



A content-based Recommendation system which recommends the songs a user may like. Based on user's previous interests, it uses clustering to find similar songs and finally recommend the most similar songs.
Check this notebook for implementation
During the last few decades, with the rise of Youtube, Amazon, Netflix and many other such web services, recommender systems have taken more and more place in our lives. From e-commerce (suggest to buyers articles that could interest them) to online advertisement (suggest to users the right contents, matching their preferences), recommender systems are today unavoidable in our daily online journeys.
In a very general way, recommender systems are algorithms aimed at suggesting relevant items to users (items being movies to watch, text to read, products to buy or anything else depending on industries).
For a Recommendation system there are two most commonly used algorithms used by budding data scientists:
-
This technique is often used in recommender systems, which are algorithms designed to advertise or recommend things to users based on knowledge accumulated about the user.
-
Collaborative filtering is a technique that can filter out items that a user might like on the basis of reactions by similar users.It works by searching a large group of people and finding a smaller set of users with tastes similar to a particular user. It looks at the items they like and combines them to create a ranked list of suggestions.
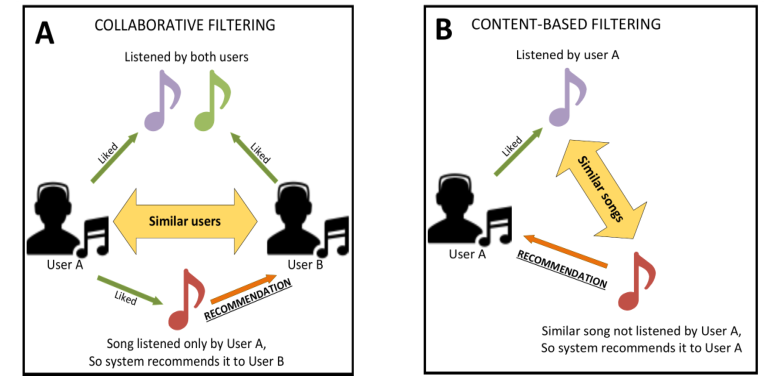

Digital cloud-based music platform that provides cross-device access to over 50 million songs, and a rapidly-rising number of podcasts. Founded in Stockholm in 2006. Spotify’s recommender system provides suggestions for users based on their historical interactions (listen/skip/add to playlist), the attributes of the songs/artists they listen to, and the preferences of what it deems “similar” users.
Well this repo demonstrates content-based recommendation, which categorises songs in form of clusters and then recommend the most similar songs.
First of all, data of about 600,000 tracks are collected from Spotify Dataset (1922-2021), each song consists of various features and based on these features, the songs are clustered using K-Means Clustering.
-
The objective of K-means is to group similar data points together and discover underlying patterns. To achieve this objective, K-means looks for a fixed number (k) of clusters in a dataset. A cluster refers to a collection of data points aggregated together because of certain similarities. Following is the plot depicting all the songs in clusters.

-
When recommending songs for a user's previous interests, the mean of all the features is used to centralised the predicting vector, then this centralised vector is then used for prediction and it forms a new data in the cluster it belongs, after the prediction it is necessary to find the most similar songs, thus cosine similarity helps to find the most relevant song in that cluster.

