This repository introduces the ILPC'22 Small and ILPC'22 Large datasets for benchmarking inductive link prediction models and outlines the 2022 incarnation of the Inductive Link Prediction Challenge (ILPC).
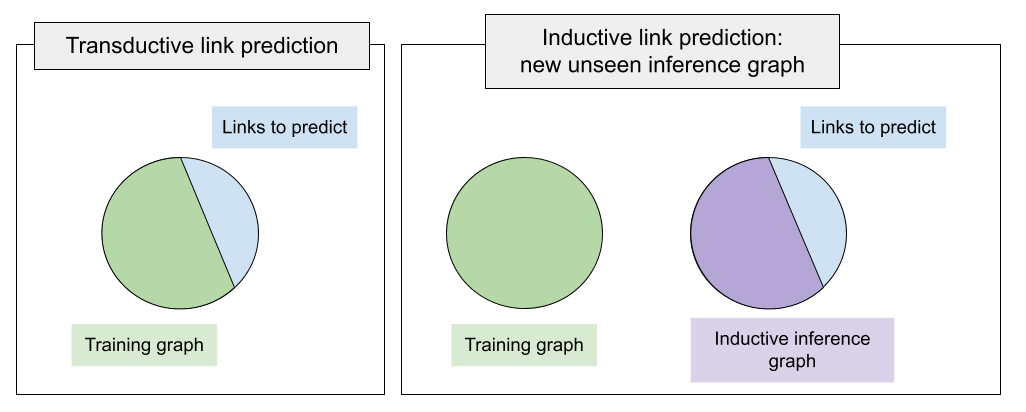
While in transductive link prediction, the training and inference graph are the same (and therefore contain the same entities), in inductive link prediction, there is a disjoint inference graph that potentially contains new, unseen entities.
For this challenge, we sampled two datasets from Wikidata,
the largest publicly available and open KG. Inductive link prediction implies
training a model on one graph (denoted as training) and performing inference,
eg, validation and test, over a new graph (denoted as inference).
Dataset creation principles:
- Represents a real-world KG used in many NLP and ML tasks (Wikidata)
- Larger than existing benchmarks
- Allows for fast iteration and hypothesis testing - we sampled two datasets, small and large, that vary in sizes of training and inference graphs.
- The ratio of training / inference graph sizes is challenging for modern GNNs.
- Training graph is a connected component
- Inference graph is a connected component
Both the small and large variants of the dataset can be found in the
data folder of this repository. Each contains four splits
corresponding to the diagram:
train.txt- the training graph on which you are supposed to train a modelinference.txt- the inductive inference graph disjoint with the training one - that is, it has a new non-overlapping set of entities, the missing links are sampled from this graphinductive_validation.txt- validation set of triples to predict, uses entities from the inference graphinductive_test.txt- test set of triples to predict, uses entities from the inference graph- a hold-out test set of triples - kept by the organizers for the final ranking 😉 , uses entities from the inference graph
| Split | Entities | Relations | Triples |
|---|---|---|---|
| Train | 10,230 | 96 | 78,616 |
| Inference | 6,653 | 96 (subset) | 20,960 |
| Inference validation | 6,653 | 96 (subset) | 2,908 |
| Inference test | 6,653 | 96 (subset) | 2,902 |
| Hold-out test set | 6,653 | 96 (subset) | 2,894 |
| Split | Entities | Relations | Triples |
|---|---|---|---|
| Train | 46,626 | 130 | 202,446 |
| Inference | 29,246 | 130 (subset) | 77,044 |
| Inference validation | 29,246 | 130 (subset) | 10,179 |
| Inference test | 29,246 | 130 (subset) | 10,184 |
| Hold-out test set | 29,246 | 130 (subset) | 10,172 |
The Challenge aims to streamline community efforts in the emerging area of representation learning techniques beyond shallow entity embeddings. We invite submissions proposing new inductive models as well as extending baseline models to achieve higher performance.
We use the following rank-based evaluation metrics:
- MRR (Inverse Harmonic Mean Rank) - higher is better, range
[0, 1] - Hits @ K (H@K; with K as one of
{1, 3, 5, 10, 100}) - higher is better, range[0, 1] - AMRI (Adjusted Arithmetic Mean Rank Index) - higher is better, compares model scoring
against random scoring, range
[-1, 1]. AMRI=0 means the model is not better than random scoring.
Making a submission:
- Fork the repo
- Train your inductive link prediction model
- Save the model weights using the
--saveflag - Upload model weights on GitHub or other platforms (Dropbox, Google Drive, etc)
- Open an issue in this repo with the link to your repo, performance metrics, and model weights
We provide an example workflow in main.py for training and
evaluating two variants of the NodePiece
model using PyKEEN:
InductiveNodePiece- plain tokenizer + tokens MLP encoder to bootstrap node representations. Fast.InductiveNodePieceGNN- everything above + an additional 2-layer CompGCN message passing encoder. Slower but performs better.
The example can be run with python main.py and the options can be listed
with python main.py --help.
Installation Instructions
Main requirements:
- python >= 3.9
- torch >= 1.10
You will need PyKEEN 1.8.0 or newer.
$ pip install pykeenBy the time of creation of this repo 1.8.0 is not yet there, but the latest version from sources contains everything we need
$ pip install git+https://github.com/pykeen/pykeen.gitIf you plan to use GNNs (including the InductiveNodePieceGNN baseline) make
sure you install torch-scatter
and torch-geometric
compatible with your python, torch, and CUDA versions.
Running the code on a GPU is strongly recommended.
We report the performance of both variants of the NodePiece model on the small variant of the dataset after running the following:
- InductiveNodePieceGNN (32d, 50 epochs, 24K params) - NodePiece (5 tokens per
node, MLP aggregator) + 2-layer CompGCN with DistMult composition function +
DistMult decoder. Training time: 77 min*
$ python main.py --dataset small -d 32 -e 50 -n 16 -m 2.0 -lr 0.0001 --gnn
- InductiveNodePiece (32d, 50 epochs, 15.5K params) - NodePiece (5 tokens per
node, MLP aggregator) + DistMult decoder. Training time: 6 min*
$ python main.py --dataset small -d 32 -e 50 -n 16 -m 5.0 -lr 0.0001
| Model | MRR | H@100 | H@10 | H@5 | H@3 | H@1 | AMRI |
|---|---|---|---|---|---|---|---|
| InductiveNodePieceGNN | 0.1326 | 0.4705 | 0.2509 | 0.1899 | 0.1396 | 0.0763 | 0.730 |
| InductiveNodePiece | 0.0381 | 0.4678 | 0.0917 | 0.0500 | 0.0219 | 0.007 | 0.666 |
We report the performance of both variants of the NodePiece model on the large variant of the dataset after running the following:
- InductiveNodePieceGNN (32d, 53 epochs, 24K params) - NodePiece (5 tokens per
node, MLP aggregator) + 2-layer CompGCN with DistMult composition function +
DistMult decoder. Training time: 8 hours*
$ python main.py --dataset large -d 32 -e 53 -n 16 -m 20.0 -lr 0.0001 --gnn
- InductiveNodePiece (32d, 17 epochs, 15.5K params) - NodePiece (5 tokens per
node, MLP aggregator) + DistMult decoder. Training time: 5 min*
$ python main.py --dataset large -d 32 -e 17 -n 16 -m 15.0 -lr 0.0001
| Model | MRR | H@100 | H@10 | H@5 | H@3 | H@1 | AMRI |
|---|---|---|---|---|---|---|---|
| InductiveNodePieceGNN | 0.0705 | 0.374 | 0.1458 | 0.0990 | 0.0730 | 0.0319 | 0.682 |
| InductiveNodePiece | 0.0651 | 0.287 | 0.1246 | 0.0809 | 0.0542 | 0.0373 | 0.646 |
* Note: All models were trained on a single RTX 8000. Average memory
consumption during training is about 2 GB VRAM on the small dataset and about
3 GB on large.
The code in this package is licensed under the MIT License. The datasets in this repository are licensed under the Creative Commons Zero license. The trained models and their weights are licensed under the Creative Commons Zero license.
If you use the ILPC'22 datasets in your work, please cite the following:
@article{Galkin2022,
archivePrefix = {arXiv},
arxivId = {2203.01520},
author = {Galkin, Mikhail and Berrendorf, Max and Hoyt, Charles Tapley},
eprint = {2203.01520},
month = {mar},
title = {{An Open Challenge for Inductive Link Prediction on Knowledge Graphs}},
url = {http://arxiv.org/abs/2203.01520},
year = {2022}
}This project has been supported by several organizations (in alphabetical order):
- Harvard Program in Therapeutic Science - Laboratory of Systems Pharmacology
- Ludwig-Maximilians-Universität München
- Mila
- Munich Center for Machine Learning (MCML)
This project has been funded by the following grants:
| Funding Body | Program | Grant |
|---|---|---|
| DARPA | Young Faculty Award (PI: Benjamin Gyori) | W911NF2010255 |
| German Federal Ministry of Education and Research (BMBF) | Munich Center for Machine Learning (MCML) | 01IS18036A |
| Samsung | Samsung AI Grant | - |