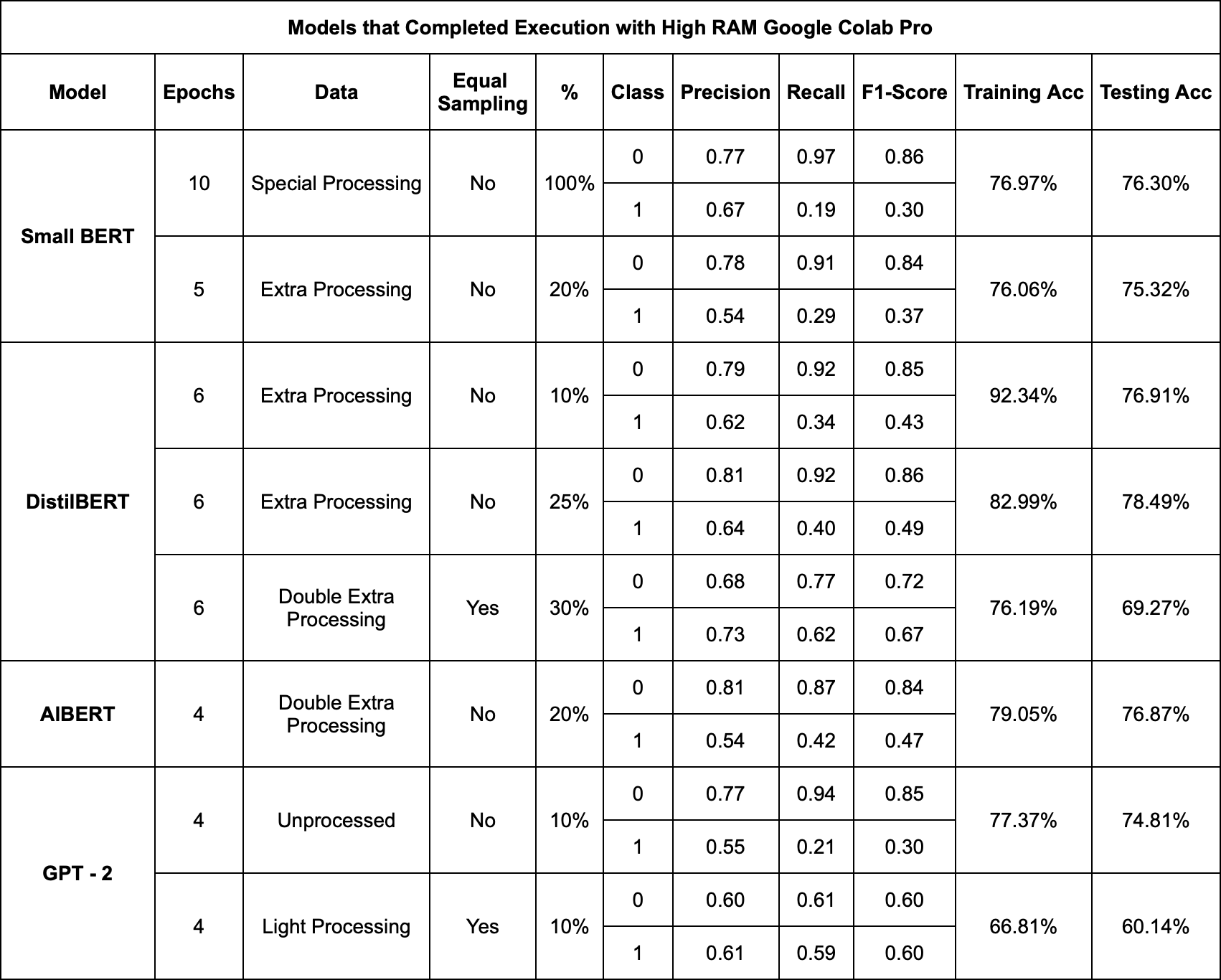
When choosing to watch a movie or TV show, reviews and ratings are often relied upon to make informed decisions. However, these reviews can inadvertently reveal significant plot details, leading to spoilers that diminish the viewing experience for newcomers. In our project, our aim is to address this issue by utilizing deep learning techniques to identify spoilers with improved accuracy.Inspired by Anyelo Lindo's research in his PhD dissertation, we seek to experiment with different architectures and assess their effectiveness in spoiler detection. In our analysis, DistilBERT with extra processing (not sampled) at 25% data achieved a higher training accuracy of 0.83 and testing accuracy of 0.78.
{kind=link}
{kind=link}
{kind=link}
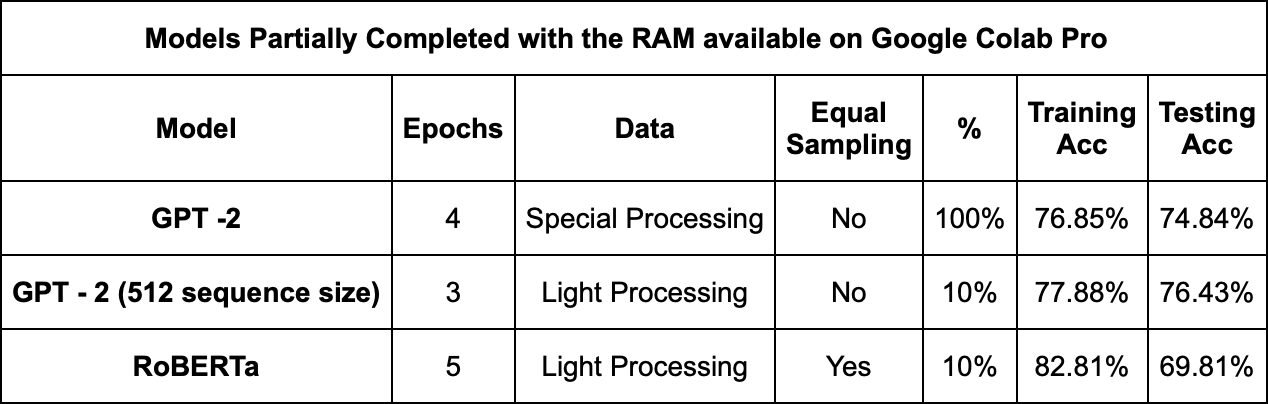
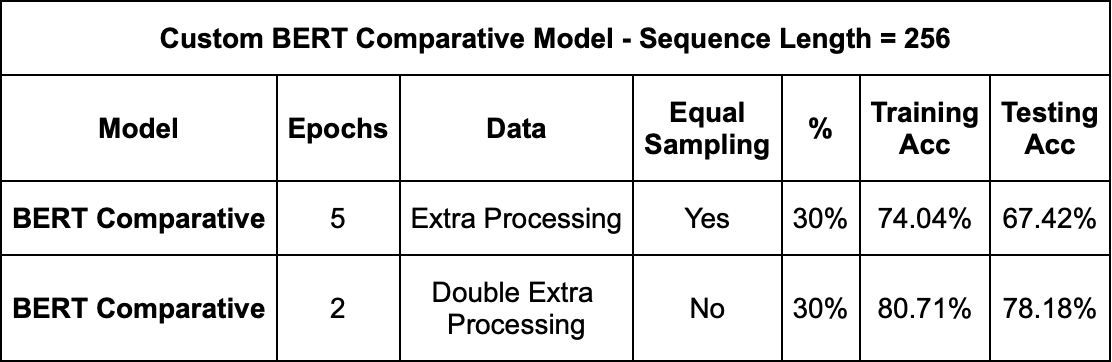
Overall, our results demonstrated that architectural choices, data preprocessing techniques, and data sampling strategies significantly impact the performance of the models. DistilBERT emerged as the top-performing with an accuracy of 78.49%. With BERT Comparative, we see that inclusion of movie plot data in BERT training showed potential for improving spoiler understanding. This model as performed well with 78.18% accuracy.
The File Structure is given below:-
AlBERT : Folder containing Variations of AlBERT model.
BERT Comparative: Folder containing Variations of BERT Comparative model.
DistilBERT : Folder containing Variations of DistilBERT model.
GPT-2 : Folder containing Variations of GPT-2 model.
RoBERTa: Folder containing Variations of RoBERTa model.
Small BERT: Folder containing Variations of Small BERT model.
Text Processing.ipynb : This notebook contains the functions we used to do text processing as seen by table below.
A single model folder can have many folders each containing a vairation of the model mentioned in the table above. Each folder has the following format of the name: x% isSampled type_of_processing. Here isSampled would denote if data used was sampled, and type_of_processing will denote the data processing techniques applied according to the table below:-
| Processing Technique | Lower | Remove Link | Remove Double Space | Special Characters | Expand Contraction | Remove Accented Characters | Stopwords |
|---|---|---|---|---|---|---|---|
| Little Processing | No | Yes | Yes | No | No | No | No |
| Extra Processing | Yes | Yes | Yes | Yes | No | No | No |
| Double Processing | Yes | Yes | Yes | Yes | No | No | Yes |
| Special Processing | Yes | Yes | No | Yes | Yes | Yes | No |
The code uses Google Colab, and Drive so that we could have trained the models faster since the data is closer to ~850MB and loading it everytime is difficult. So the steps to run any model is:-
-
Go to the folder of any architecture.
-
Select the Variation of the Model as per table given above.
-
Go to the notebook and add it to Google Colab.
-
Download
final-project-datasetsfolder from (https://drive.google.com/drive/folders/1vZjejj8mowpDr8CadvXfnj0KYBFsSFYx). -
Copy each file directory into your Google Drive, keep in my they should be located in My Drive not in any folder.
-
Connect to a GPU Runtime. Keep in mind that these notebooks were trained mostly on Pro Version of Google Colab, and we used High RAM VMs and powerful GPUs, so you may face RAM issues
-
Mount Drive in colab by clicking the Filer menu and mount drive icon, or running the following code:-
from google.colab import drive
drive.mount('/content/drive')
- Click Run All to train and evalute the respective model
=======