TypeError: '<' not supported between instances of 'Example' and 'Example' #474
Comments
|
should work here or you can use a regular |
|
I had the same problem with TabularDataset too |
|
thanks @cheryllwl , this should be documented properly. |
|
@tu-artem Can you please elaborate on what adding the index [0] does? |
|
@kunjmehta in your case you are already doing tuple unpacking via multiple assignment |
|
What worked for me was to simply add |
This worked for me too. I added |
|
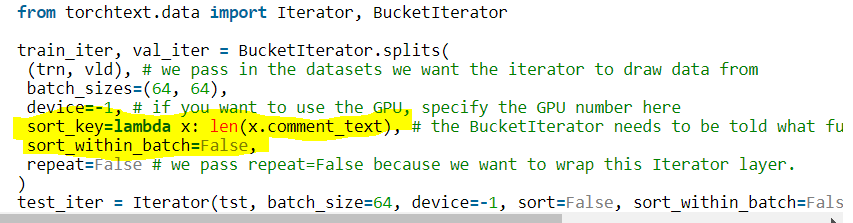
i solved this by add sort=False parameter.
|
…device must be imported first) and added 'sort=False' to the BucketIterator.splits() command to prevent: pytorch/text#474
Got the error when running the following code. Is there anything similar to an operator overloading for "<" needed here, or there is a go around way here?
from torchtext.data import TabularDataset
from torchtext import data
from torchtext.vocab import GloVe
from torchtext.vocab import GloVe
tv_datafields = [("id", None), # we won't be needing the id, so we pass in None as the field
("question_text", TEXT),
("target", LABEL)]
trn = TabularDataset.splits(
path="data/quora", # the root directory where the data lies
train='train.csv',
format='csv',
skip_header=True, # if your csv header has a header, make sure to pass this to ensure it doesn't get proceesed as data!
fields=tv_datafields)
TEXT.build_vocab(trn, vectors=GloVe(name='6B', dim=300))
The text was updated successfully, but these errors were encountered: