Add queue_index_segment_entry_count configuration #2939
Conversation
|
This is what the memory looks like running over the week-end with a reduced segment entry count (1024 instead of 16384):
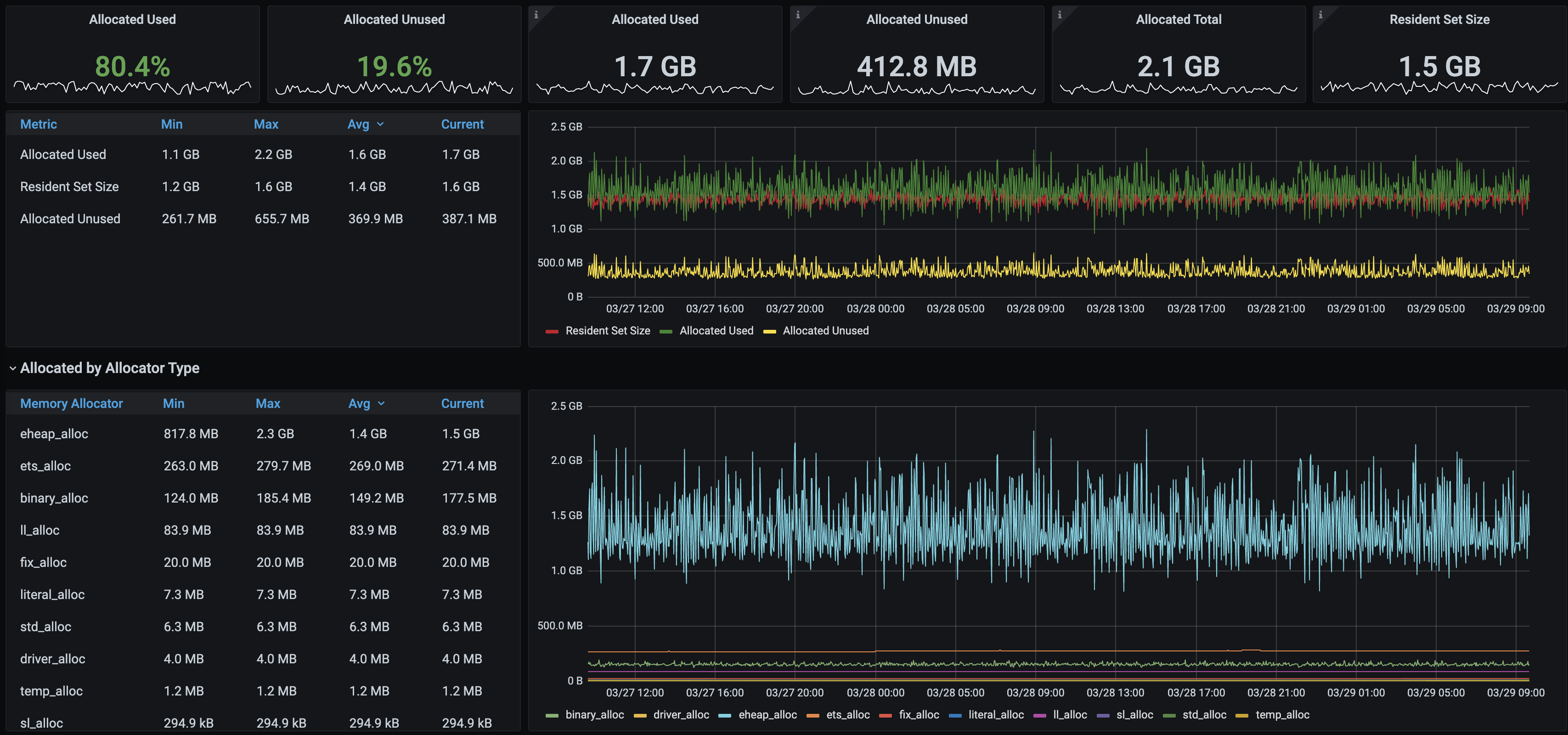
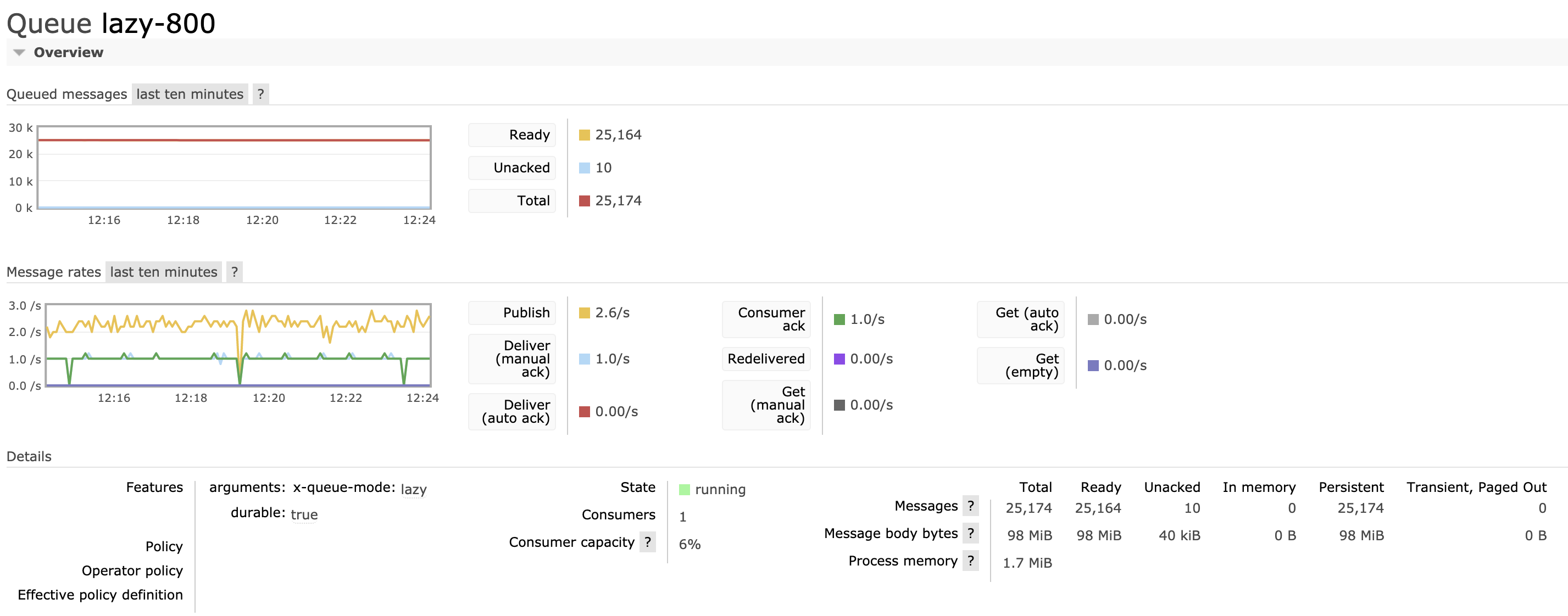
As you can see RSS is stable at 1.5G (1.2-1.4G according to management). This is with 800 lazy queues. Current RabbitMQ master would not manage with even 500 lazy queues as that would reach the There are about 20 million messages in the queues total with an expiration of 3 hours. Process memory is typically in the 1-2MB range:
|
|
I have tested the patch under Kubernetes. @gerhard Do you want to try it with the customer payload? @pjk25 I get "Permission denied" when I want to see the details of the bazel check. |
|
Patch running fine for 22 hours so far:
|
|
I'm picking this up now. Do not merge before the results are back in. |
|
@pjk25 do we have an example where we cache the I would like to speed up the current feedback loop by ~4 minutes:
|

|
@gerhard there are some caching example here https://github.com/rabbitmq/rabbitmq-server/blob/rabbitmq-server-2877/workflow_sources/test/tests.lib.yml but I suspect they aren't really what you are looking for. The main workflow used some caching for the secondary umbrellas some time ago in https://github.com/rabbitmq/rabbitmq-server/blob/eefb8c2792a85c281416d8cb1a2092d305380db6/.github/workflows/test-erlang-otp-23.1.yaml |
fc7b556 to
54f0ca0
Compare
|
I am adding the results of my findings to this thread. As soon as I am done, I will merge. This feels safe to backport to v3.8.x. Let me know if you disagree @michaelklishin. Is now a good time to remove the WIP from the title? |
|
@pjk25 our tests are not looking healthy. Test / test (23) in GitHub Actions is failing & bazel test is Disconnected (Permission denied). We can either remove these checks or fix them. I don't have enough current context to understand the feasibility of either option. As long as we don't allow ourselves to be OK with failing tests, I don't mind which option we choose. What do you think @pjk25? |
|
@gerhard it looks to me that the build fails because I made some breaking changes to https://github.com/rabbitmq/bazel-erlang since this branch was created. Rebasing or merging master should fix it. |
The default value of ?SEGMENT_ENTRY_COUNT is 16384. Due to the index file format the entire segment file has to be loaded into memory whenever messages from this segment must be accessed. This can result in hundreds of kilobytes that are read, processed and converted to Erlang terms. This creates a lot of garbage in memory, and this garbage unfortunately ends up in the old heap and so cannot be reclaimed before a full GC. Even when forcing a full GC every run (fullsweep_after=0) the process ends up allocating a lot of memory to read segment files and this can create issues in some scenarios. While this is not a problem when there are only a small number of queues, this becomes a showstopper when the number of queues is more important (hundreds or thousands of queues). This only applies to classic/lazy queues. This commit allows configuring the segment file entry count so that the size of the file can be greatly reduced, as well as the memory footprint when reading from the file becomes necessary. Experiments using a segment entry count of 1024 show no noticeable downside other than the natural increase in the number of segment files. The segment entry count can only be set on nodes that have no messages in their queue index. This is because the index uses this value to calculate in which segment file specific messages are sitting in.
dfc360c to
3cab7d5
Compare
|
Rebased to master. |
|
After the rebase it appears that:
have failed. I believe these two groups from their corresponding suites have been known to flake. I will retrigger the actions - it should only run the flaky tests this time. |
Key take-aways
Test setupWe used the #2785 workload as the starting point. Erlang 23.2.4 was built via the recently introduced OCI GitHub Action and we deployed on GKE with Cluster Operator. Expand the attached K8S manifest if you're interested to see all those details: K8S rabbitmq.ymlapiVersion: v1
kind: Namespace
metadata:
name: vesc-1002
---
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: pr-2939-ca
namespace: vesc-1002
spec:
ca:
secretName: pr-2939-ca
---
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: pr-2939-cert
namespace: vesc-1002
spec:
secretName: pr-2939-nodes-tls
duration: 2160h
renewBefore: 360h
subject:
organizations:
- RabbitMQ
commonName: pr-2939
isCA: false
privateKey:
algorithm: RSA
encoding: PKCS1
size: 2048
usages:
- server auth
- client auth
dnsNames:
- '*.pr-2939-nodes.vesc-1002'
- '*.pr-2939.vesc-1002'
issuerRef:
name: pr-2939-ca
kind: Issuer
group: cert-manager.io
---
apiVersion: v1
kind: ConfigMap
metadata:
name: pr-2939-tls-config
namespace: vesc-1002
data:
inter_node_tls.config: |
[
{server, [
{cacertfile, "/etc/rabbitmq/certs/ca.crt"},
{certfile, "/etc/rabbitmq/certs/tls.crt"},
{keyfile, "/etc/rabbitmq/certs/tls.key"},
{secure_renegotiate, true},
{fail_if_no_peer_cert, true},
{verify, verify_peer},
{customize_hostname_check, [
{match_fun, public_key:pkix_verify_hostname_match_fun(https)}
]}
]},
{client, [
{cacertfile, "/etc/rabbitmq/certs/ca.crt"},
{certfile, "/etc/rabbitmq/certs/tls.crt"},
{keyfile, "/etc/rabbitmq/certs/tls.key"},
{secure_renegotiate, true},
{fail_if_no_peer_cert, true},
{verify, verify_peer},
{customize_hostname_check, [
{match_fun, public_key:pkix_verify_hostname_match_fun(https)}
]}
]}
].
---
apiVersion: rabbitmq.com/v1beta1
kind: RabbitmqCluster
metadata:
name: pr-2939
namespace: vesc-1002
spec:
replicas: 3
image: pivotalrabbitmq/rabbitmq:3cab7d59a64ceb1f10eb0153cb001b17d71474b4
resources:
requests:
cpu: 6
memory: 40Gi
limits:
cpu: 6
memory: 40Gi
persistence:
storageClassName: ssd
storage: 100Gi
rabbitmq:
envConfig: |
SERVER_ADDITIONAL_ERL_ARGS="-pa /usr/local/lib/erlang/lib/ssl-10.1/ebin -proto_dist inet_tls -ssl_dist_optfile /etc/rabbitmq/inter-node-tls.config"
RABBITMQ_CTL_ERL_ARGS="-pa /usr/local/lib/erlang/lib/ssl-10.1/ebin -proto_dist inet_tls -ssl_dist_optfile /etc/rabbitmq/inter-node-tls.config"
additionalConfig: |
disk_free_limit.relative = 1.0
vm_memory_high_watermark.relative = 0.7
# management metrics can be disabled altogether
# management_agent.disable_metrics_collector = true
cluster_partition_handling = autoheal
cluster_name = pr-2939
advancedConfig: |
[
{rabbit, [
{queue_index_segment_entry_count, 1024}
]}
].
additionalPlugins:
- rabbitmq_amqp1_0
service:
type: LoadBalancer
tls:
secretName: pr-2939-nodes-tls
disableNonTLSListeners: true
tolerations:
- key: dedicated
operator: Equal
value: vesc-1002
effect: NoSchedule
override:
statefulSet:
spec:
template:
spec:
volumes:
- configMap:
defaultMode: 420
name: pr-2939-tls-config
name: inter-node-config
- name: pr-2939-nodes-tls
secret:
secretName: pr-2939-nodes-tls
items:
- key: ca.crt
mode: 416
path: ca.crt
- key: tls.crt
mode: 416
path: tls.crt
- key: tls.key
mode: 416
path: tls.key
containers:
- name: rabbitmq
volumeMounts:
- mountPath: /etc/rabbitmq/certs
name: pr-2939-nodes-tls
- mountPath: /etc/rabbitmq/inter-node-tls.config
name: inter-node-config
subPath: inter_node_tls.config
securityContext:
privileged: true
runAsUser: 0
nodeSelector:
com.rabbitmq: vesc-1002
---
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: rabbitmq
spec:
podMetricsEndpoints:
- interval: 15s
scheme: https
port: "15691"
selector:
matchLabels:
app.kubernetes.io/component: rabbitmq
namespaceSelector:
any: false
We ended with:
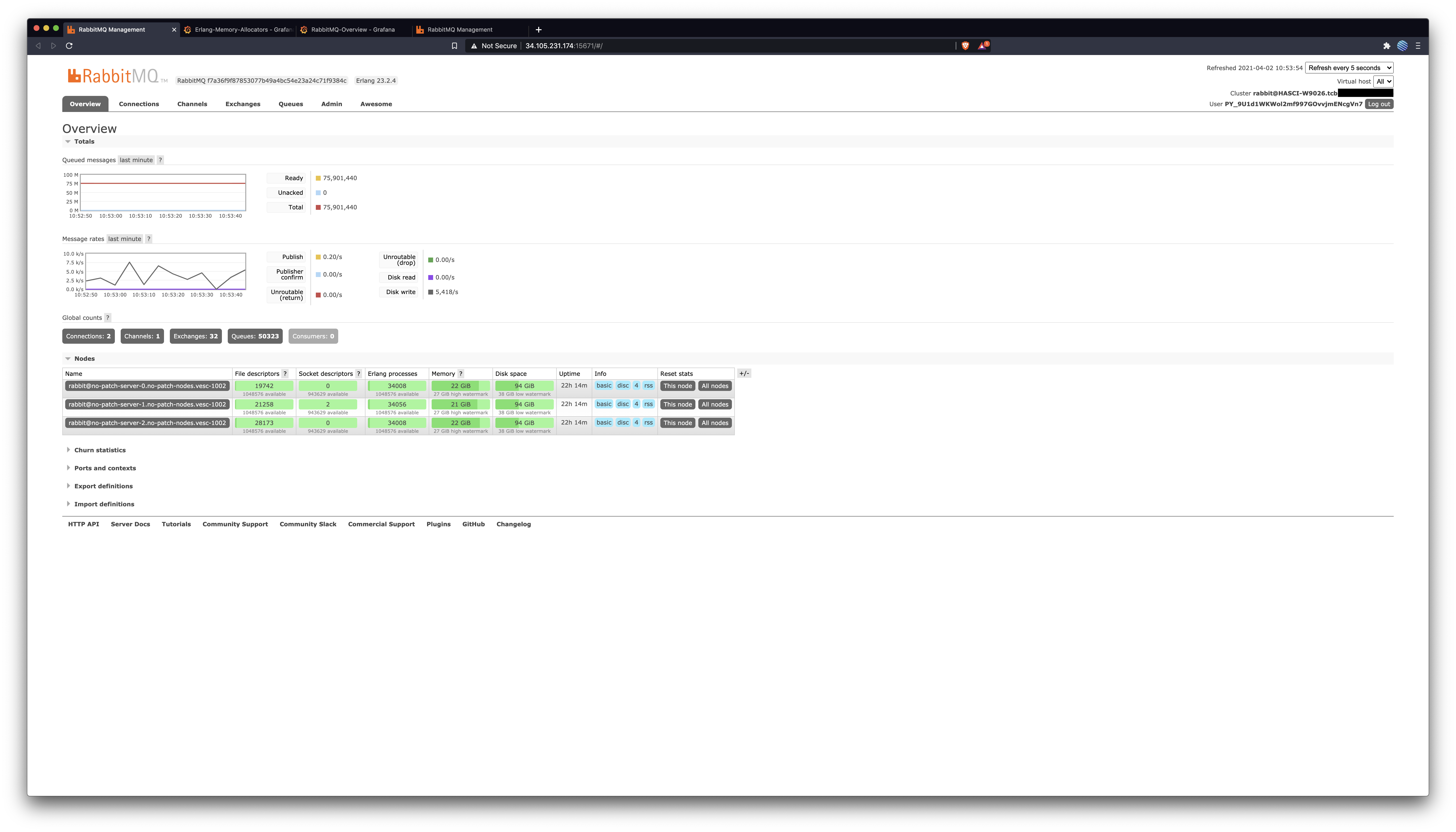
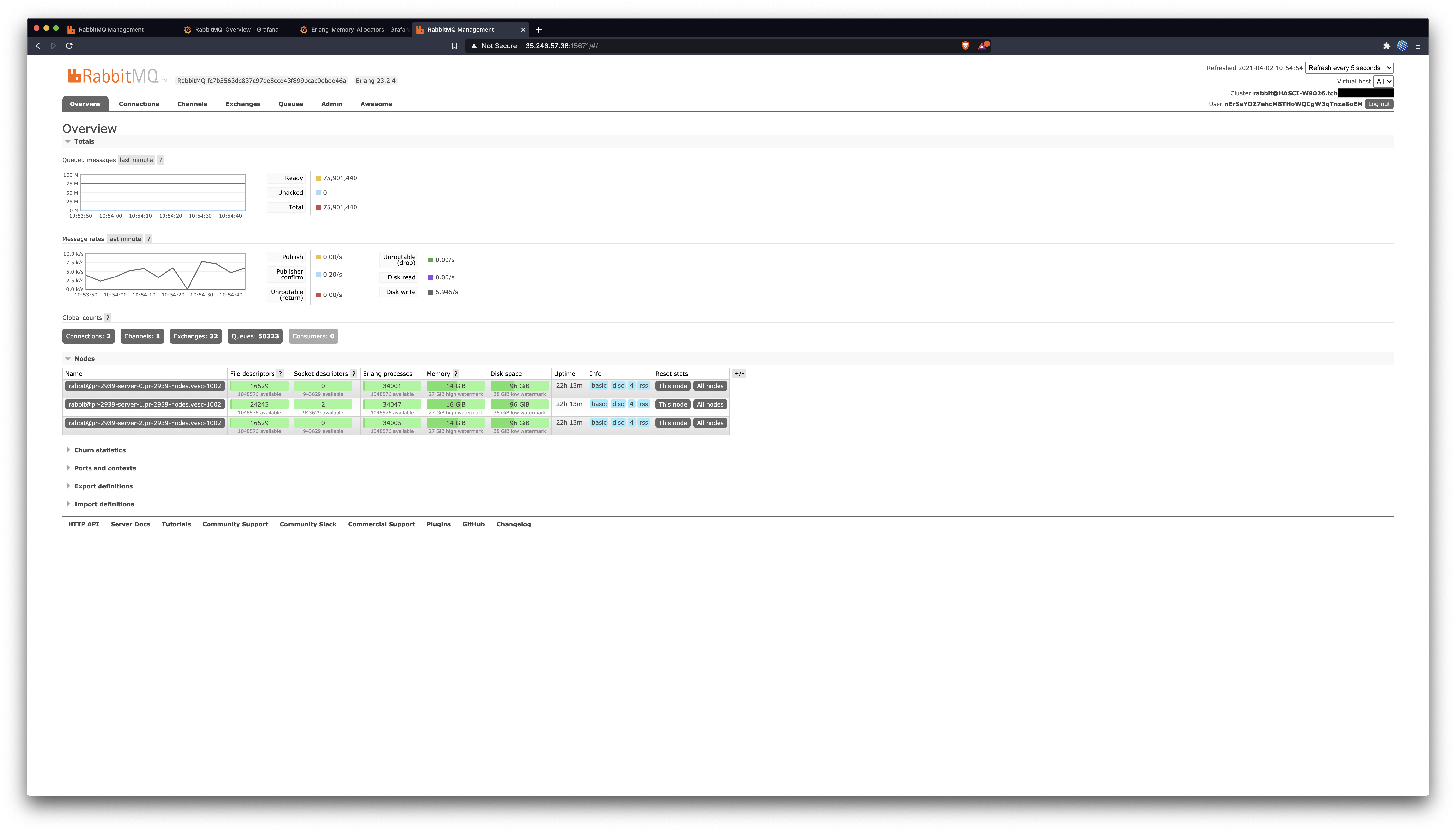
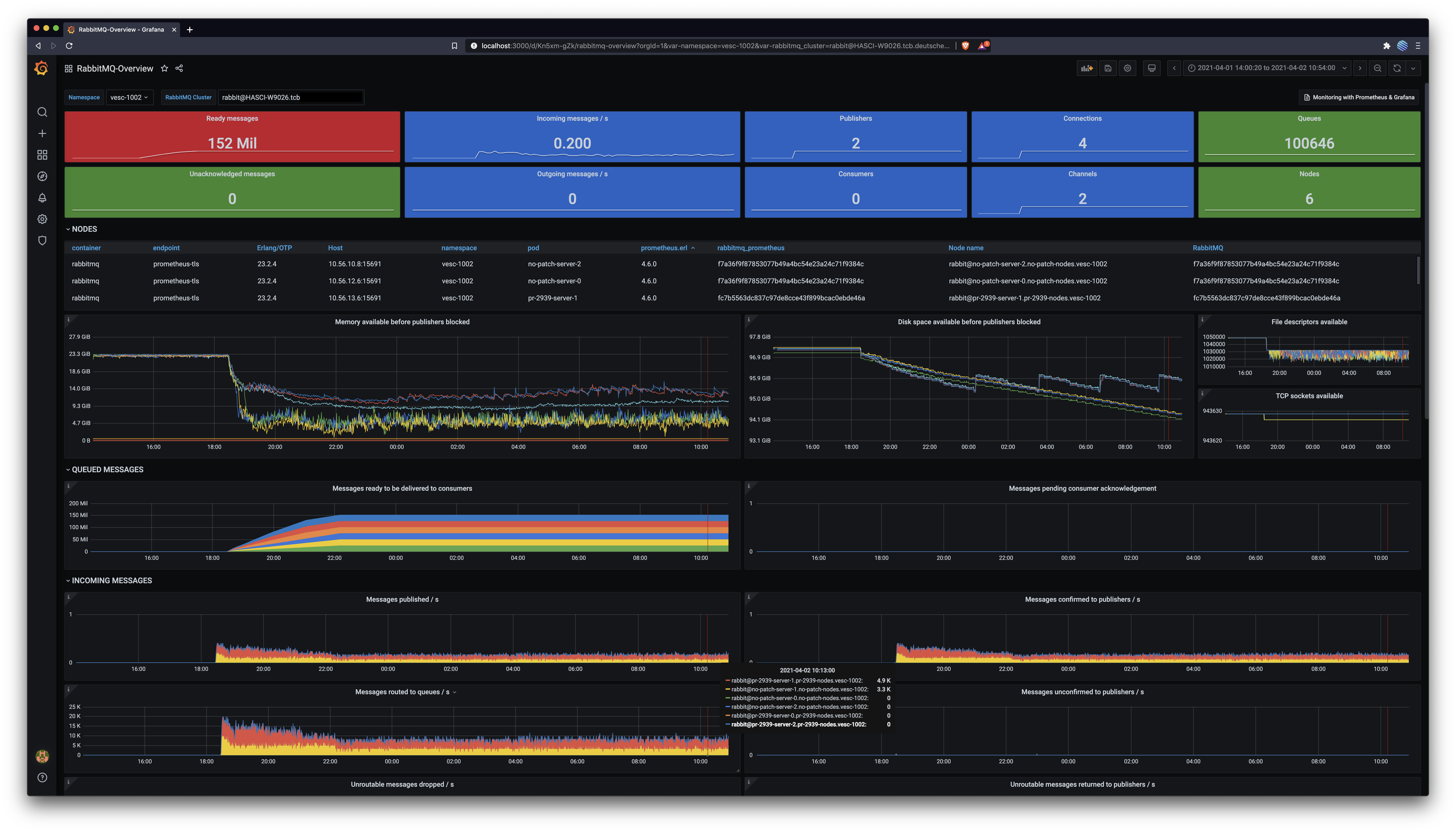
RabbitMQ Management OverviewBefore: After: RabbitMQ Overview DashboardThis captures all nodes across both clusters. Notice the more stable & abundant memory after this patch. Notice the disk space usage after this patch: it gets freed up periodically, but only shrinks before this patch. Messages routed to queues is consistently 50% higher after this patch (the node with this patch is the red one in that graph).
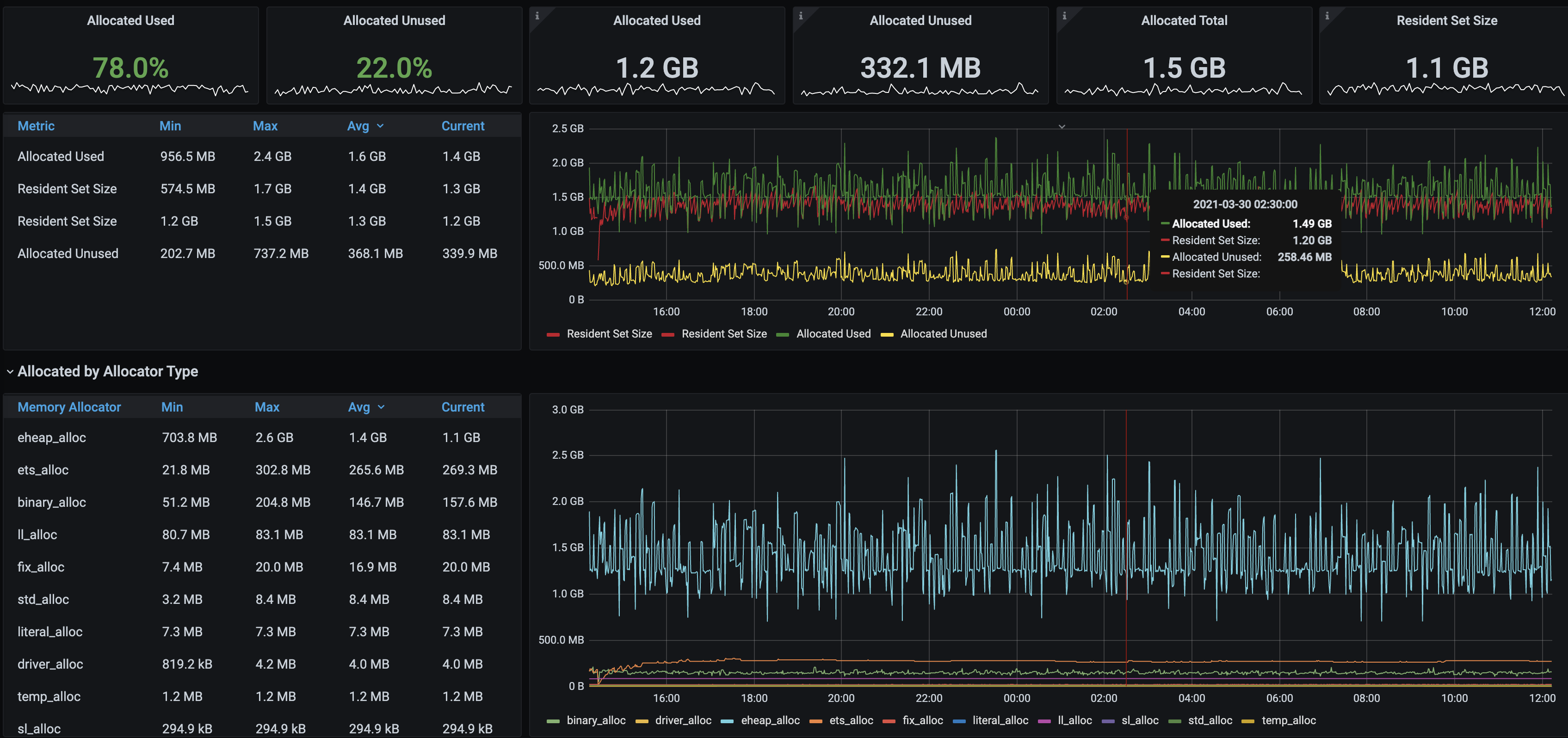
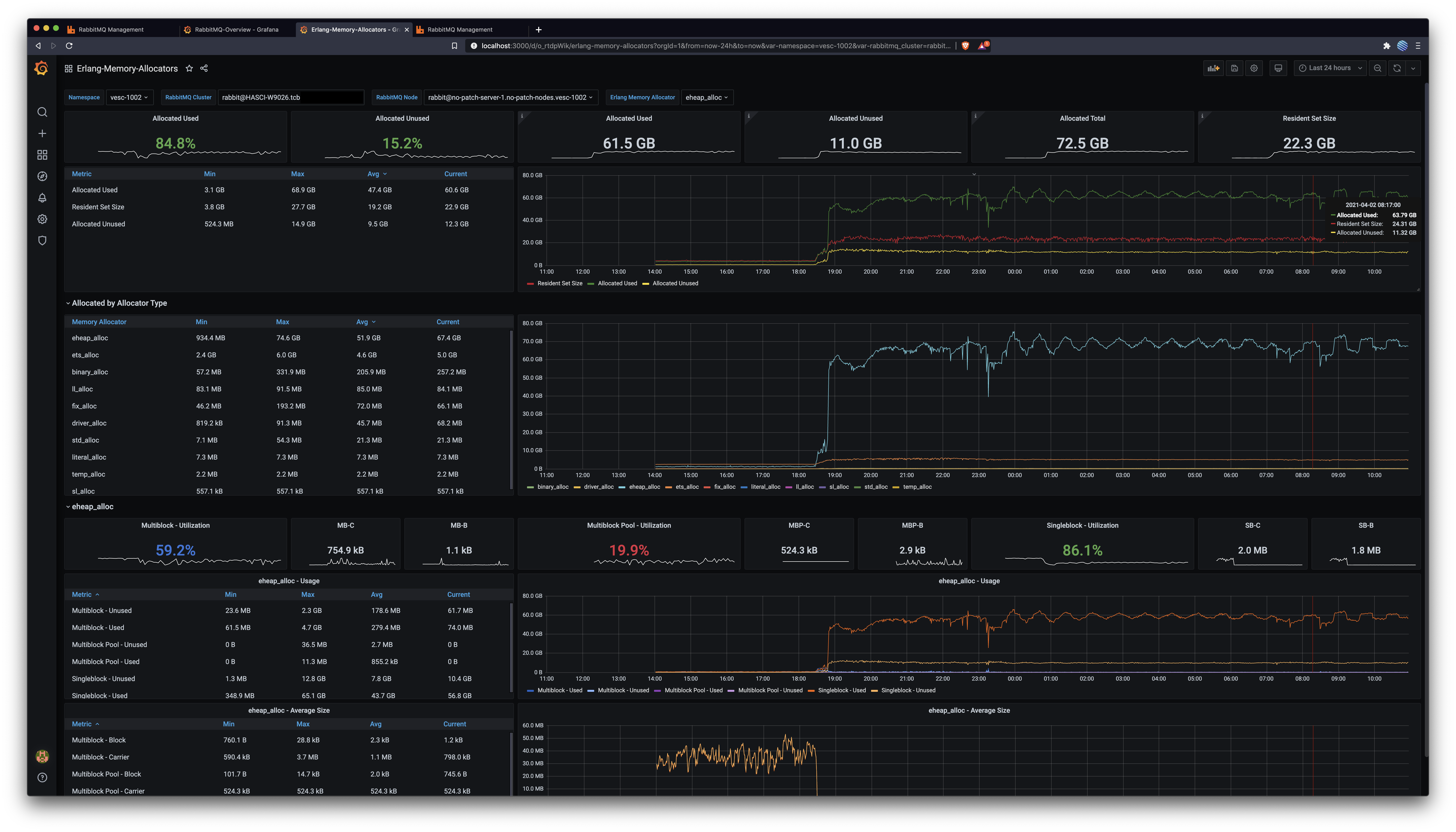
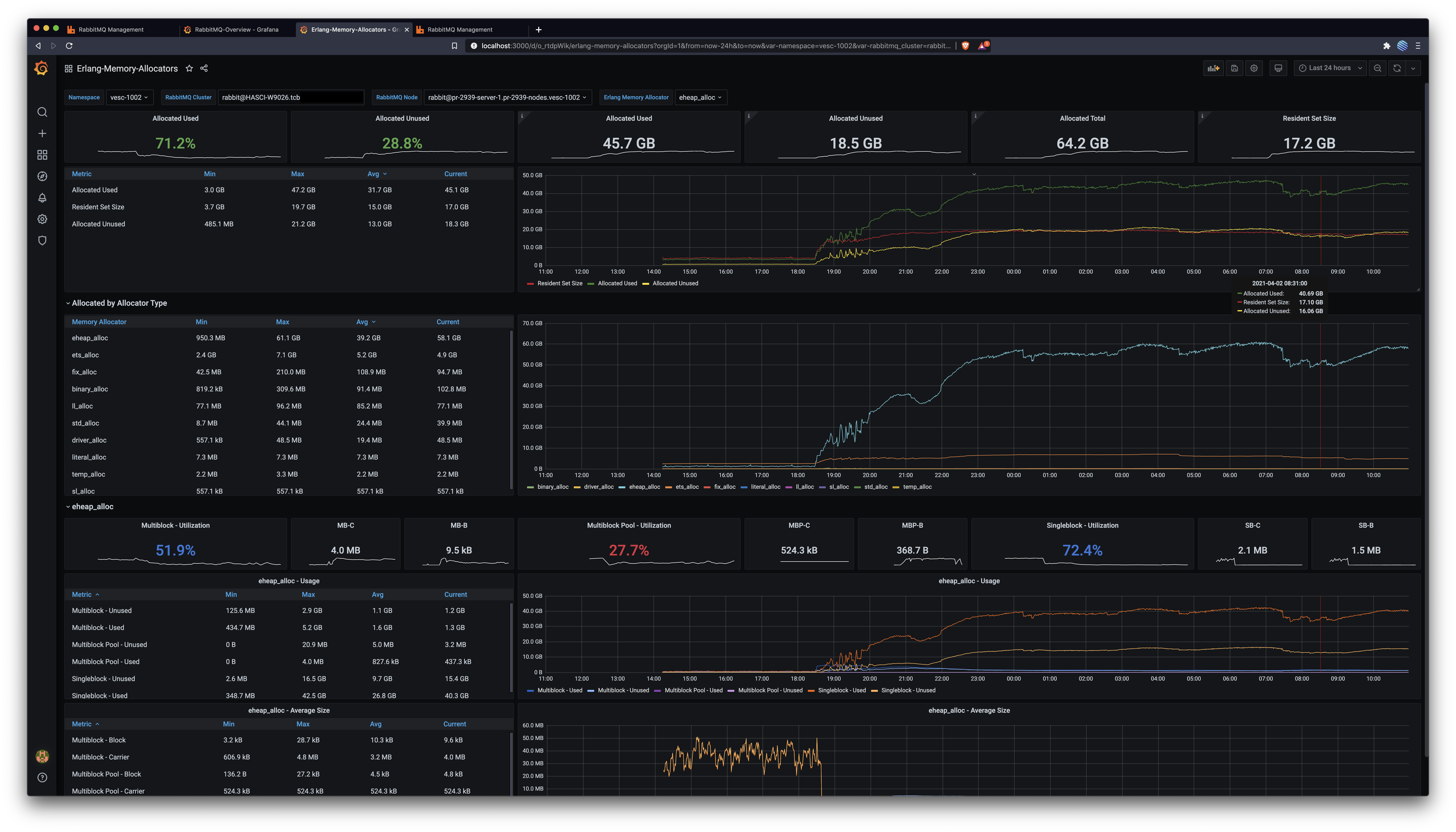
Erlang Allocators DashboardBefore: After: In conclusionThis patch enables nodes with many classic lazy queues, as the one described in #2785, to use less memory by keeping fewer messages in memory. The 16k default remains unchanged, but setting this value to 1k results in at least 25% memory usage and a more predictable utilisation pattern, as captured above. Great job @lhoguin, let's ship it 🛳️ 🚢 🤠
cc @motmot80 via #2785 |
|
I am backporting this to v3.8.x. Do we have Bazel there @pjk25? This makes me think that we don't: |
|
We don't but this may be a good moment to backport most of the Bazel work done up to this point. |
|
Thanks @michaelklishin, leaving that to @pjk25 👍🏻 |
Add queue_index_segment_entry_count configuration (cherry picked from commit 98f33fc) Signed-off-by: Gerhard Lazu <gerhard@lazu.co.uk>
|
Backported to v3.8.x via 08b286c |
|
Mind blown by #1284 having much of the problem already figured out. |
The default value of ?SEGMENT_ENTRY_COUNT is 16384. Due to
the index file format the entire segment file has to be loaded
into memory whenever messages from this segment must be accessed.
This can result in hundreds of kilobytes that are read, processed
and converted to Erlang terms. This creates a lot of garbage in
memory, and this garbage unfortunately ends up in the old heap
and so cannot be reclaimed before a full GC. Even when forcing
a full GC every run (fullsweep_after=0) the process ends up
allocating a lot of memory to read segment files and this can
create issues in some scenarios.
While this is not a problem when there are only a small number
of queues, this becomes a showstopper when the number of queues
is more important (hundreds or thousands of queues). This only
applies to classic/lazy queues.
This commit allows configuring the segment file entry count
so that the size of the file can be greatly reduced, as well
as the memory footprint when reading from the file becomes
necessary.
Experiments using a segment entry count of 1024 show no
noticeable downside other than the natural increase in the
number of segment files.
The segment entry count can only be set on nodes that have
no messages in their queue index. This is because the index
uses this value to calculate in which segment file specific
messages are sitting in.
Types of Changes
What types of changes does your code introduce to this project?
Put an
xin the boxes that applyChecklist
Put an
xin the boxes that apply. You can also fill these out after creatingthe PR. If you're unsure about any of them, don't hesitate to ask on the
mailing list. We're here to help! This is simply a reminder of what we are
going to look for before merging your code.
CONTRIBUTING.mddocumentFurther Comments
If this is a relatively large or complex change, kick off the discussion by
explaining why you chose the solution you did and what alternatives you
considered, etc.