本脚本是海豚/毒蛇的rss脚本
支持在rss时自动根据种子体积范围来智能使用令牌
本脚本仅支持python3,所以你首先需要安装一个python3的环境,这个怎么搞自行上网搜索,正确安装在之后你打开命令行输入
python3 --version
之后应该能看到python安装的版本信息
之后安装本程序依赖的包(win用户/root用户省略sudo):
sudo pip3 install bencode.py requests
如果没有root权限,可以使用--user:
pip3 install bencode.py requests --user
或者使用virtualenv等手段(请自行上网查阅)
然后下载本脚本:
git clone https://github.com/qfishpear/fishrss_simple.git
cd fishrss_simple
首先你需要将config.py.example复制一份为config.py
cp config.py.example config.py
然后按照config.py里面的提示填写,并创建好所有已填写的文件/文件夹。
所有路径可以填写相对路径,但是如果要crontab等方式运行,填写绝对路径更为保险
填写路径的时候,即使是Windows,依然建议使用左斜杠/而非右斜杠\作为路径的分隔符,除非你知道自己在写什么。
怎么找到网站上的cookie有多种方式,这里推荐一个chrome插件editthiscookie
https://chrome.google.com/webstore/detail/editthiscookie/fngmhnnpilhplaeedifhccceomclgfbg?hl=zh-CN
安装完此插件之后,打开任意海豚的网页,点击editthiscookie的图标,然后按照下图方式复制cookie
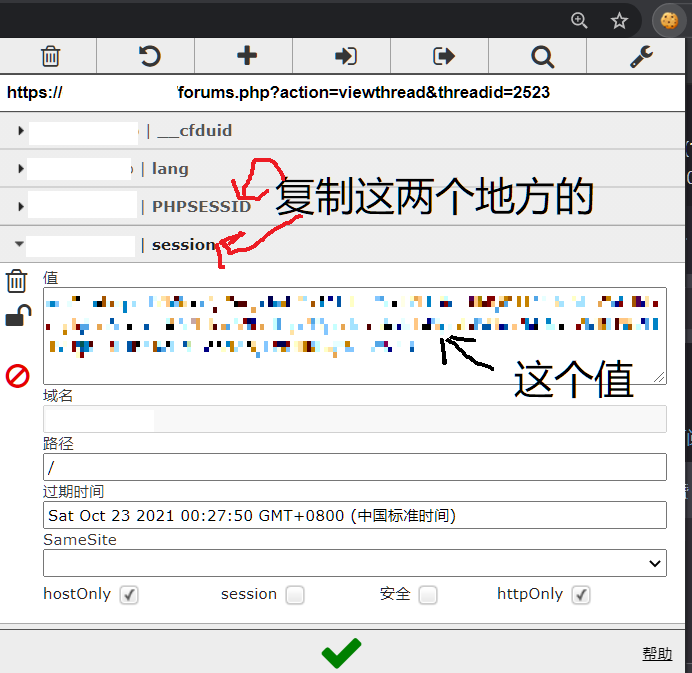
这个你去网站里复制任意一个下载链接DL即可,里面有
以海豚为例,第一次运行时,请运行
python3 rss.py --site dic --init
--init会只记录r过的种子链接,而不将其保存在watch/文件夹里
之后每次运行
python3 rss.py --site dic
如果要r毒蛇,请对应改成--site snake
隐私已去除
2021-05-01 16:06:01,246 - INFO - directory automatically created: ./watch
2021-05-01 16:06:01,246 - INFO - file automatically created: ./downloaded_urls.txt
2021-05-01 16:06:01,251 - INFO - Starting new HTTPS connection (1): xxxxxxxx.xxxx
2021-05-01 16:06:01,523 - INFO - 50 torrents in rss result
2021-04-13 10:38:28,475 - INFO - download https://xxxxxxxx.xxxx/torrents.php?action=download&id=49132&authkey=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx&torrent_pass=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
2021-04-13 10:38:28,476 - INFO - Starting new HTTPS connection (1): xxxxxxxx.xxxx
2021-04-13 10:38:29,563 - INFO - hash=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
2021-04-13 10:38:29,565 - INFO - download https://xxxxxxxx.xxxx/torrents.php?action=download&id=49131&authkey=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx&torrent_pass=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
2021-04-13 10:38:29,566 - INFO - Starting new HTTPS connection (1): xxxxxxxx.xxxx
2021-04-13 10:38:30,631 - INFO - hash=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
2021-04-13 10:38:30,632 - INFO - download https://xxxxxxxx.xxxx/torrents.php?action=download&id=49130&authkey=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx&torrent_pass=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
2021-04-13 10:38:32,073 - INFO - 3 torrents added
此时watch文件夹里有:
fishpear@sea:~/rss/tmp/watch$ ls
Proc Fiskal - Lothian Buses (2021) [24B-44.1Khz].torrent
Raphael Saadiq - The Way I See It.torrent
Taylor Swift - Fearless - Taylor's Version (2021) {Target Limited Edition} [FLAC].torrent
downloaded_urls.txt里有(隐私已略去):
fishpear@sea:~/rss/tmp$ cat downloaded_urls.txt
downloaded urls:
https://xxxxxxxx.xxxx/torrents.php?action=download&id=49132&authkey=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx&torrent_pass=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
https://xxxxxxxx.xxxx/torrents.php?action=download&id=49131&authkey=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx&torrent_pass=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
https://xxxxxxxx.xxxx/torrents.php?action=download&id=49130&authkey=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx&torrent_pass=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
首先老生常谈crontab显然是可以用的,用法自己查,但是坏处就是只能精确到分钟。
那我想每30秒r一次怎么搞呢? 其实linux有个很简单的命令:watch,以下命令表示30秒运行一次
watch -n 30 python3 rss.py --site dic
注意,你这个时间间隔不能设的太小不然没有意义,因为服务器本身就很卡请爱护服务器,另外api的话有2秒一次的限制不能高于这个限制不然会被z酱打屁股(大雾)。