{kind=link}
{kind=link}
{kind=link}
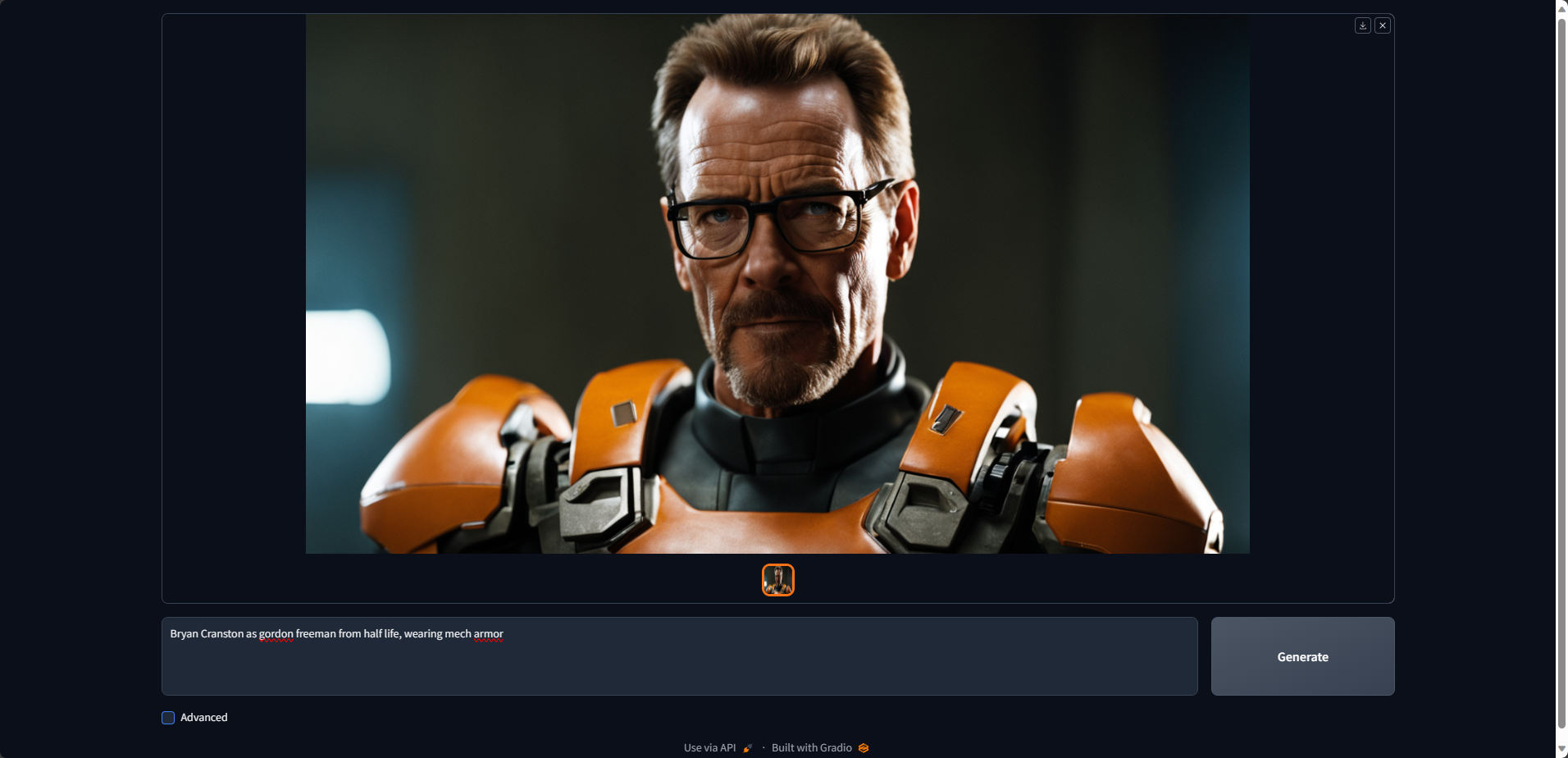
Forget everything you thought you knew about AI art generation - RuinedFooocus is here to completely reinvent the game!
This groundbreaking new image creator combines the best aspects of Stable Diffusion and Midjourney into one seamless, cutting-edge experience. The days of messy installations and manual tweaking are over. With RuinedFooocus, stunning images spring to life with just a few words - no technical skills required.
Built from the DNA of its predecessors but enhanced with next-level AI, RuinedFooocus generates jaw-dropping visuals in seconds. Just type a prompt and watch in awe as your wildest creative visions are instantly brought to life. The possibilities are truly endless.
But the magic doesn't stop there. RuinedFooocus puts the power in your hands like never before. You're in complete control of the experience from start to finish. And with its streamlined interface and intuitive controls, anyone can create like a pro.
Don't waste another minute stuck in the past. The future is calling, and it's time to answer with RuinedFooocus - the new standard in AI artistry. Install it today and unlock your creative potential like never before.
You can directly download Fooocus with:
>>> Click here to download <<<
NOTE YOU WILL NEED TO EXTRACT USING THE LATEST 7ZIP
After you download the file, please uncompress it, and then run the "run.bat".

In the first time you launch the software, it will automatically download models:
- It will download sd_xl_base_1.0_0.9vae.safetensors from here as the file "Fooocus\models\checkpoints\sd_xl_base_1.0_0.9vae.safetensors".
If you already have these files, you can copy them to the above locations to speed up installation.
Note that if you see "MetadataIncompleteBuffer", then your model files are corrupted. Please download models again.
The command lines are
git clone https://github.com/runew0lf/RuinedFooocus.git
cd RuinedFooocus
virtualenv venv
source venv/bin/activate
pip install -r requirements_versions.txt
Then download the models: download sd_xl_base_1.0_0.9vae.safetensors from here as the file "Fooocus\models\checkpoints\sd_xl_base_1.0_0.9vae.safetensors", and download sd_xl_refiner_1.0_0.9vae.safetensors from here as the file "Fooocus\models\checkpoints\sd_xl_refiner_1.0_0.9vae.safetensors". Or let Fooocus automatically download the models using the launcher:
python launch.py
Or if you want to open a remote port, use
python launch.py --listen
- Supports custom styles in
settings/styles.csv - Changed Resolutions and Styles to be in a dropdown instead of radio buttons
- Apply multiple styles to one prompt and a send style to prompt button.
- Ability to save full metadata for generated images embedded in PNG.
- Ability to change default values of UI settings (loaded from
settings/settings.json). - Generate a completely random prompt (taken from onebuttonprompt) with its own "special" tab (now officially supported by Arljen)
- Made Resolutions mode readable
- Added theme support in
settings/settings.jsonyou can see available themes HERE - Added
settings/resolutions.jsonto allow users to add their own custom resolutions - Wildcards are now supported place see
wildcards\colors.txtfor an example. In your prompt make sure you type__<filename>__to activate ieshiny new __colors__ Chevrolet pickup truck with big wheels - If the option
--nobrowseris passed the web browser won't automatically launch - Added Custom paths in
settings/paths.jsonto point to chekcpoints / loras and outputs director (Note: for windows paths either use/or\\instead of\) - Added support for custom Performance - enables samplers/scheduler, steps, refiner steps, cfg & clip skip (Check advanced tab)
- Displays time taken for each render in the console. If
notification.mp3exists in the root directory, this will play when the generations are complete. - Added Cancel button to stop generation. Thanks to Yownas and MoonRide
- Pressing
Ctrl-Enteris the same as pressing the generate button! - Adds the ability to add loras to just prompt ala auto111 style eg
<lora:MyAwesomeLora-SL:0.90> - Drag and drop previous Ruined images to the main window, it will autofill the prompt with the generation metadata.
- The ability to post json metadata into the prompt window so you dont have to go into ANY settings tabs when you click generate. (Note: setting a seed of
-1will generate a random seed) - Render different subjects so you can process a whole list of prompts. Seperate each prompt by placing
---on a new line - Supports subdirectories for models/loras so you can get all organised!
- Add style:stylename to prompt to set the required style
- Controlnet! Check out the PowerUp tab, once selected you'll be able to upload your controlnet base image into a new special area in the tab
- Save your own custom perfomances and easily load them back in with the dropdown
- Create your own default ControlNet settings, or just get into the hardcore details with the custom PowerUp mode
- Image2Image mode is now active and available in the PowerUp tab
- Added Support for SSD-1B Models
- Automatically read triggerwords from <lora_filename>.txt just place a
.txtfile of the same name (minus the .safetensors) and it will read the triggerwords from the file - Upscaling using whatever upscaler you prefer
4xUltrasharpby default. Look for the new option in the powerup tab - Metadata Viewer now available in the
Infotab - Now supports the SDXL LCM LORA
- Generate Forever if Image Number is set to 0.
- Clip Interrogator, just drag your image onto the main image to generate the prompt
- Inpainting, Available in the
PowerUptab, simple check the box and it will either take a new image or the selected image in your gallery - Evolve, takes your current generation and evolves it into different variations, best used with a fixed seed!
- Support --auth=username/password for rudimentary security (Forced when using --share)
- Automatically downloads your Lora triggerwords from civit and displays them for you
- Automatic Negative prompt, save yourself the heartache and hassle of writing negative prompts!
- If the file
reinstallexists upgrade xformers and torch to 2.1.2 (to upgrade simply create a blank file calledreinstall) - Support LayerDiffuse PowerUp.
- New model/LoRA select with support for animated thumbnails.
- SD3 Support, make sure to use
sd3_medium_incl_clips.safetensors- Note: If the pictures look "strange" change to euler and simple - Use merge-files as checkpoints.
- MergeMaker in Models, where you can create your own merge-files/checkpoints
- Experimental support for diffusers and models from Huggingface
- RemBG PowerUp, remove background of images
- Img2STL PowerUp, convert images to .stl files for 3D printers
- Flux support.
- Support for GGUF Flux files and safetensors containing only Unet.
- Florence for image Interrogation
- Llama 3.2
This codebase is a fork from the original amazing work by lllyasviel The wonderful MoonRide who also maintains an amazing fork! The codebase starts from an odd mixture of Automatic1111 and ComfyUI. (And they both use GPL license.)
You can join our discord support server Here
The log is here.