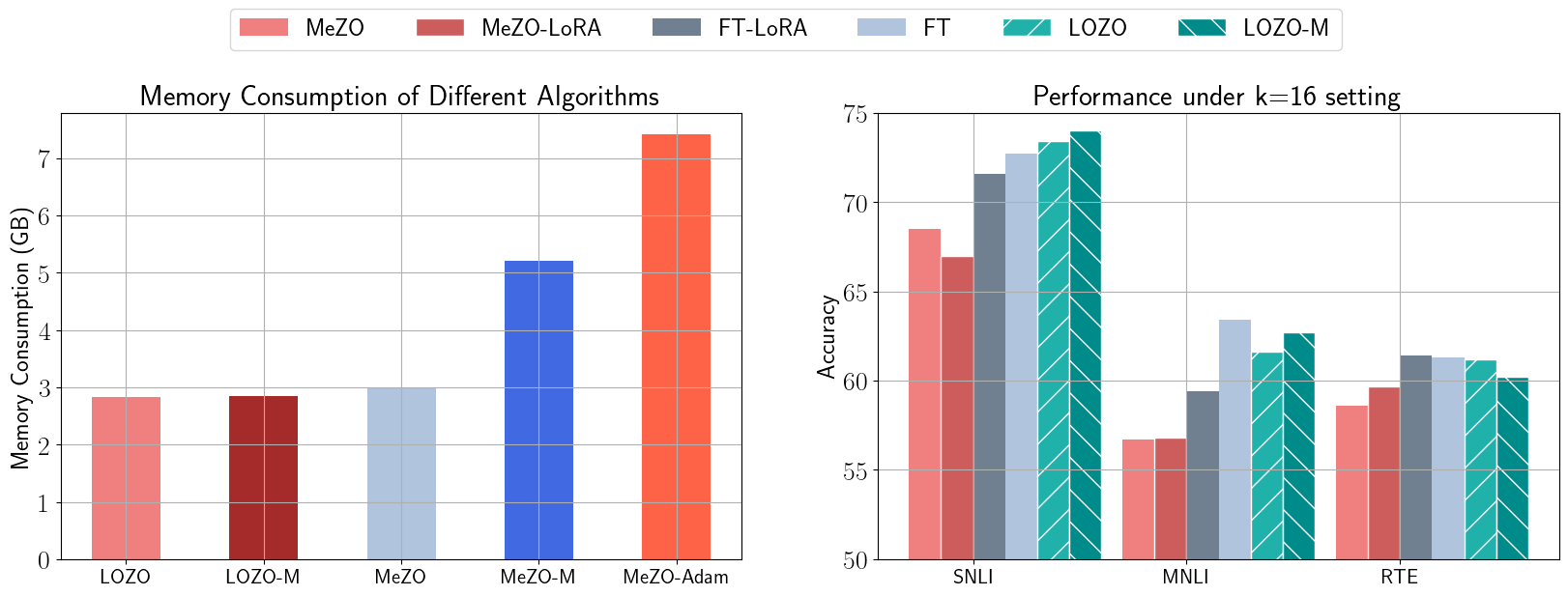 Left: GPU memory usage comparison between LOZO and MeZO with their respective variants. Right: Performance of MeZO, MeZO-LoRA, FT, FT-LoRA, LOZO, and LOZO-M on RoBERTa-large across three tasks (SNLI, MNLI, and RTE).
Left: GPU memory usage comparison between LOZO and MeZO with their respective variants. Right: Performance of MeZO, MeZO-LoRA, FT, FT-LoRA, LOZO, and LOZO-M on RoBERTa-large across three tasks (SNLI, MNLI, and RTE).
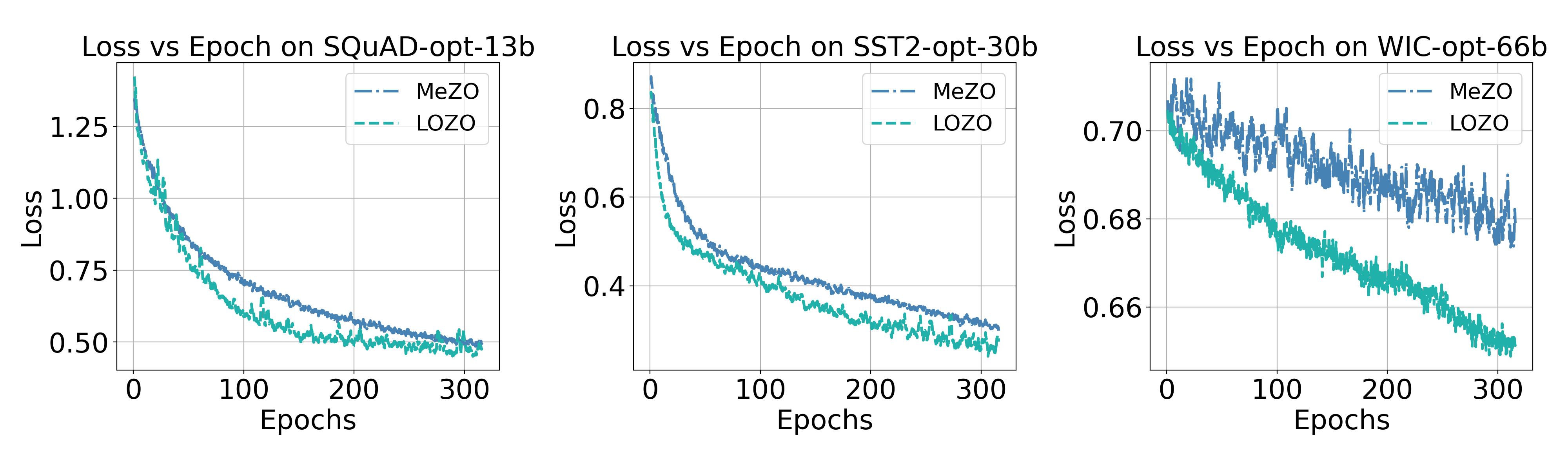 Left: Loss curves of OPT-13B on SQuAD dataset. Middle: Loss curves of OPT-30B on SST-2 dataset. Right: Loss curves of OPT-66B on WIC dataset. LOZO consistently yields faster convergence speed comapred to the baseline.
Left: Loss curves of OPT-13B on SQuAD dataset. Middle: Loss curves of OPT-30B on SST-2 dataset. Right: Loss curves of OPT-66B on WIC dataset. LOZO consistently yields faster convergence speed comapred to the baseline.
For reproducing RoBERTa-large experiments, please refer to the medium_models folder. For autoregressive LM (OPT) experiments, please refer to the large_models folder.
If you have any questions related to the code or the paper, feel free to email Yiming Chen (abcdcym@gmail.com) or Yuan Zhang (zy1002@stu.pku.edu.cn). If you encounter any problems when using the code, or want to report a bug, you can open an issue. Please provide specific details about the problem so that we can assist you more effectively and efficiently!
@article{chen2024enhancing,
title={Enhancing Zeroth-order Fine-tuning for Language Models with Low-rank Structures},
author={Chen, Yiming and Zhang, Yuan and Cao, Liyuan and Yuan, Kun and Wen, Zaiwen},
journal={arXiv preprint arXiv:2410.07698},
year={2024}
}