大家好,窝又来写文章了,咱们现在在这篇文章中,我们来对其官方的一些非常常用的API进行学习。所谓工欲善其事,必先利其器。想要好好学习FRIDA我们就必须对FRIDA API深入的学习以对其有更深的了解和使用,通常大部分核心原理也在官方API中写着,我们学会来使用一些案例来结合API的使用。
注意,运行以下任何代码时都需要提前启动手机中的frida-server文件。
不论是什么语言都好,第一个要学习总是如何输出和打印,那我们就来学习在FRIDA打印值。在官方API有两种打印的方式,分别是console、send,我们先来学习非常的简单的console,这里我创建一个js文件,代码示例如下。
function hello_printf() {
Java.perform(function () {
console.log("");
console.log("hello-log");
console.warn("hello-warn");
console.error("hello-error");
});
}
setImmediate(hello_printf,0);当文件创建好之后,我们需要运行在手机中安装的frida-server文件,在上一章我们学过了如何安装在android手机安装frida-server,现在来使用它,我们在ubuntu中开启一个终端,运行以下代码,启动我们安装好的frida-server文件。
roysue@ubuntu:~$ adb shell
sailfish:/ $ su
sailfish:/ $ ./data/local/tmp/frida-server
然后执行以下代码,对目标应用app的进程com.roysue.roysueapplication使用-l命令注入Chap03.js中的代码1-1以及执行脚本之后的效果图1-1!frida -U com.roysue.roysueapplication -l Chap03.js
代码1-1 代码示例
图1-1 终端执行
可以到终点已经成功注入了脚本并且打印了hello,但是颜色不同,这是log的级别的原因,在FRIDA的console中有三个级别分别是log、warn、error。

| 级别 | 含义 |
|---|---|
| log | 正常 |
| warn | 警告 |
| error | 错误 |
error级别最为严重其次warn,但是一般在使用中我们只会使用log来输出想看的值;然后我们继续学习console的好兄弟,hexdump,其含义:打印内存中的地址,target参数可以是ArrayBuffer或者NativePointer,而options参数则是自定义输出格式可以填这几个参数offset、lengt、header、ansi。hexdump代码示例以及执行效果如下。
var libc = Module.findBaseAddress('libc.so');
console.log(hexdump(libc, {
offset: 0,
length: 64,
header: true,
ansi: true
}));
0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF
00000000 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00 .ELF............
00000010 03 00 28 00 01 00 00 00 00 00 00 00 34 00 00 00 ..(.........4...
00000020 34 a8 04 00 00 00 00 05 34 00 20 00 08 00 28 00 4.......4. ...(.
00000030 1e 00 1d 00 06 00 00 00 34 00 00 00 34 00 00 00 ........4...4...
send是在python层定义的on_message回调函数,jscode内所有的信息都被监控script.on('message', on_message),当输出信息的时候on_message函数会拿到其数据再通过format转换, 其最重要的功能也是最核心的是能够直接将数据以json格式输出,当然数据是二进制的时候也依然是可以使用send,十分方便,我们来看代码1-2示例以及执行效果。
# -*- coding: utf-8 -*-
import frida
import sys
def on_message(message, data):
if message['type'] == 'send':
print("[*] {0}".format(message['payload']))
else:
print(message)
jscode = """
Java.perform(function ()
{
var jni_env = Java.vm.getEnv();
console.log(jni_env);
send(jni_env);
});
"""
process = frida.get_usb_device().attach('com.roysue.roysueapplication')
script = process.create_script(jscode)
script.on('message', on_message)
script.load()
sys.stdin.read()
运行脚本效果如下:
roysue@ubuntu:~/Desktop/Chap09$ python Chap03.py
[object Object]
[*] {'handle': '0xdf4f8000', 'vm': {}}可以看出这里两种方式输出的不同的效果,console直接输出了[object Object],无法输出其正常的内容,因为jni_env实际上是一个对象,但是使用send的时候会自动将对象转json格式输出。通过对比,我们就知道send的好处啦~
学完输出之后我们来学习如何声明变量类型。
| API | 含义 |
|---|---|
| new Int64(v) | 定义一个有符号Int64类型的变量值为v,参数v可以是字符串或者以0x开头的的十六进制值 |
| new UInt64(v) | 定义一个无符号Int64类型的变量值为v,参数v可以是字符串或者以0x开头的的十六进制值 |
| new NativePointer(s) | 定义一个指针,指针地址为s |
| ptr(“0”) | 同上 |
代码示例以及效果
Java.perform(function () {
console.log("");
console.log("new Int64(1):"+new Int64(1));
console.log("new UInt64(1):"+new UInt64(1));
console.log("new NativePointer(0xEC644071):"+new NativePointer(0xEC644071));
console.log("new ptr('0xEC644071'):"+new ptr(0xEC644071));
});
输出效果如下:
new Int64(1):1
new UInt64(1):1
new NativePointer(0xEC644071):0xec644071
new ptr('0xEC644071'):0xec644071frida也为Int64(v)提供了一些相关的API:
| API | 含义 |
|---|---|
| add(rhs)、sub(rhs)、and(rhs)、or(rhs)、xor(rhs) | 加、减、逻辑运算 |
| shr(N)、shl(n) | 向右/向左移位n位生成新的Int64 |
| Compare(Rhs) | 返回整数比较结果 |
| toNumber() | 转换为数字 |
| toString([radix=10]) | 转换为可选基数的字符串(默认为10) |
我也写了一些使用案例,代码如下。
function hello_type() {
Java.perform(function () {
console.log("");
//8888 + 1 = 8889
console.log("8888 + 1:"+new Int64("8888").add(1));
//8888 - 1 = 8887
console.log("8888 - 1:"+new Int64("8888").sub(1));
//8888 << 1 = 4444
console.log("8888 << 1:"+new Int64("8888").shr(1));
//8888 == 22 = 1 1是false
console.log("8888 == 22:"+new Int64("8888").compare(22));
//转string
console.log("8888 toString:"+new Int64("8888").toString());
});
}代码执行效果如图1-2。
图1-2 Int64 API

可以替换或插入的空对象,以向应用程序公开RPC样式的API。该键指定方法名称,该值是导出的函数。此函数可以返回一个纯值以立即返回给调用方,或者承诺异步返回。也就是说可以通过rpc的导出的功能使用在python层,使python层与js交互,官方示例代码有Node.js版本与python版本,我们在这里使用python版本,代码如下。
import frida
def on_message(message, data):
if message['type'] == 'send':
print(message['payload'])
elif message['type'] == 'error':
print(message['stack'])
session = frida.get_usb_device().attach('com.roysue.roysueapplication')
source = """
rpc.exports = {
add: function (a, b) {
return a + b;
},
sub: function (a, b) {
return new Promise(function (resolve) {
setTimeout(function () {
resolve(a - b);
}, 100);
});
}
};
"""
script = session.create_script(source)
script.on('message', on_message)
script.load()
print(script.exports.add(2, 3))
print(script.exports.sub(5, 3))
session.detach()官方源码示例是附加在目标进程为iTunes,再通过将rpc的./agent.js文件读取到source,进行使用。我这里修改了附加的目标的进程以及直接将rpc的代码定义在source中。我们来看看这段是咋运行的,仍然先对目标进程附加,然后在写js中代码,也是source变量,通过rpc.exports关键字定义需要导出的两个函数,上面定义了add函数和sub函数,两个的函数写作方式不一样,大家以后写按照add方法写就好了,sub稍微有点复杂。声明完函数之后创建了一个脚本并且注入进程,加载了脚本之后可以到print(script.exports.add(2, 3))以及print(script.exports.sub(5, 3)),在python层直接调用。add的返回的结果为5,sub则是2,下见下图1-3。
图1-3 执行python脚本

我们现在来介绍以及使用一些Process对象中比较常用的api~
Process.id:返回附加目标进程的PID
Process.isDebuggerAttached():检测当前是否对目标程序已经附加
枚举当前加载的模块,返回模块对象的数组。Process.enumerateModules()会枚举当前所有已加载的so模块,并且返回了数组Module对象,Module对象下一节我们来详细说,在这里我们暂时只使用Module对象的name属性。
function frida_Process() {
Java.perform(function () {
var process_Obj_Module_Arr = Process.enumerateModules();
for(var i = 0; i < process_Obj_Module_Arr.length; i++) {
console.log("",process_Obj_Module_Arr[i].name);
}
});
}
setImmediate(frida_Process,0);我来们开看看这段js代码写了啥:在js中能够直接使用Process对象的所有api,调用了Process.enumerateModules()方法之后会返回一个数组,数组中存储N个叫Module的对象,既然已经知道返回了的是一个数组,很简单我们就来for循环它便是,这里我使用下标的方式调用了Module对象的name属性,name是so模块的名称。见下图1-4。
图1-4 终端输出了所有已加载的so

Process.enumerateThreads():枚举当前所有的线程,返回包含以下属性的对象数组:
| 属性 | 含义 |
|---|---|
| id | 线程id |
| state | 当前运行状态有running, stopped, waiting, uninterruptible or halted |
| context | 带有键pc和sp的对象,它们是分别为ia32/x64/arm指定EIP/RIP/PC和ESP/RSP/SP的NativePointer对象。也可以使用其他处理器特定的密钥,例如eax、rax、r0、x0等。 |
使用代码示例如下:
function frida_Process() {
Java.perform(function () {
var enumerateThreads = Process.enumerateThreads();
for(var i = 0; i < enumerateThreads.length; i++) {
console.log("");
console.log("id:",enumerateThreads[i].id);
console.log("state:",enumerateThreads[i].state);
console.log("context:",JSON.stringify(enumerateThreads[i].context));
}
});
}
setImmediate(frida_Process,0);获取当前是所有线程之后返回了一个数组,然后循环输出它的值,如下图1-5。
图1-4 终端执行

Process.getCurrentThreadId():获取此线程的操作系统特定 ID 作为数字
3.4章节中Process.EnumererateModules()方法返回了就是一个Module对象,咱们这里来详细说说Module对象,先来瞧瞧它都有哪些属性。
| 属性 | 含义 |
|---|---|
| name | 模块名称 |
| base | 模块地址,其变量类型为NativePointer |
| size | 大小 |
| path | 完整文件系统路径 |
除了属性我们再来看看它有什么方法。
| API | 含义 |
|---|---|
| Module.load() | 加载指定so文件,返回一个Module对象 |
| enumerateImports() | 枚举所有Import库函数,返回Module数组对象 |
| enumerateExports() | 枚举所有Export库函数,返回Module数组对象 |
| enumerateSymbols() | 枚举所有Symbol库函数,返回Module数组对象 |
| Module.findExportByName(exportName)、Module.getExportByName(exportName) | 寻找指定so中export库中的函数地址 |
| Module.findBaseAddress(name)、Module.getBaseAddress(name) | 返回so的基地址 |
在frida-12-5版本中更新了该API,主要用于加载指定so文件,返回一个Module对象。
使用代码示例如下:
function frida_Module() {
Java.perform(function () {
//参数为so的名称 返回一个Module对象
const hooks = Module.load('libhello.so');
//输出
console.log("模块名称:",hooks.name);
console.log("模块地址:",hooks.base);
console.log("大小:",hooks.size);
console.log("文件系统路径",hooks.path);
});
}
setImmediate(frida_Module,0);
输出如下:
模块名称: libhello.so
模块地址: 0xdf2d3000
大小: 24576
文件系统路径 /data/app/com.roysue.roysueapplication-7adQZoYIyp5t3G5Ef5wevQ==/lib/arm/libhello.so咱们这一小章节就来使用Module对象,把上章的Process.EnumererateModules()对象输出给它补全了,代码如下。
function frida_Module() {
Java.perform(function () {
var process_Obj_Module_Arr = Process.enumerateModules();
for(var i = 0; i < process_Obj_Module_Arr.length; i++) {
if(process_Obj_Module_Arr[i].path.indexOf("hello")!=-1)
{
console.log("模块名称:",process_Obj_Module_Arr[i].name);
console.log("模块地址:",process_Obj_Module_Arr[i].base);
console.log("大小:",process_Obj_Module_Arr[i].size);
console.log("文件系统路径",process_Obj_Module_Arr[i].path);
}
}
});
}
setImmediate(frida_Module,0);
输出如下:
模块名称: libhello.so
模块地址: 0xdf2d3000
大小: 24576
文件系统路径 /data/app/com.roysue.roysueapplication-7adQZoYIyp5t3G5Ef5wevQ==/lib/arm/libhello.so这边如果去除判断的话会打印所有加载的so的信息,这里我们就知道了哪些方法返回了Module对象了,然后我们再继续深入学习Module对象自带的API。
该API会枚举模块中所有中的所有Import函数,示例代码如下。
function frida_Module() {
Java.perform(function () {
const hooks = Module.load('libhello.so');
var Imports = hooks.enumerateImports();
for(var i = 0; i < Imports.length; i++) {
//函数类型
console.log("type:",Imports[i].type);
//函数名称
console.log("name:",Imports[i].name);
//属于的模块
console.log("module:",Imports[i].module);
//函数地址
console.log("address:",Imports[i].address);
}
});
}
setImmediate(frida_Module,0);
输出如下:
[Google Pixel::com.roysue.roysueapplication]-> type: function
name: __cxa_atexit
module: /system/lib/libc.so
address: 0xf58f4521
type: function
name: __cxa_finalize
module: /system/lib/libc.so
address: 0xf58f462d
type: function
name: __stack_chk_fail
module: /system/lib/libc.so
address: 0xf58e2681
...该API会枚举模块中所有中的所有Export函数,示例代码如下。
function frida_Module() {
Java.perform(function () {
const hooks = Module.load('libhello.so');
var Exports = hooks.enumerateExports();
for(var i = 0; i < Exports.length; i++) {
//函数类型
console.log("type:",Exports[i].type);
//函数名称
console.log("name:",Exports[i].name);
//函数地址
console.log("address:",Exports[i].address);
}
});
}
setImmediate(frida_Module,0);
输出如下:
[Google Pixel::com.roysue.roysueapplication]-> type: function
name: Java_com_roysue_roysueapplication_hellojni_getSum
address: 0xdf2d411b
type: function
name: unw_save_vfp_as_X
address: 0xdf2d4c43
type: function
address: 0xdf2d4209
type: function
...代码示例如下。
function frida_Module() {
Java.perform(function () {
const hooks = Module.load('libc.so');
var Symbol = hooks.enumerateSymbols();
for(var i = 0; i < Symbol.length; i++) {
console.log("isGlobal:",Symbol[i].isGlobal);
console.log("type:",Symbol[i].type);
console.log("section:",JSON.stringify(Symbol[i].section));
console.log("name:",Symbol[i].name);
console.log("address:",Symbol[i].address);
}
});
}
setImmediate(frida_Module,0);
输出如下:
isGlobal: true
type: function
section: {"id":"13.text","protection":"r-x"}
name: _Unwind_GetRegionStart
address: 0xf591c798
isGlobal: true
type: function
section: {"id":"13.text","protection":"r-x"}
name: _Unwind_GetTextRelBase
address: 0xf591c7cc
...返回so文件中Export函数库中函数名称为exportName函数的绝对地址。
代码示例如下。
function frida_Module() {
Java.perform(function () {
Module.getExportByName('libhello.so', 'c_getStr')
console.log("Java_com_roysue_roysueapplication_hellojni_getStr address:",Module.findExportByName('libhello.so', 'Java_com_roysue_roysueapplication_hellojni_getStr'));
console.log("Java_com_roysue_roysueapplication_hellojni_getStr address:",Module.getExportByName('libhello.so', 'Java_com_roysue_roysueapplication_hellojni_getStr'));
});
}
setImmediate(frida_Module,0);
输出如下:
Java_com_roysue_roysueapplication_hellojni_getStr address: 0xdf2d413d
Java_com_roysue_roysueapplication_hellojni_getStr address: 0xdf2d413d返回name模块的基地址。
代码示例如下。
function frida_Module() {
Java.perform(function () {
var name = "libhello.so";
console.log("so address:",Module.findBaseAddress(name));
console.log("so address:",Module.getBaseAddress(name));
});
}
setImmediate(frida_Module,0);
输出如下:
so address: 0xdf2d3000
so address: 0xdf2d3000
Memory的一些API通常是对内存处理,譬如Memory.copy()复制内存,又如writeByteArray写入字节到指定内存中,那我们这章中就是学习使用Memory API向内存中写入数据、读取数据。
其主要功能是搜索内存中以address地址开始,搜索长度为size,需要搜是条件是pattern,callbacks搜索之后的回调函数;此函数相当于搜索内存的功能。
我们来直接看例子,然后结合例子讲解,如下图1-5。
图1-5 IDA中so文件某处数据
如果我想搜索在内存中112A地址的起始数据要怎么做,代码示例如下。
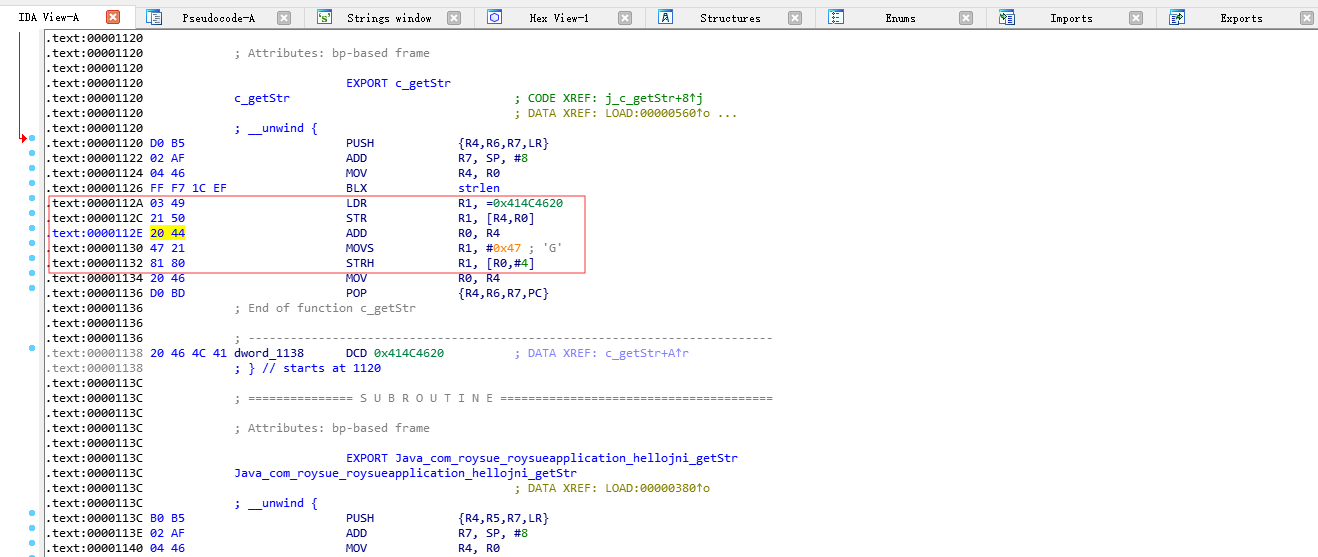
function frida_Memory() {
Java.perform(function () {
//先获取so的module对象
var module = Process.findModuleByName("libhello.so");
//??是通配符
var pattern = "03 49 ?? 50 20 44";
//基址
console.log("base:"+module.base)
//从so的基址开始搜索,搜索大小为so文件的大小,搜指定条件03 49 ?? 50 20 44的数据
var res = Memory.scan(module.base, module.size, pattern, {
onMatch: function(address, size){
//搜索成功
console.log('搜索到 ' +pattern +" 地址是:"+ address.toString());
},
onError: function(reason){
//搜索失败
console.log('搜索失败');
},
onComplete: function()
{
//搜索完毕
console.log("搜索完毕")
}
});
});
}
setImmediate(frida_Memory,0);先来看看回调函数的含义,onMatch:function(address,size):使用包含作为NativePointer的实例地址的address和指定大小为数字的size调用,此函数可能会返回字符串STOP以提前取消内存扫描。onError:Function(Reason):当扫描时出现内存访问错误时使用原因调用。onComplete:function():当内存范围已完全扫描时调用。
我们来来说上面这段代码做了什么事情:搜索libhello.so文件在内存中的数据,搜索以pattern条件的在内存中能匹配的数据。搜索到之后根据回调函数返回数据。
我们来看看执行之后的效果图1-6。
图1-6 终端执行
我们要如何验证搜索到底是不是图1-5中112A地址,其实很简单。so的基址是0xdf2d3000,而搜到的地址是0xdf2d412a,我们只要df2d412a-df2d3000=112A。就是说我们已经搜索到了!

功能与Memory.scan一样,只不过它是返回多个匹配到条件的数据。
代码示例如下。
function frida_Memory() {
Java.perform(function () {
var module = Process.findModuleByName("libhello.so");
var pattern = "03 49 ?? 50 20 44";
var scanSync = Memory.scanSync(module.base, module.size, pattern);
console.log("scanSync:"+JSON.stringify(scanSync));
});
}
setImmediate(frida_Memory,0);
输出如下,可以看到地址搜索出来是一样的
scanSync:[{"address":"0xdf2d412a","size":6}]在目标进程中的堆上申请size大小的内存,并且会按照Process.pageSize对齐,返回一个NativePointer,并且申请的内存如果在JavaScript里面没有对这个内存的使用的时候会自动释放的。也就是说,如果你不想要这个内存被释放,你需要自己保存一份对这个内存块的引用。
使用案例如下
function frida_Memory() {
Java.perform(function () {
const r = Memory.alloc(10);
console.log(hexdump(r, {
offset: 0,
length: 10,
header: true,
ansi: false
}));
});
}
setImmediate(frida_Memory,0);以上代码在目标进程中申请了10字节的空间~
可以看到在0xdfe4cd40处申请了10个字节内存空间~
也可以使用:Memory.allocUtf8String(str) 分配utf字符串Memory.allocUtf16String 分配utf16字符串Memory.allocAnsiString 分配ansi字符串
如同c api memcp一样调用,使用案例如下。
function frida_Memory() {
Java.perform(function () {
//获取so模块的Module对象
var module = Process.findModuleByName("libhello.so");
//条件
var pattern = "03 49 ?? 50 20 44";
//搜字符串 只是为了将so的内存数据复制出来 方便演示~
var scanSync = Memory.scanSync(module.base, module.size, pattern);
//申请一个内存空间大小为10个字节
const r = Memory.alloc(10);
//复制以module.base地址开始的10个字节 那肯定会是7F 45 4C 46...因为一个ELF文件的Magic属性如此。
Memory.copy(r,module.base,10);
console.log(hexdump(r, {
offset: 0,
length: 10,
header: true,
ansi: false
}));
});
}
setImmediate(frida_Memory,0);
输出如下。
0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF
e8142070 7f 45 4c 46 01 01 01 00 00 00 .ELF......从module.base中复制10个字节的内存到新年申请的r内
将字节数组写入一个指定内存,代码示例如下:
function frida_Memory() {
Java.perform(function () {
//定义需要写入的字节数组 这个字节数组是字符串"roysue"的十六进制
var arr = [ 0x72, 0x6F, 0x79, 0x73, 0x75, 0x65];
//申请一个新的内存空间 返回指针 大小是arr.length
const r = Memory.alloc(arr.length);
//将arr数组写入R地址中
Memory.writeByteArray(r,arr);
//输出
console.log(hexdump(r, {
offset: 0,
length: arr.length,
header: true,
ansi: false
}));
});
}
setImmediate(frida_Memory,0);
输出如下。
0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF
00000000 72 6f 79 73 75 65 roysue将一个指定地址的数据,代码示例如下:
function frida_Memory() {
Java.perform(function () {
//定义需要写入的字节数组 这个字节数组是字符串"roysue"的十六进制
var arr = [ 0x72, 0x6F, 0x79, 0x73, 0x75, 0x65];
//申请一个新的内存空间 返回指针 大小是arr.length
const r = Memory.alloc(arr.length);
//将arr数组写入R地址中
Memory.writeByteArray(r,arr);
//读取r指针,长度是arr.length 也就是会打印上面一样的值
var buffer = Memory.readByteArray(r, arr.length);
//输出
console.log("Memory.readByteArray:");
console.log(hexdump(buffer, {
offset: 0,
length: arr.length,
header: true,
ansi: false
}));
});
});
}
setImmediate(frida_Memory,0);
输出如下。
[Google Pixel::com.roysue.roysueapplication]-> Memory.readByteArray:
0 1 2 3 4 5 6 7 8 9 A B C D E F 0123456789ABCDEF
00000000 72 6f 79 73 75 65 roysue
在这篇中我们学会了在FRIDACLI中如何输出想要输出格式,也学会如何声明变量,一步步的学习。在逐步的学习的过程,总是会遇到不同的问题。歌曲<奇迹再现>我相信你一定听过吧~,新的风暴已经出现,怎么能够停止不前..遇到问题不要怕,总会解决的。
短视频、直播数据实时采集接口,请查看文档: TiToData
免责声明:本文档仅供学习与参考,请勿用于非法用途!否则一切后果自负。