
"I told my girl that i am a data scientist, but all I did was spent the past three days scrapping amazon products while trying to avoid antiscrapping firewall and copyright infringement. I hope that it counts like a Msc. Degree"
Table of Contents
- What is it
- Highlights -Process fluxogram -Deploy Archteture
- Requirements
- How to use
- Next Features
- Collabs
- About me
A fullstack application designed to scrapping amazon homepage and get infos like products name, prices, reviews and image urls.
We're on!!!
If you want to use the service:
Please have patience to use the live demo. Responses can be a little bit slow due the fact that the service is hosted by Render in Free Tier Plan
- Backend:
- Typescript
- Express
- Cheerio
- Docker-compose
- Redis
- Swagger
- Frontend
- Html5 + Css3
- Javascript
- Fontawesomeicons
- Playwright
- Tools
- RedisInsight
- Insomnia (API Client)
- Eslint (badly used i assume)
Some features that i'm proud for implement:
- Cache middleware to improve data fetch
- Dockerized (it works in OUR machine)
- Swagger
- Unit tests with Jest
- E2E tests with Playwright
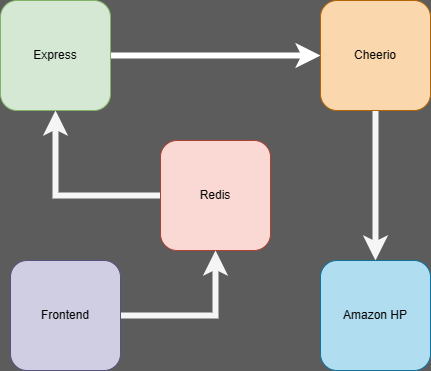
- User make a input through searchbar.
- FetchAPI will perform a request to API.
- Before perform a response, redis will try to locate a key/value with the keyword provided.
- If not find any, the Cheerio inside express controller will perform a request, get the html from amazon page and extract all the data necessary.
- After all, controller will return an array of products (or an error).
Whenever the user enter the page, the localStorage will be consulted. The last successful request products will be storage and will be rendered in the next visit
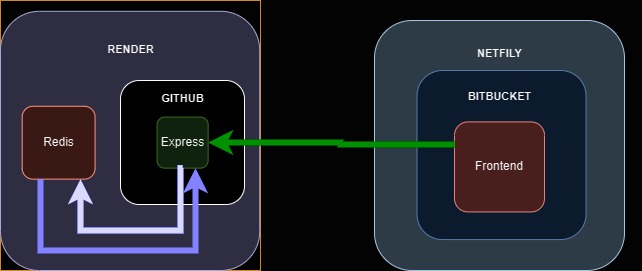
- The main source code (here o/) has the fullstack application.
- In order to deploy, i'm using Render
- Live Redis instance is another application aside hosted in render too
Honored mention to a CronJob hosted in Cron-job-free to make api constantly alive
You'll need:
- Node (18 or higher) (optional)
- Docker
- Docker-compose
In order to run the backend application locally and use it with the frontend UI, you will need to run docker-compose up --build in wsl2 or linux terminal in the root of project directory in your local environment.
This command will setup the local Redis container, crucial to provide api performance.
Thats all. I swear. xD.
You can use it with with a API Client such as Postman or Insomnia or use our GUI (highly recommended). To use it follow the Frontend docs
If your goal is to run locally and make editions in this application or even work with her in local dev environ thigs will change a bit.
- you'll need at least the
Rediscontainer up. (mandatory). - remove the host property in
src > config > redis.ts
After run npm install and npm run dev you'll able to perform requests in postman or proceed to Frontend docs normally.
The api have just one route /api/scrape?keyword= where keyword is a string. The api will do a request to amazon using the keyword as a search param and will use cheerio to scrap all the data from the first page and deliver back as a json.
To run locally, clone the .env.default and remove the .default of the copy.
USER_AGENT='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
# Redis
REDIS_HOST='127.0.0.1'
REDIS_PORT=6379
REDIS_USERNAME=
REDIS_PASSWORD=
As you can see, the REDIS_HOST points to your local ip by default, considering that you have a docker image running through your docker and you want to run the application locally, this is enough setup to start.
change this variables to alter the redis instance that you want to use.
USER_AGENT is a cheerio requirement to bypass Amazon firewall. Without a default user agent the request will fall into suspicious client and will be rejected. You can use the default if you want or catch one from a header of some request headers from your local browser.
This API have Jest implementation. To work with Jest and learn how things works upon here check the Unit Test Docs
The development process starts but never ends. Next features will be focused on:
- Swagger UI implement
- CronJob to preserve live status
- Reverse Proxy w/ Anti-robot spam firewall
- Implement other data sources aside of Amazon (i.e: Olx, Kabum, Submarino)
- Login system and Dashboard for data analisys
- Maybe a email sender for PDF report generation with Aws lambda for cloud study purposes (?)
- More pattern improvement, exploring themes like Queue and Load Balancing for heavy stress contexts
- Fork this repo.
- Create a branch:
git checkout -b <branch_name>. - Do your alterations and tell then in your commit message:
git commit -m '<commit_message>' - Send then to origin fork:
git push origin <project-name> / <local> - Create a pull request detailing your implementation.
- Access the Issues Section:
- Click the “New issue” button.
- In the “Title” field, type a descriptive title for your issue.
- In the comment body field, provide a detailed description of the issue you’re facing or the feature you’d like to request.
- Apply labels to categorize the issue.
Enhancementfor new featuresBugfor some issue in usability
- Click “Submit new issue” to create the issue.
 Rafael David |