" __----~~~~~~~~~~~------___"
" . . ~~//====...... __--~ ~~ "
" -. \_|// |||\\ ~~~~~~::::... /~ "
" ___-==_ _-~o~ \/ ||| \\ _/~~- "
" __---~~~.==~||\=_ -_--~/_-~|- |\\ \\ _/~ "
" _-~~ .=~ | \\-_ '-~7 /- / || \ / "
" .~ .~ | \\ -_ / /- / || \ / "
" / ____ / | \\ ~-_/ /|- _/ .|| \ / "
" |~~ ~~|--~~~~--_ \ ~==-/ | \~--===~~ .\ "
" ' ~-| /| |-~\~~ __--~~ "
" |-~~-_/ | | ~\_ _-~ /\ "
" / \ \__ \/~ \__ "
" _--~ _/ | .-~~____--~-/ ~~==. "
" ((->/~ '.|||' -_| ~~-/ , . _|| "
" -_ ~\ ~~---l__i__i__i--~~_/ "
" _-~-__ ~) \--______________--~~ "
" //.-~~~-~_--~- |-------~~~~~~~~ "
" //.-~~~--\) "
高山仰止,景行行止.虽不能至,心向往之。
- 1.1 继承
- 1.2 原型
- 1.3 深拷贝
- 1.4 闭包
- 1.5 es6
- 1.6 值传递 引用传递
- 1.7 垃圾回收
- 1.8 变量提升
- 1.9 异步
- 1.10 event 对象常见应用
- 1.11 模块
- 1.12 bind apply call
JS 实现继承的几种方式
- es5
借用构造函数实现继承
function Parent1(){
this.name = "parent1"
}
function Child1(){
Parent1.call(this);
this.type = "child1";
}
缺点:Child1无法继承Parent1的原型对象,并没有真正的实现继承(部分继承)
借用原型链实现继承
function Parent2(){
this.name = "parent2";
this.play = [1,2,3];
}
function Child2(){
this.type = "child2";
}
Child2.prototype = new Parent2();
缺点:原型对象的属性是共享的
组合式继承
function Parent3(){
this.name = "parent3";
this.play = [1,2,3];
}
function Child3(){
Parent3.call(this);
this.type = "child3";
}
Child3.prototype = Object.create(Parent3.prototype);
Child3.prototype.constructor = Child3;
- es6 继承
class Person{
constructor(){
this.name="Person"
}
dowhat(todo){
alert(this.name+" Should "+todo);
}
}
let person=new Person();
person.dowhat("work");
class Boy extends Person{
constructor(){
super();
this.name="Boy"
}
}
let boy=new Boy();
boy.dowhat("go to school");
原型介绍
hasOwnProperty : 检测对象原型上是否有这个方法
isPropertyof() : 检测该对象是否是原型实例
myO = {a:1}
{a: 1}
myO.hasOwnProperty('a')//true
Object.prototype.method=function(){
console.log(this);
}
var myObject={
a:1,
b:2,
c:3
}
for (var key in myObject) {
if(myObject.hasOwnProperty(key)){
console.log(key);
//a,b,c
}
}
每个对象都有**proto**属性,但只有函数对象才有 prototype 属性
https://www.jianshu.com/p/dee9f8b14771
var a = [];
Array.prototype.isPrototypeOf(a);
a instanceof Array //原理 a.__proto__(一个或若干个__proto__) === Array.prototype
//A instanceof B的话,只要B的原型对象出现在A的原型链中,就会返回true。
a.constructor == Array
Object.prototype.toString.call(a)
Array.isArray([])
Object.getPrototypeOf(a) === Array.prototype;
https://www.cnblogs.com/leaf930814/p/6659996.html
toString方法返回反映这个对象的字符串。
而Array ,function等类型作为Object的实例,都重写了toString方法。
因此,在想要得到对象的具体类型时,应该调用Object上原型toString方法。
深拷贝 主要解决对象指向问题
1 递归
var china = {
nation : '中国',
birthplaces:['北京','上海','广州'],
skincolr :'yellow',
rest:{a:3,b:4},
friends:['sk','ls']
}
//深复制,要想达到深复制就需要用递归
function deepCopy(o,c){
var c = c || {}
for(var i in o){
if(typeof o[i] === 'object'){
//要考虑深复制问题了
if(o[i].constructor === Array){
//这是数组
c[i] =[]
}else{
//这是对象
c[i] = {}
}
deepCopy(o[i],c[i])
}else{
c[i] = o[i]
}
}
return c
}
var result = {name:'result'}
result = deepCopy(china,result)
console.dir(result)
var china = {
nation : '中国',
birthplaces:['北京','上海','广州'],
skincolr :'yellow',
rest:{a:3,b:4},
friends:['sk','ls']
}
var t = JOSN.Parse(JSON.stringfy(china))
浅拷贝 es6
Object.assign,ES6 的新函数,可以帮助我们达成跟上面一样的功能。
var obj1 = { a: 10, b: 20, c: 30 };
var obj2 = Object.assign({}, obj1);
obj2.b = 100;
console.log(obj1);
// { a: 10, b: 20, c: 30 } <-- 沒被改到
console.log(obj2);
闭包是什么? 专业说法:当一个内部函数被其外部函数之外的变量引用时,就形成了一个闭包。
闭包有三个特性:
1.函数嵌套函数
2.函数内部可以引用外部的参数和变量
3.参数和变量不会被垃圾回收机制回收
闭包简单例子 函数套函数就是闭包吗?不是!,当一个内部函数被其外部函数之外的变量引用时,才会形成了一个闭包。
function f1(){
var n=999;
nAdd=function(){n+=1}
function f2(){
alert(n);
}
return f2;
}
var result=f1();
result(); // 999
nAdd();
result(); // 1000
for(var i =0; i<link.length; i++){
link[i].onclick = (function(i){ // outer function
return function(){ //inner function
alert(i);
};
})(i);
}
1.promise 用法
let p = new Promise(function (resolve) {
$.get('mockData/webkit-dep.json',function (webkitDep) {
resolve(webkitDep)
})
})
p.then(function(data){
console.log(data)//webkitDep
})
2.for of 与 for in 的区别 https://www.cnblogs.com/dupd/archive/2016/09/22/5895474.html
3.es6 简单介绍:https://segmentfault.com/a/1190000004365693
4.Symbol https://my.oschina.net/u/2903254/blog/818796
5 箭头函数
(1)函数体内的 this 对象,就是定义时所在的对象,而不是使用时所在的对象。
(2)不可以当作构造函数,也就是说,不可以使用 new 命令,否则会抛出一个错误。
(3)不可以使用 arguments 对象,该对象在函数体内不存在。如果要用,可以用 Rest 参数代替。
(4)不可以使用 yield 命令,因此箭头函数不能用作 Generator 函数。
var t = {a:'c',b:'d'}
var t2 = {a:'c',b:'d'}
function turn(obj){
obj = {a:'baidu'}
}
turn(t)
function tunr1(obj){
obj.a = 'jj'
}
console.log(t)//{a: "c", b: "d"}
tunr1(t2)
console.log(t2)//{a: "jj", b: "d"}
var foo={n:1};
(function (foo) {
console.log(foo.n);
foo.n=3;
var foo={n:2};
console.log(foo.n);
})(foo);
console.log(foo.n); //1,2,3
准确的说,JS 中的基本类型按值传递,对象类型按共享传递的(call by sharing,也叫按对象传递、按对象共享传递)。最早由 Barbara Liskov. 在 1974 年的 GLU 语言中提出。该求值策略被用于 Python、Java、Ruby、JS 等多种语言。
该策略的重点是:调用函数传参时,函数接受对象实参引用的副本(既不是按值传递的对象副本,也不是按引用传递的隐式引用)。 它和按引用传递的不同在于:在共享传递中对函数形参的赋值,不会影响实参的值。如下面例子中,不可以通过修改形参 o 的值,来修改 obj 的值。
var obj = {x : 1};
function foo(o) {
o = 100;
}
foo(obj);
console.log(obj.x); // 仍然是1, obj并未被修改为100.
然而,虽然引用是副本,引用的对象是相同的。它们共享相同的对象,所以修改形参对象的属性值,也会影响到实参的属性值。
var obj = {x : 1};
function foo(o) {
o.x = 3;
}
foo(obj);
console.log(obj.x); // 3, 被修改了!
-
标记清除
-
引用计数 -iE
var a = new A();
a.set();
a = ""
https://www.cnblogs.com/dolphinX/p/3348468.html
https://mp.weixin.qq.com/s/NkVaY1usOBQ4-if2mmmi3w
function test(){
if(false){
var a = 3
}
console.log(a)//undefined
}
1 setTimeout/setInterval
2 Ajax
3 readFlie
defer和async
defer并行加载js文件,会按照页面上script标签的顺序执行
async并行加载js文件,下载完成立即执行,不会按照页面上script标签的顺序执行

call 是 obj.method()到 method(obj)的变换,返回函数调用结果,所需参数依次用逗号分割添加至 obj 尾部
awaiat
微任务
setTimeout(function(){
})
事件委托是对事件冒泡的运用
event.preventDefault(),阻止默认行为
event.stopPropagation(),阻止事件冒泡
event.stopImmediatePropagation(),
阻止剩余的事件处理函数执行并且防止事件冒泡到DOM树上,这个方法不接受任何参数。
event.currentTarget,返回绑定事件的元素
event.target,返回触发事件的元素
addEventListener 的第三个参数 事件机制
深度好文
https://my.oschina.net/u/1454562/blog/205010
.cmd 和 amd 的区别 有必要简单提一下两者的主要区别,CMD 推崇依赖就近,可以把依赖写进你的代码中的任意一行,
例:define(function(require, exports, module) {
var a = require('./a')
a.doSomething()
var b = require('./b')
b.doSomething()
})
代码在运行时,首先是不知道依赖的,需要遍历所有的 require 关键字,找出后面的依赖。具体做法是将 function toString 后,用正则匹配出 require 关键字后面的依赖。显然,这是一种牺牲性能来换取更多开发便利的方法。
而 AMD 是依赖前置的,换句话说,在解析和执行当前模块之前,模块作者必须指明当前模块所依赖的模块,表现在 require 函数的调用结构上为:
define(['./a','./b'],function(a,b){
a.doSomething()
b.doSomething()
})
代码在一旦运行到此处,能立即知晓依赖。而无需遍历整个函数体找到它的依赖,因此性能有所提升,缺点就是开发者必须显式得指明依赖——这会使得开发工作量变大,比如:当你写到函数体内部几百上千行的时候,忽然发现需要增加一个依赖,你不得不回到函数顶端来将这个依赖添加进数组。
三种模块写法
首先定义:
AMD
//content.js
define('content.js', function(){
return 'A cat';
})
然后require:
//index.js
require(['./content.js'], function(animal){
console.log(animal); //A cat
})
CommonJS
//index.js
var animal = require('./content.js')
//content.js
module.exports = 'A cat'
ES6的写法
//index.js
import animal from './content'
//content.js
export default 'A cat'
以上我把三者都列出来了,妈妈再也不用担心我写混淆了...
var info = "out of ob";
var ob = {
info: "in ob",
msg: function(){console.log(this.info);}
};
ob.msg();//in ob
var outmsg = ob.msg;
outmsg();//out of ob
var bindmsg = outmsg.bind(ob);
bindmsg();//in ob
其实 this 就是其所在的函数,当作为方法被调用时,所属的对象。听起来很复杂,可以就你上面给出的例子来举例:
var ob = {
info: "in ob",
msg: function(){console.log(this.info);}
};
ob.msg();//in ob
这里 this 在 msg 函数中,而 msg 函数作为方法被调用时,调用它的对象是 ob(就是这句 ob.msg())而当你进行了如下的操作时:
var outmsg = ob.msg;
outmsg();//out of ob
this 所在的函数为 outmsg(),而 outmsg()为全局变量,调用全局变量的对象是 window(这里就和楼上说的一样了),实际上这就可以看成 window.outmsg(),同时你又给 window 中的全局变量 info 赋了值,所以就会输出http://window.info的值。
bind 函数是个十分好用的函数,它的功能是:返回一个被改变了作用域的函数,也就是函数里面的 this,其好处就是返回的本身还是一个函数,不必立即执行。如你所写的:bindmsg = outmsg.bind(ob);,其目的就是把 outmsg 里面的所有 this 都指向了 ob,当你http://this.info的时候就会得到正确的值。 这里 javascript 还有两个功能差不多的函数:apply 和 call,他们的功能是绑定 this 的同时立即执行;比方题主可以试一下下面的代码:
var outmsg = ob.msg;
outmsg();//out of ob
var bindmsg = outmsg.bind(ob);
bindmsg();//in ob
outmsg.apply(ob);//in ob
outmsg.call(ob);//in
.apply call bind 区别
http://blog.csdn.net/xqg666666/article/details/47707727
bind 实现源码
function bind(fn,context){
return function(){
fn.call(context,arguments)
}
}
匿名函数 this 的指向问题
在这个上下文(执行环境)中匿名函数并没有绑定到任何一个对象中,意味着 this 指向 window(除非这个上下文(执行环境)是在严格模式下执行的,而严格模式下该 this 指向 undefined)
var name = “The Window”;
var object = {
name : “My Object”,
getNameFunc : function(){
return function(){
return this.name;
};
}
};
alert(object.getNameFunc()());
//”The Window” (in non-strict mode)
所谓同源是指,域名,协议,端口相同。
浏览器同一时间能够从一个域名下载多少资源
浏览器在加载页面中用到的 CSS、JS(JavaScript)、图片等样式、脚本和资源文件时,在同一个域名下并发加载的资源数量是有限的,例如 IE 6 和 IE 7 是两个,IE 8 是 6 个,chrome 各版本不大一样,一般是 4 ~ 6 个。一般大型网站的首页资源文件数量是很多的,那么如此小的并发连接数自然会加载很久。所以前端开发人员往往会将上述这些资源文件分布在多个域名下,变相地绕过浏览器的这个限制。当然除了这个限制的原因,将静态资源文件(图片、CSS、JS)独立存放在特定的服务器上也便于管理和提高效率。
因此解决 B/S 系统高并发的优化方法之一:将资源文件分布在不同的域名下。
手写 ajax
function loadXMLDoc()
{
var xmlhttp;
if (window.XMLHttpRequest)
{// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
}
else
{// code for IE6, IE5
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
document.getElementById("myDiv").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax/demo_post2.asp",true);
xmlhttp.setRequestHeader("Content-type","application/x-www-form-urlencoded");
xmlhttp.send("fname=Bill&lname=Gates");
}
一个页面从输入 URL 到页面加载显示完成,这个过程中都发生了什么?
浏览器渲染原理
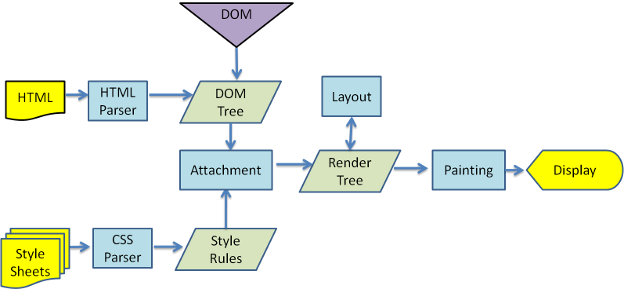
分为4个步骤:
(1),当发送一个URL请求时,不管这个URL是Web页面的URL还是Web页面上每个资源的URL,浏览器都会开启一个线程来处理这个请求,同时在远程DNS服务器上启动一个DNS查询。这能使浏览器获得请求对应的IP地址。
(2), 浏览器与远程`Web`服务器通过`TCP`三次握手协商来建立一个`TCP/IP`连接。该握手包括一个同步报文,一个同步-应答报文和一个应答报文,这三个报文在 浏览器和服务器之间传递。该握手首先由客户端尝试建立起通信,而后服务器应答并接受客户端的请求,最后由客户端发出该请求已经被接受的报文。
(3),一旦`TCP/IP`连接建立,浏览器会通过该连接向远程服务器发送`HTTP`的`GET`请求。远程服务器找到资源并使用HTTP响应返回该资源,值为200的HTTP响应状态表示一个正确的响应。
(4),此时,`Web`服务器提供资源服务,客户端开始下载资源。
请求返回后,便进入了我们关注的前端模块
简单来说,浏览器会解析`HTML`生成`DOM Tree`,其次会根据CSS生成CSS Rule Tree,而`javascript`又可以根据`DOM API`操作`DOM`
浏览器渲染
前端路由实现原理
https://juejin.im/post/5ac61da66fb9a028c71eae1b?utm_source=gold_browser_extension
第一种——调用 localStorage 在一个标签页里面使用 localStorage.setItem(key,value)添加(修改、删除)内容;
var obj = { name:'Jim', password: "123" }; var array = []; array.push(obj); array.push(obj); var str = JSON.stringify(array);
//存入 localStorage.obj = str; //读取 str1 = localStorage.obj; //重新转换为对象 obj1 = JSON.parse(str1); console.log(obj1)
在另一个标签页里面监听 storage 事件。 即可得到 localstorge 存储的值,实现不同标签页之间的通信。
标签页 1:
<input id="name">
<input type="button" id="btn" value="提交">
<script type="text/javascript">
$(function(){
$("#btn").click(function(){
var name=$("#name").val();
localStorage.setItem("name", name);
});
});
</script>
标签页 2:
<script type="text/javascript">
$(function(){
window.addEventListener("storage", function(event){
console.log(event.key + "=" + event.newValue);
});
});
</script>
第二种——调用 cookie+setInterval() 将要传递的信息存储在 cookie 中, 每隔一定时间读取 cookie 信息, 即可随时获取要传递的信息。
页面 1:
<input id="name">
<input type="button" id="btn" value="提交">
<script type="text/javascript">
$(function(){
$("#btn").click(function(){
var name=$("#name").val();
document.cookie="name="+name;
});
});
</script>
页面 2:
<script type="text/javascript">
$(function(){
function getCookie(key) {
return JSON.parse("{\"" + document.cookie.replace(/;\s+/gim,"\",\"").replace(/=/gim, "\":\"") + "\"}")[key];
}
setInterval(function(){
console.log("name=" + getCookie("name"));
}, 10000);
});
</script>
第三种——调用 window.postMessage
页面a
<iframe src = 'b.com/index.html' id='ifr'></iframe>
window.onload = function(){
var iframe = document.getElementById('ifr');
var targetOrigin = 'http://b.com'; // 若写成'http://b.com/c/proxy.html'效果一样
// 若写成'http://c.com'就不会执行postMessage了
iframe.contentWindow.postMessage('data to send',targetOrigin);
}
页面b
window.addEventListener('message',function(event){
// 通过origin属性判断消息来源地址
if(event.origin == 'http://a.com'){
console.log(event.data);
console.log(event.source);
}
},false);
Repaint又叫Redraw,重绘,它是指一种不影响当前dom结构的和布局的一种重绘动作。
以下的动作都会促发Repaint:
不可见或可见(visibility);
颜色和图片改变(background,border-color,color之类的属性);
不改变页面元素大小,形状和位置,但改变其外观的变化。
Reflow,又叫重构, 比起 Repaint 来讲就是一种更加显著的变化了。
它主要发生在 DOM 树被操作的时候,任何改变 DOM 的结构和布局都会产生 Reflow。
但一个元素的 Reflow 操作发生时,它的所有父元素和子元素都会发生 Reflow,
最后 Reflow 必然会导致 Repaint 的产生。举例说明,如下动作会产生 Repaint 动作:
浏览器窗口的变化;
DOM 节点的添加删除操作;
一些改变页面元素大小,形状和位置的操作的触发。
减少 Reflow
通过 Reflow 和 Repaint 的介绍可知,每次 Reflow 比其 Repaint 会带来更多的资源消耗,
我们应该尽量减少 Reflow 的发生,
或者将其转化为只会触发 Repaint 操作的代码。
浏览器从加载到渲染的过程,比如输入一个网址到显示页面的过程。
加载过程:
浏览器根据 DNS 服务器解析得到域名的 IP 地址
向这个 IP 的机器发送 HTTP 请求
服务器收到、处理并返回 HTTP 请求
浏览器得到返回内容
渲染过程:
根据 HTML 结构生成 DOM 树
根据 CSS 生成 CSSOM
将 DOM 和 CSSOM 整合形成 RenderTree
根据 RenderTree 开始渲染和展示
遇到<script>时,会执行并阻塞渲染
http://caibaojian.com/browser-cache.html
阮:http://www.ruanyifeng.com/blog/2016/04/cors.html
postMessage:https://www.cnblogs.com/dolphinX/p/3464056.html
1.jsonp 需要目标服务器配合一个callback函数。
2.window.name+iframe 需要目标服务器响应window.name。
3.window.location.hash+iframe 同样需要目标服务器作处理。
4.html5的 postMessage+ifrme 这个也是需要目标服务器或者说是目标页面写一个postMessage,主要侧重于前端通讯。
5.CORS 需要服务器设置header :Access-Control-Allow-Origin。
6.nginx反向代理
这个方法一般很少有人提及,但是他可以不用目标服务器配合,不过需要你搭建一个中转 nginx 服务器,用于转发请求。
个人觉得 6 才是正规的解决方案
1.GET后退按钮/刷新无害,POST数据会被重新提交(浏览器应该告知用户数据会被重新提交)。
2.GET书签可收藏,POST为书签不可收藏。
3.GET能被缓存,POST不能缓存 。
4,GET编码类型application/x-www-form-url,POST编码类型encodedapplication/x-www-form-urlencoded 或 multipart/form-data。为二进制数据使用多重编码。
5.GET历史参数保留在浏览器历史中。POST参数不会保存在浏览器历史中。
GET对数据长度有限制,当发送数据时,GET 方法向 URL 添加数据;URL 的长度是受限制的(URL 的最大长度是 2048 个字符)。
6.POST无限制。GET只允许 ASCII 字符。POST没有限制。也允许二进制数据。
7.与 POST 相比,GET 的安全性较差,因为所发送的数据是 URL 的一部分。
8.在发送密码或其他敏感信息时绝不要使用 GET !POST 比 GET 更安全,因为参数不会被保存在浏览器历史或 web 服务器日志中。
GET的数据在 URL 中对所有人都是可见的。POST的数据不会显示在 URL 中。
很多人都说要减少http请求,可关注为什么要减少请求的人却少很多,本文是对我在几篇博客以及知乎上看到的内容的整理。
http请求头的数据量
每次请求都会带上一些额外的信息进行传输,当请求的资源很小,比如1个不到1k的图标,可能request带的数据比实际图标的数据量还大。 所以当请求越多的时候,在网络上传输的数据自然就多,传输速度自然就慢了。
其实request自带的数据量还是小问题,毕竟request能带的数据量还是有限的。
http连接的开销
相比request头部多余的数据,http连接的开销则更加严重。先看看从用户输入1个URL到下载内容到客户端需要经过哪些阶段:
1. 域名解析
2. 开启TCP连接
3. 发送请求
4. 等待(主要包括网络延迟和服务器处理时间)
5. 下载资源
6. 文件解析执行时间
其实,每次请求花费的大部分时间在其他阶段,而不是在下载资源阶段 ,再小的资源照样会花费很多时间在其他阶段,只是下载阶段会比较短。
事情到这里还没完,网上看到有人提出了这样的疑问:
在http1.1,keep-alive是默认的,而且现代浏览器都有DNS缓存,那么对于“100条请求”和“对100条请求合并为1条请求”这两种方案来说:
* DNS寻址由于有DNS缓存–无差别;
* 3次握手由于有keep-alive,一条和一百条都只需一次TCP握手–无差别;
* 服务器解析–无差别;
只是增多了http报文头,在实际应用中,是否有大的性能差别?
答案是否定的。
即使有DNS缓存,浏览器也需要查找缓存,多个请求就需要查找多次,而且缓存有可能被无故清空,这样多个请求的DNS查询有可能花费更多时间。
TCP握手时间确实没差别,但时间性能上差别非常大。HTTP1.1协议规定请求只能串行发送,这也是HTTP性能最差和最让人诟病的地方,也就是说一百个请求必须依次逐个发送。第80个请求必须依赖于第79个请求正常返回之后才能发送。这样就平白无故多出了99个网络RTT(网络延迟)。合并请求比keep-alive下不合并请求理论上能节省大概 RTT * (N - 1) 的加载时间。由此可见,网络延迟其实是在有keep-alive情况下仍然需要请求合并的主要动力。
head of line blocking(队头阻塞)。设想这样一个场景,一个页面有100个请求,第99个请求时,TCP丢了一个包,TCP自然会重传,重传时间是T1,重传成功后,浏览器才能获取到完整页面的响应内容,然后渲染和展示整个页面。也就是说整个页面的加载时间延迟了T1时间。在此之前,用户没有得到任何内容。但如果建立了100个TCP连接呢?第99个请求出现丢包,那也只影响了第99个资源的展现,前面接收到的98个资源依然能正常加载,不会导致整个页面无法加载。
浏览器通过一个TCP连接发送100个请求的事情根本就不可能发生。当你有100个资源时,这100个资源在浏览器看来是“同时都要”,而浏览器并没有什么智商去判断应该用1个链接解决这100个资源,还是用100个链接来解决,不然浏览器永远都只有一个TCP链接了。因此浏览器的静态的策略是在自己可承受的范围内尽可能地用多的链接来解决,大部分浏览器似乎是6-8个链接,这就导致握手也是6-8次。
所以,我们要理解合并请求是为了什么?减少了哪些时间?优化了哪些策略?权衡了什么利弊?合并请求并不是万能的。
在 javascript 里面写 AJax 的时,最关键的一步是对 XMLHttpRequest 对象建立监听,即使用“onreadystatechange”方法。监听的时候,要对 XMLHttpRequest 对象的请求状态进行判断,通常是判断 readyState 的值为 4 且 http 返回状态 status 的值为 200 或者 304 时执行我们需要的操作。 readyState 属性表示 Ajax 请求的当前状态。

0 代表未初始化。 还没有调用 open 方法
1 代表正在加载。 open 方法已被调用,但 send 方法还没有被调用
2 代表已加载完毕。send 已被调用。请求已经开始
3 代表交互中。服务器正在发送响应
4 代表完成。响应发送完毕
作者:董可人 链接:https://www.zhihu.com/question/20215561/answer/40250050 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
你可以把 WebSocket 看成是 HTTP 协议为了支持长连接所打的一个大补丁,它和 HTTP 有一些共性,是为了解决 HTTP 本身无法解决的某些问题而做出的一个改良设计。
在以前 HTTP 协议中所谓的 keep-alive connection 是指在一次 TCP 连接中完成多个 HTTP 请求,但是对每个请求仍然要单独发 header;
所谓的 polling 是指从客户端(一般就是浏览器)不断主动的向服务器发 HTTP 请求查询是否有新数据。这两种模式有一个共同的缺点,就是除了真正的数据部分外,服务器和客户端还要大量交换 HTTP header,信息交换效率很低。
它们建立的“长连接”都是伪.长连接,只不过好处是不需要对现有的 HTTP server 和浏览器架构做修改就能实现。
WebSocket 解决的第一个问题是,通过第一个 HTTP request 建立了 TCP 连接之后,之后的交换数据都不需要再发 HTTP request 了,使得这个长连接变成了一个真.长连接。但是不需要发送 HTTP header 就能交换数据显然和原有的 HTTP 协议是有区别的,所以它需要对服务器和客户端都进行升级才能实现。在此基础上 WebSocket 还是一个双通道的连接,在同一个 TCP 连接上既可以发也可以收信息。此外还有 multiplexing 功能,几个不同的 URI 可以复用同一个 WebSocket 连接。这些都是原来的 HTTP 不能做到的。
另外说一点技术细节,因为看到有人提问 WebSocket 可能进入某种半死不活的状态。这实际上也是原有网络世界的一些缺陷性设计。上面所说的 WebSocket 真.长连接虽然解决了服务器和客户端两边的问题,但坑爹的是网络应用除了服务器和客户端之外,另一个巨大的存在是中间的网络链路。一个 HTTP/WebSocket 连接往往要经过无数的路由,防火墙。你以为你的数据是在一个“连接”中发送的,实际上它要跨越千山万水,经过无数次转发,过滤,才能最终抵达终点。在这过程中,中间节点的处理方法很可能会让你意想不到。比如说,这些坑爹的中间节点可能会认为一份连接在一段时间内没有数据发送就等于失效,它们会自作主张的切断这些连接。在这种情况下,不论服务器还是客户端都不会收到任何提示,它们只会一厢情愿的以为彼此间的红线还在,徒劳地一边又一边地发送抵达不了彼岸的信息。而计算机网络协议栈的实现中又会有一层套一层的缓存,除非填满这些缓存,你的程序根本不会发现任何错误。这样,本来一个美好的 WebSocket 长连接,就可能在毫不知情的情况下进入了半死不活状态。
而解决方案,WebSocket 的设计者们也早已想过。就是让服务器和客户端能够发送 Ping/Pong Frame(RFC 6455 - The WebSocket Protocol)。
这种 Frame 是一种特殊的数据包,它只包含一些元数据而不需要真正的 Data Payload,可以在不影响 Application 的情况下维持住中间网络的连接状态。
目前唯一的问题是:不兼容低版本的 IE
被问烂了的问题了,这里不详细讲了,三次握手:
第一次握手:客户端发送 syn 包(syn=j)到服务器,并进入 SYN_SEND 状态,等待服务器确认;
第二次握手:服务器收到 syn 包,必须确认客户的 SYN(ack=j+1),同时自己也发送一个 SYN 包(syn=k),即 SYN+ACK 包,此时服务器进入 SYN_RECV 状态;
第三次握手:客户端收到服务器的 SYN + ACK 包,向服务器发送确认包 ACK(ack=k+1),此包发送完毕,客户端和服务器进入 ESTABLISHED 状态,完成三次握手。
四次挥手:
客户端-发送一个 FIN,用来关闭客户端到服务器的数据传送
服务器-收到这个 FIN,它发回一个 ACK,确认序号为收到的序号加 1 。和 SYN 一样,一个 FIN 将占用一个序号
服务器-关闭与客户端的连接,发送一个 FIN 给客户端
客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加 1
十大排序 快排 冒泡排序。。。。
https://www.cnblogs.com/liyongshuai/p/7197962.html
有一个长度为 100 的数组,请以优雅的方式求出该数组的前 10 个元素之和
var a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15],
sum = 0;
sum = a.slice(0, 10).reduce(function(pre, current) {
return pre + current;
});
console.log(sum); //55
2、不使用loop循环,创建一个长度为100的数组,并且每个元素的值等于它的下标。
var a = Array(100).join(",").split(",").map(function(item, index) {
return index;
)}
js 十大排序算法详解
https://www.cnblogs.com/liyongshuai/p/7197962.html
1.数据结构和算法概述
2.数组、链表、队列、栈等线性表
3.二叉树、BST、AVL树及二叉树的递归与非递归遍历
4.B+树
5.跳表
6.图、图的存储、图的遍历
7.有向图、无向图、懒惰与积极的普利姆算法、克鲁斯卡尔算法及MST、单源最短路径问题及Dijkstra算法
8.并查集与索引式优先队列、二叉堆
9.遗传算法初步与TSP问题
10.内部排序(直接插入、选择、希尔、堆排序、快排、归并等)算法与实践中的优化
11.外部排序与优化(文件编码、数据编码、I/O方式与JVM特点、多线程、多路归并等)
12.哈希表、Trie树、倒排索引、分布式索引初步(Map-Reduce)
一、简介
第1讲:什么是数据结构?
第2讲:什么是算法?
二、线性表
第3讲:线性表(数组、链表、队列、栈)
第4讲:Linux work queue及JDK线程池 三、树
第5讲:非线性结构、树、二叉树
第6讲:平衡树、AVL树
第7讲:B+树与数据库索引 四、图
第8讲:图的概念与存储
第9讲:图的遍历
第10讲:最小生成树(MST)、Prim算法、Kruskal算法
第11讲:单源最短路径与Dijkstra算法
第12讲:用遗传算法近似求解TSP问题 五:排序
第13讲:选择排序、插入排序、希尔排序
第14讲:堆排序、优先队列
第15讲:快速排序及优化
第16讲:归并排序及优化
第17讲:归并排序与外部排序
第18讲:外部排序的优化及延伸 六:查找
第19讲:哈希表、二分查找、Trie树、Ternery树、搜索引擎与倒排索引、集中式索引与分布式索引、Map-Reduce初步
1 . gzip
2 .keep alive
3 .域名分发
4 .资源压缩
5 .请求合并
6 .图片地图
7 。dns 缓存
8 .尽量缓存全局变量
9 .少使用 evel with Function 原因 要从源码去解析 速度慢
10 .预加载
11 .懒加载
12 .在加载大量的图片元素时,尽量预先限定图片的尺寸大小,否则在图片加载过程中会更新图片的排版信息,产生大量的重排
13 .避免多次操作DOM的style,应该换成className,对于动态样式,一次性使用cssText
14 .频繁插入DOM元素时,可先用documentFragment来做缓存,创建一个documentFragment,将新生成的DOM都插入documentFragment中,最后一次性将documentFragment插入文档,只触发一次重排
15 .对于频繁更改大小位置的元素,可使用display: none使其“离线”,操作完成后再display: block,这样就只触发了2次重排
16 .避免使用JS动画,用CSS动画替换
17 .合理缓存DOM对象,减少DOM查询
18 .对元素使用position: absolute或者position: fixed,使其脱离文档流,它的变化不会影响其他元素
19 .使用CSS3的contain,控制页面的重绘与重排
20 .尽量使用 CSS3 的 translate、scale 属性代替 top、left 和 height、width,避免大量的重排计算
21 .滚动或resize时使用节流函数,并减少DOM操作
22 .开启GPU加速transform:translateZ(0),GPU加速会创建一个新的图层,与其他图层互不影响
23 .选择 Canvas 或 requestAnimationFrame 等更高效的动画实现方式,尽量避免使用 setTimeout、setInterval 等方式来直接处理连续动画。
https://www.jianshu.com/p/fb915d9c99c4
父组件向子组件通信:使用 props
子组件向父组件通信:使用 props 回调
跨级组件间通信:使用 context 对象
非嵌套组件间通信:使用事件订阅
this.props.children
为什么不能在 CompoenntWillMout 里写 ajax
ShouldComponentUpdate
高阶组件
前端面试宝典: http://www.cnblogs.com/huansky/p/7956908.html https://segmentfault.com/a/1190000013857582 https://github.com/markyun/My-blog/tree/master/Front-end-Developer-Questions/Questions-and-Answers webpack 原理
.--, .--,
( ( \.---./ ) )
'.__/o o\__.'
{= ^ =}
> - <
/ \
// \\
//| . |\\
"'\ /'"_.-~^`'-.
\ _ /--' `
___)( )(___
(((__) (__)))