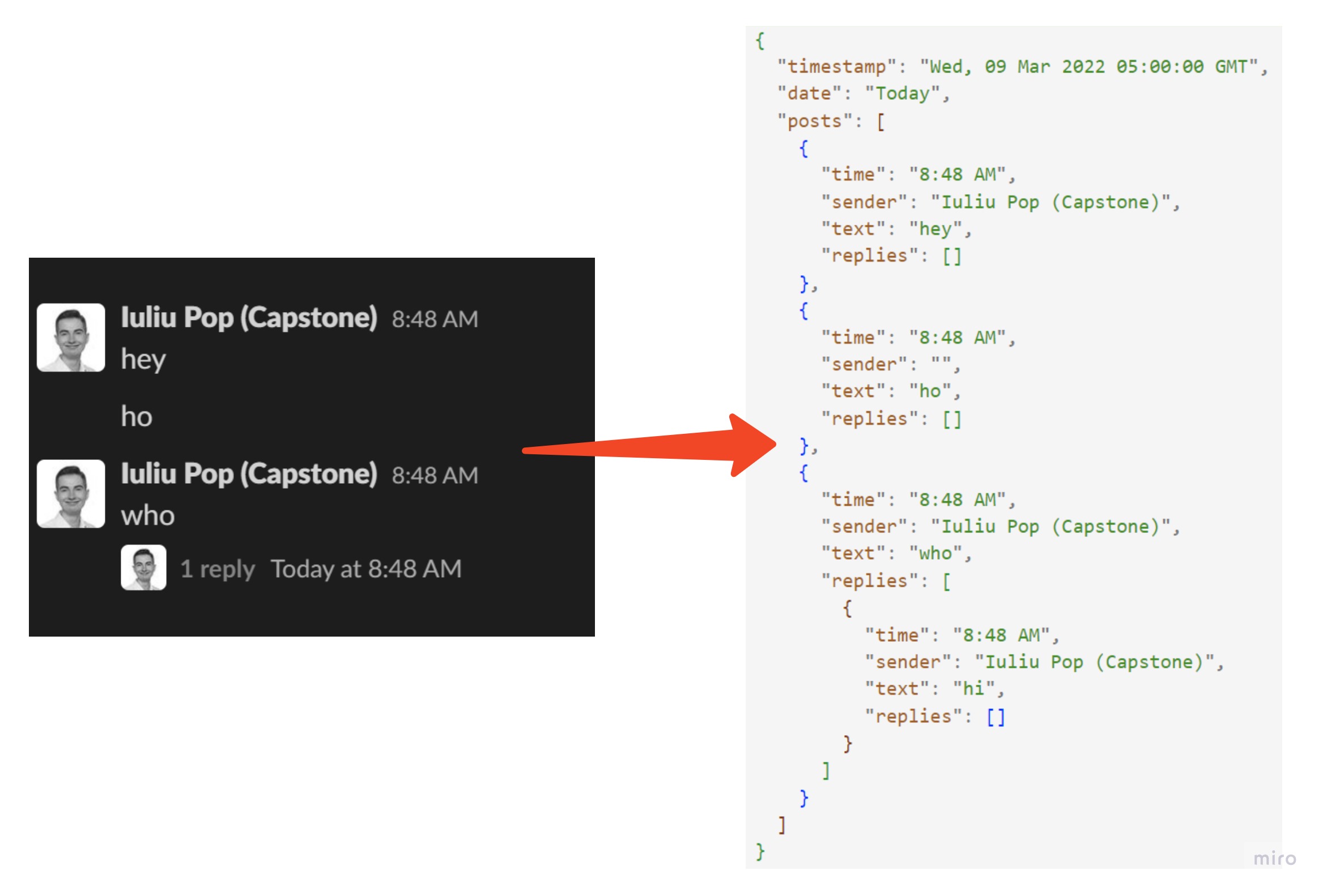
A web scraper that navigates to a Slack workspace and saves the posts and threads of a given channel or DM.
It uses Puppeteer headless browser for loading and interacting with Slack. It doesn't depend on installing an app in the Slack workspace or aquiring an API key. Instead, it logins to your Slack account and uses that to access the channel or DM.
It's helpful for saving information from a channel or DM without needing to ask a workspace administrator to export the data.
For example, if you're in the process of leaving your current company to join another, this tool is a great way to archive everything you've said and done on Slack.
- Run
npm installto install the dependencies. - Copy the
.example.envfile in the project root folder and rename it to.env. Then modify following environment variables in.env:
-
SLACK_WORKSPACE_URL,SLACK_EMAILandSLACK_PASSWORDare required.SLACK_WORKSPACE_URLmust be the URL you login to the workspace notapp.slack.com. Example:SLACK_WORKSPACE_URL=cloud-native.slack.com. Note environment variables are set without quotes.SLACK_EMAILandSLACK_PASSWORDare credentials used to login into the workspace.
-
You must set one of
CONVERSATION_NAMESorCHANNEL_NAMESor both.- The collect script will scrape the list of conversations first, then the list of channels. The list must a valid JSON array:
["element1", "element2"]. The array elements are double quoted and the last element doesn't have a trailing comma. You can escape a double quote in a string in JSON like this:["string\"hello"] - Set
CONVERSATION_NAMESto scrape a DM or group chat. The value is the name tag of the person or group chat name as is written under "Direct Messages" in Slack. Example:CONVERSATION_NAMES=["Iuliu Pop (Core Grad)", "John Doe"]. - Set
CHANNEL_NAMESto scrape a public or private channels. It's the name you see under "channels" side tab in Slack. Example:CHANNEL_NAMES=["general", "random"]. - The name doesn't need to be an exact match, it must only match part of the name. For example, if a name tag includes an emoji, you can only write the part of the name tag without it and it should work.
- The channel or the conversation must be in the list of channels or DMs in the left sidebar before running the collect script.
- The collect script will scrape the list of conversations first, then the list of channels. The list must a valid JSON array:
-
SCROLL_UP_TIMEOUTis optional.- A timeout in seconds for when to stop scrolling up the channel history and start scraping posts. Useful when scraping channels with a long history but don't need to scrape it all. For a very active channel, it could take 60 seconds to scroll up half a year then ~20min to scrape it. Example:
SCROLL_UP_TIMEOUT=30
- A timeout in seconds for when to stop scrolling up the channel history and start scraping posts. Useful when scraping channels with a long history but don't need to scrape it all. For a very active channel, it could take 60 seconds to scroll up half a year then ~20min to scrape it. Example:
-
HEADLESS_MODEis optional.- Set to
trueto scrape with the browser in headless mode. Example:HEADLESS_MODE=true. - Helpful for scraping long channel/conversation histories, since the browser runs with a larger vertical viewport so can scrape it larger batches at a time. I recommend you start without running headless mode with one conversation or channel since you can see clearer if the collect scraper is working or not.
- Set to
-
SKIP_THREADSis optional.- Set to
trueto disable scraping threads on messages that are in channels or conversations. Example:SKIP_THREADS=true. - Helpful if you do not want to scrape all the replies that are made on a message but just have the main message.
- Set to
-
Before starting the scrape, make sure the Slack App language is set to English. You can reset it once the scrape is finished.
-
Run
npm run collect. You will see the browser open and start scraping data unless you setHEADLESS_MODEtotrue. In headless mode you will see status updates on the scraping process in the console output.
You need to configure WSL to connect to a GUI even if the browser launches in headless mode. Use this guide to configure WSL to connect to an X server installed on Windows. Before running the collect script, the X server must be open and WSL correctly configured to connect to it, or Puppeteer will fail to launch the browser.
- Assuming you already ran
npm run collect, you can now runnpm run parse. You will be prompted to select the file to parse from theslack-data/folder. Once the parsing is complete, aslack-data/x.jsonfile with same name as the source HTML file will be output with the parsed posts/threads.
Thanks goes to these wonderful people (emoji key):
 Iuliu Pop 🤔 💻 📖 👀 💬 |
 William Desportes 💻 🐛 |
 NotEdwin 🐛 💻 |
This project follows the all-contributors specification. Contributions of any kind welcome!
Very open to contributions to this project! If you have questions, bug reports or features you want to see, please open an issue. If you want to contribute code, open a pull request and I'll review ASAP.