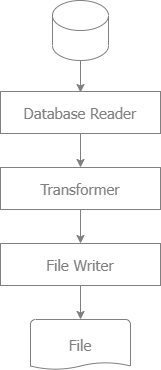
Exporting large volumes of data efficiently from SQL into a CSV or fixed-length format file requires careful consideration of memory management, I/O performance, and database interactions. This article provides an approach to optimize the process in Golang.
- RAM: 12 GB
- Disk: SSD KINGSTON SA400S37240G ATA Device
- Exec File Size: 10M
- Database: PosgreSQL 16
- Total of rows: 1.018.584 rows
- Total of columns: 76 columns
- Power Usage: Very High
- CPU: 15%
| Type | File Size | Rows | RAM | Disk | Duration | Description |
| Fix Length | 1.15 GB | 1,018,584 | 15 M | 10.1 M/s | 1 min 45 sec | Full scan the table |
| CSV | 975 MB | 1,018,584 | 15 M | 10.1 M/s | 1 min 12 sec | Full scan the table |
| Fix Length | 1.02 GB | 905,408 | 15 M | 10.1 M/s | 1 min 33 sec | Filter by index on 1 field |
| CSV | 863 MB | 905,408 | 15 M | 10.1 M/s | 1 min 3 sec | Filter by index on 1 field |
| Fix Length | 890 MB | 792,232 | 14 M | 9.9 M/s | 1 min 23 sec | Filter by index on 1 field |
| CSV | 764 MB | 792,232 | 14 M | 9.9 M/s | 55 sec | Filter by index on 1 field |
| Fix Length | 254 MB | 226,352 | 14 M | 9.9 M/s | 24 sec | Filter by index on 1 field |
| CSV | 220 M | 226,352 | 14 M | 9.9 M/s | 16 sec | Filter by index on 1 field |
Differ from online processing:
- Long time running, often at night, after working hours.
- Non-interactive, often include logic for handling errors
- Large volumes of data
- Inefficient Writing to I/O: Large writing to I/O can slow down performance. Writing each record immediately without buffering is inefficient due to the high overhead of repeated I/O operations.
- Solution: Use "bufio.Writer" for more efficient writing.
- Loading All Data Into Memory: Fetching all records at once can consume a lot of memory, causing the program to slow down or crash. Use streaming with cursors instead.
- Solution: Loop on each cursor. On each cursor, use bufio.Writer to write to database
- Inefficient Query: Full scan the table. Do not filter on the index.
- Solution: If you export the whole table, you can scan the full table. If not, you need to filter on the index.
-
Build Query: For efficient query, you need to filter on the index, avoid to scan the full table. In my sample, I created index on field createdDate. In my 6 use cases, I use 4 use cases to filter on indexing field: createdDate.
-
Scan the GO row into an appropriate GO struct:
We provide a function to map a row to a GO struct. We use gorm tag, so that this struct can be reused for gorm later, with these benefits:
- Simplifies the process of converting database rows into Go objects.
- Reduces repetitive code and potential errors in manual data mapping.
- Enhances code readability and maintainability.
type User struct {
Id string `gorm:"column:id;primary_key" format:"%011s" length:"11"`
Username string `gorm:"column:username" length:"10"`
Email string `gorm:"column:email" length:"31"`
Phone string `gorm:"column:phone" length:"20"`
Status bool `gorm:"column:status" true:"1" false:"0" format:"%5s" length:"5"`
CreatedDate *time.Time `gorm:"column:createdDate" length:"10" format:"dateFormat:2006-01-02"`
}Transform a GO struct to a string (CSV or fixed-length format). We created 2 providers already:
- CSV Transformer: read GO tags to transform CSV line.
- Fixed Length Transformer: read GO tags to transform Fixed Length line.
To improve performance, we cache the struct of CSV or Fixed Length Format.
- It is a wrapper of "bufio.Writer" to buffer writes to the file. This reduces the number of I/O operations.
- Streaming: The code uses db.QueryContext to fetch records in a streaming manner. This prevents loading all records into memory at once.
- Memory Management: Since rows are processed one by one, memory usage remains low, even when handling a large number of records.
- Cache Scanning: to improve performance: based on gorm tag, cache column structure when scanning the GO row into an appropriate GO struct.
- Cache Transforming: to improve performance, cache CSV or fixed-length format structure when transforming a GO struct into CSV format or fixed-length format.
In the sample, I tested with 1 million records, I see Postgres still used less than 14M RAM, and my program used about 15M RAM.
So, for this case, we don't need to use LIMIT/OFFSET , as long as we loop on cursor, at each of cursor, we write to file stream.
In the past, I also test with 4 million records, export 4GB, it still works.
- go-hive-export: export data from hive to fix-length or csv file.
- go-cassandra-export: export data from cassandra to fix-length or csv file.
- go-mongo-export: export data from mongo to fix-length or csv file.
- go-firestore-export: export data from firestore to fix-length or csv file.