



A 1st year's lab work (project) of the MSc. degree of Computer Science and Engineering made in FCT NOVA (Faculty of Sciences and Technology of New University of Lisbon), in the subject of High Performance Computing. This project was built using CUDA (Compute Unified Device Architecture), C++ (C Plus Plus), C, CMake and JetBrains CLion. The scenario of the project was a GPU-based implementation of the Self-Organising-Maps (S.O.M.) algorithm for Artificial Neural Networks (A.N.N.), with the support of CUDA (Compute Unified Device Architecture), using its offered parallel optimisations and tunings. The final goal of the project was to test the several GPU-based implementations of the algorithm against a given CPU-based implementation of the same algorithm and, evaluate and compare the overall performance (speedup, efficiency and cost).
Click here to see the Project's Description!
The goal of this project is to develop a GPU's implementation of Self-Organising Map (SOM) algorithm, and compare its performance (speedup, efficiency and cost) against a given sequential implementation of the algorithm.
You may implement your solution in either CUDA or OpenCL.
No higher level frameworks, such as Thrust, SkePU, TensorFlow, Marrow, or others, are allowed.
The project must be carried out by a group of, at most, 2 students.
S.O.M. is a very popular artificial neural network model that is trained via unsupervised learning, meaning that the learning process does not require human intervention and that not much needs to be known about the data itself.
The algorithm is used for clustering (feature detection) and visualization in exploratory data analysis. Application fields include pattern recognition, data mining and process optimization.
If you are curious about the fundamentals and the application of the algorithm, you can check the following site, which is a good starting point:
Note however, that you do not need this information to accomplish the task asked in this project.
The SOM algorithm is presented in Algorithm #1. The fitting of the model to the input dataset is represented by a map (represented by variable map), which is an array of nrows ∗ ncols vectors of nfeatures features, i.e., a tensor of size nrows × ncols × nfeatures. The algorithm begins by initialing map with vectors of random values, and then, for each input i performs the following steps:
-
Compute the distance from i to all vectors of map. The distance function may be any. You will be asked to implement 2 functions.
-
Compute the Best Matching Unit (bmu), which is the vector closest (with minimum distance) to i. Note that the argmin function returns the coordinate of the map where the bmu is.
-
Update the map, given the input i and the bmu.
With regard to the update map procedure, several learning rates may be considered. In this project you will consider only the one given by formula:
learning rate(t) = 1/t
Algorithm #1

You must implement a C/C++ program that receives the following command line:
gpu_som number_rows number_columns datafile outputfile [distance]
where number_rows and number_cols denote, respectively, the number of rows and columns of the map, datafile is the name of the file holding the input data set, and outputfile is the name of the file to where the final state of the map must be written. distance is the parameter that allows the user to choose between the two distance functions to implement. It is a optional parameter defaulted to the Euclidean distance.
Given this configuration, your program must execute in the GPU as much of the presented SOM algorithm as possible. In particular, the SOM map must reside is GPU’s memory and be modified there, as it receives inputs read from the input file and transferred to the GPU. A close analysis to Algorithm #1 will unveil several massively parallel computations, such as the ones that are performed for all the vectors of the matrix.
The map must only be transferred to the host explicitly via a function implemented for the purpose, with a name such as get map. You must naturally do this at the end of the computation, to store the map’s final state to the output file, but you can use it for debugging purposes (not in the version to evaluate for performance).
In order for you to test and evaluate your solution, several input data files will be provided in the next few days.
As mentioned in the previous section, you must implement two distance functions:
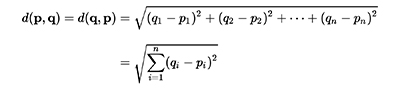
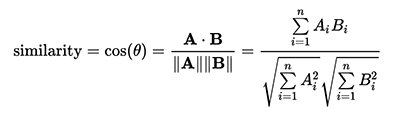
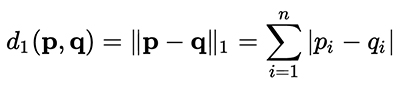
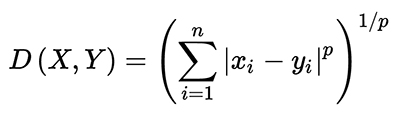
You must calculate the execution time of the versions (one version for each distance function) of your algorithm from the moment the SOM map is initialized (do not include this initialization) up until the map is written to the output file. These execution times must be compared against a sequential version that will be given in the next few days.
Along with the code of your solution, you must deliver a report of, at most, 5 pages presenting your solution, your experiment results and your conclusions. Concerning the solution, focus on explaining which parts of the algorithm are executed on the GPU, and describing the algorithms you devised to accomplish such execution.
Click here to see the Project's Report!
To install and run this application, you will need:
The Git feature and/or a third-party Git Client based GUI, like:
To install this application, you will only need to download or clone this repository and run the application locally:
You can do it downloading the .zip file in download section of this repository.
Or instead, by cloning this repository by a Git Client based GUI, using HTTPS or SSH, by one of the following link:
https://github.com/rubenandrebarreiro/gpu-cuda-self-organising-maps.git
- SSH:
git@github.com:rubenandrebarreiro/gpu-cuda-self-organising-maps.git
Or even, by running one of the following commands in a Git Bash Console:
git clone https://github.com/rubenandrebarreiro/gpu-cuda-self-organising-maps.git
- SSH:
git clone git@github.com:rubenandrebarreiro/gpu-cuda-self-organising-maps.git
- ruben.andre.letra.barreiro@gmail.com
- ruben.andre.letra.barreiro@gmail.com
- r.barreiro@campus.fct.unl.pt
- https://github.com/rubenandrebarreiro/
- https://gitlab.com/rubenandrebarreiro/
- https://bitbucket.org/rubenandrebarreiro/
- https://dev.azure.com/rubenandrebarreiro/
- 19 of 20