NEW Feature: Mixup transform for Object Detection #6721
Conversation
|
Hey @ambujpawar and thanks a lot for the PR! I'll try to help you land it in the near future. As you might have noticed, this transform is not straight forward to implement since it requires a batch of detection samples. In this context this means a list of samples, whereas for classification "batch" usually means an extra batch dimension on a tensor. This makes this implementation a lot harder compared to regular Still, we need to be able to support it. I'll look into how we can streamline the process for example by providing a |
|
Hi @pmeier, it sounds perfect to me. Looking forward to your suggestions :) I agree with your comment regarding MixupforDetection taking batches of detection samples. However, shouldn't it be similar to what we do in CopyPaste transform? Because in copyPaste we also expect a batch of images |
Exactly. Before we operated under the assumption that Right now the largest part of the implementation deals with the "infrastructure", i.e. extracting the right inputs and putting them back afterwards. Only a small part is spent on the actual algorithm. In a best case scenario, I find a solution so you can only write the algorithm and the remainder is handled by a base class or some high level utilities. |
|
That clears up all the questions for me. Thanks! Yeah, a base class is perhaps the best solution in those regards. Please let me know if I my help is needed :) |
There was a problem hiding this comment.
@ambujpawar I took the liberty of pushing a patch to your PR. I've added two functions flatten_and_extract as well as unflatten_and_insert that implement what their name implies. I'm actively looking for your feedback so nothing is fixed yet. Two things that I already noticed:
- Both
SimpleCopyPasteas wellMixUpDetectionuse a "split" layout for images and targets. Is that by design or could we use one container like a dictionary for both of them. Imagine something likesample = {"image": ..., "boxes": ...}. - The old extraction and insertion logic converted to tensor and back for images and (un-)wrapped the other features. Right now, the new logic does not do this. Instead this is moved inside the
_mixupfunction. We could move that back into the logic as well. What do you prefer?
|
Thanks for adding the patch! :) I think it looks nice. Regarding your questions:
Yes, they both use a "split" design, but Mixup Detection but Mixup does not use "Masks". Mixup is only used for Detection not Segmentation.
If I had to choose one design, I would chose the former design but I dont have any strong arguments for it. Shall we also include the developers of SimpleCopyPaste transform as well? They might also have some comments regarding these changes |
There was a problem hiding this comment.
This is based on the example listed in the blogpost rergarding Transforms v2.
How should we call this transform instead?
Well, MixupDetection as well as SimpleCopyPaste are detection batch transforms and thus fall outside of the "regular" transforms. This is why we need so extra stuff to implement them properly. If you look at the other, their implementation is much simpler.
Batch transform here means that the input needs to be batched. For image classification transforms like CutMix or MixUp this simply means an extra batch dimension on the input tensors:
vision/torchvision/prototype/transforms/_augment.py
Lines 135 to 136 in 657c076
However, this is not possible for detection tasks. Each sample can have a different number of bounding boxes and thus we cannot put them into a single tensor. Hence, a "detection batch" is just a sequence of individual samples. For you example, this could be
batch = [(img, bbox_1, label), (img2, bbox_2, label)]
transformed_batch = trans(batch)Of course you can also do
batch = [{"image": img, "boxes": bbox_1, "label": label}, ...]or something else as long as the outer container is a sequence.
Figured out SimpleCopyPaste still doesn't work. Working on it
You don't have to. Let's make sure DetectionMixup works as we want it to, and I'll fix SimpleCopyPaste afterwards.
Let's make sure we expand the tests a little. Basically we should have three test cases:
- a) and b) Make sure that
_mixupis a no-op in case the ratio is== 0or>= 1.0. - Make sure that we get the correct output for a different ratio, e.g.
== 0.5. Right now, we are only doing a smoke test that checks the shapes.
I think when that is done, I can take over and fix the rest.
test/test_prototype_transforms.py
Outdated
| @@ -1436,63 +1437,6 @@ def create_fake_image(self, mocker, image_type): | |||
| return PIL.Image.new("RGB", (32, 32), 123) | |||
| return mocker.MagicMock(spec=image_type) | |||
|
|
|||
| def test__extract_image_targets_assertion(self, mocker): | |||
There was a problem hiding this comment.
I was using it to test _extract_image_targets function. However, since we removed those functions I removed them from here as well
There was a problem hiding this comment.
Oh sorry! Realized this was for TestSimpleCopyPaste. Undoing the changes, sorry
| def _get_params(self, flat_inputs: List[Any]) -> Dict[str, Any]: | ||
| return dict(ratio=float(self._dist.sample())) |
There was a problem hiding this comment.
I've opted to sample the ratio in the _get_params method. This has two advantages:
- People familiar with the other transforms can see at a glance that we are sampling something and this is not buried deep in the implementation.
_mixupis easier to test since it has no random behavior.
There was a problem hiding this comment.
I agree, it looks much tidier this way!
However, I have a question: we dont use flat_inputs? Shall we just remove it?
There was a problem hiding this comment.
I would keep it for consistency with the other transformations. This is the basic protocol for all Transform._get_params calls. Although we call it manually here, there is some benefit by aligning it. Someone not familiar with this transform, but the others in general might trip over the fact that the parameter is not there.
There was a problem hiding this comment.
I just realized we are actually not passing anything here. Let's just pass the flat inputs for completeness.
|
Hey @ambujpawar 👋 I hope you are all right. I wanted to check in on this PR. Are you planning on finishing it or should I take over? |
|
Hi @pmeier, thanks for asking! I'm doing good :) just back from a super long christmas and new year vacation so did not have time to work on this PR. I would still like to work on if we are not running on a deadline or something. I can work on it this weekend and can request you for re-review :) |
|
No rush from my side. I thought I check on you after roughly one month of inactivity. In case you didn't plan to finish this, we still would like to have it and I would have taken over. This weekend sounds good. |
|
Thanks! I'll update the PR this weekend then! :) |
Co-authored-by: Philip Meier <github.pmeier@posteo.de>
|
Hi, I added the test cases for when the ratios for mixup are 0 and 1. However, I still think there is some bug when we are mixing the two images. I am not able to exactly point what causes it though. Perhaps after looking at the code something rings a bell for you. So, this is the expected output (or something similar). Notice the light appearance of cat in the background However, after our latest changes it look like this. Notice the picture of cat is completely overwriting the picture of dog. I am not exactly sure but I suspect something is going wrong when we are mixing images in |


Yup, the problem is that we replace the values in the first image with the ones from the second rather than adding them. To demonstrate, let's establish a visual benchmark first that we both can easily reproduce: import PIL.Image
import torch
from torchvision.io import read_image
from torchvision.prototype import datapoints, transforms
from torchvision.utils import make_grid
def read_sample(path, label):
image = datapoints.Image(read_image(path))
bounding_box = datapoints.BoundingBox(
[[0, 0, *image.spatial_size[::-1]]], format="xyxy", spatial_size=image.spatial_size
)
label = datapoints.Label([label])
return dict(
path=path,
image=image,
bounding_box=bounding_box,
label=label,
)
batch = [
read_sample("test/assets/encode_jpeg/grace_hopper_517x606.jpg", 0),
read_sample("test/assets/fakedata/logos/rgb_pytorch.png", 1),
]
transform = transforms.MixupDetection()
torch.manual_seed(0)
output = transform(batch)
image = make_grid([sample["image"] for sample in output])
PIL.Image.fromarray(image.permute(1, 2, 0).numpy()).save("mixup_detection.jpg")Output with the current implementation is
So, in the left image, the PyTorch logo is the second image and thus we are just pasting it over Grace Hopper. On the right side the PyTorch logo is completely gone, since Grace Hopper is larger and thus completely paints over it. Applying the first suggestion from below gives us
And thus the behavior we want. |


|
I'm working on fixing |
Co-authored-by: Philip Meier <github.pmeier@posteo.de>
Yup, exactly! This is the behavior we want. |
…war/vision into 6720_add_mixup_transform
|
I've pushed an update to |
Nope. I think everything is done on my side and this mixupDetection feature is ready. :) |
|
Yes, unfortunately we are blocked by this. Sorry for not informing your earlier. We held off the batch transforms for now for the reason you listed above. I'll ping you here when we have figured it out. Thanks a lot for your patience! |
|
Ah sure! No worries |
Official implementation of the paper: Here
Minimalist code to reproduce:
Examples output:
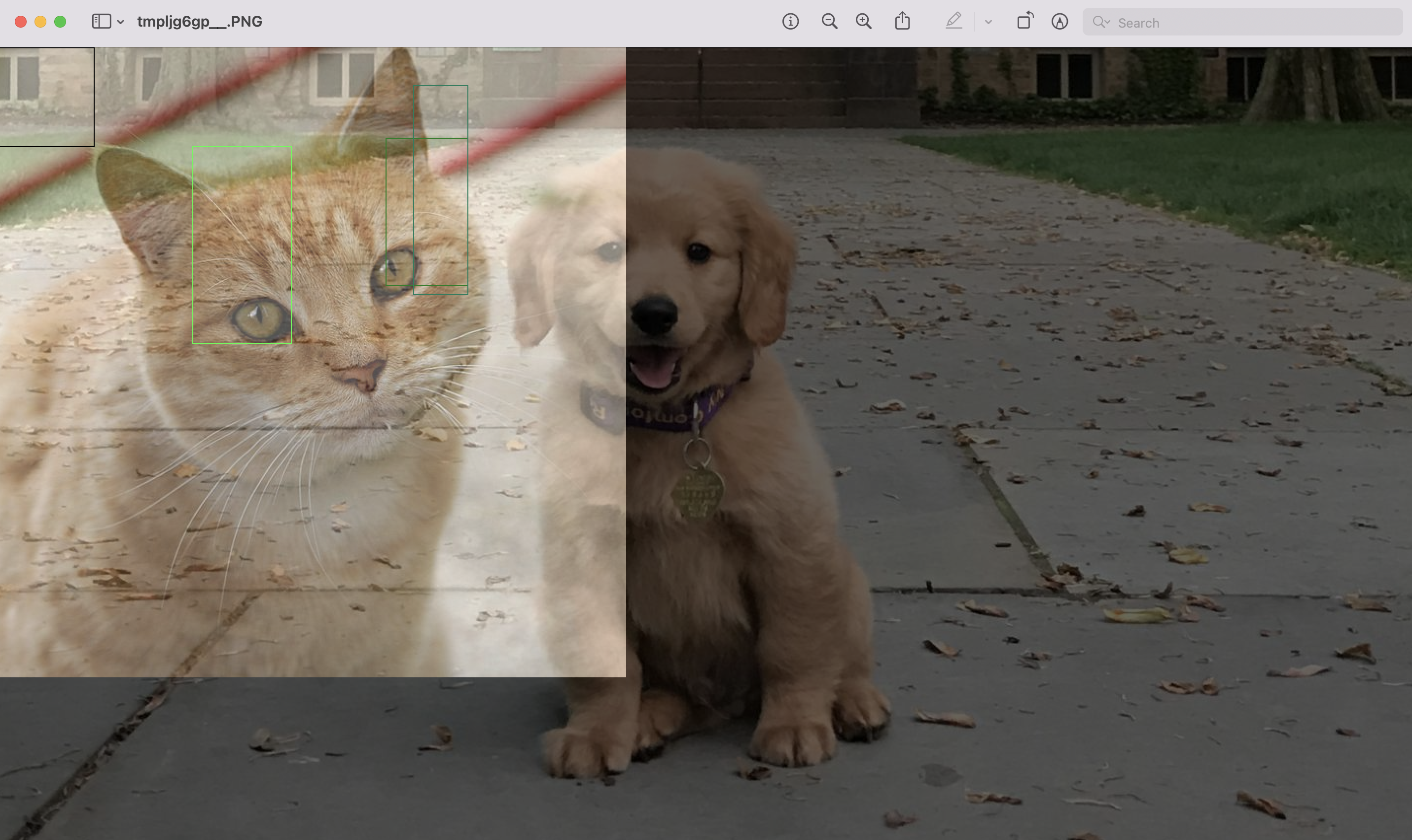
Please dont pay attention to bounding boxes in this particular image.
I just entered those boxes randomly