![]()
![]()

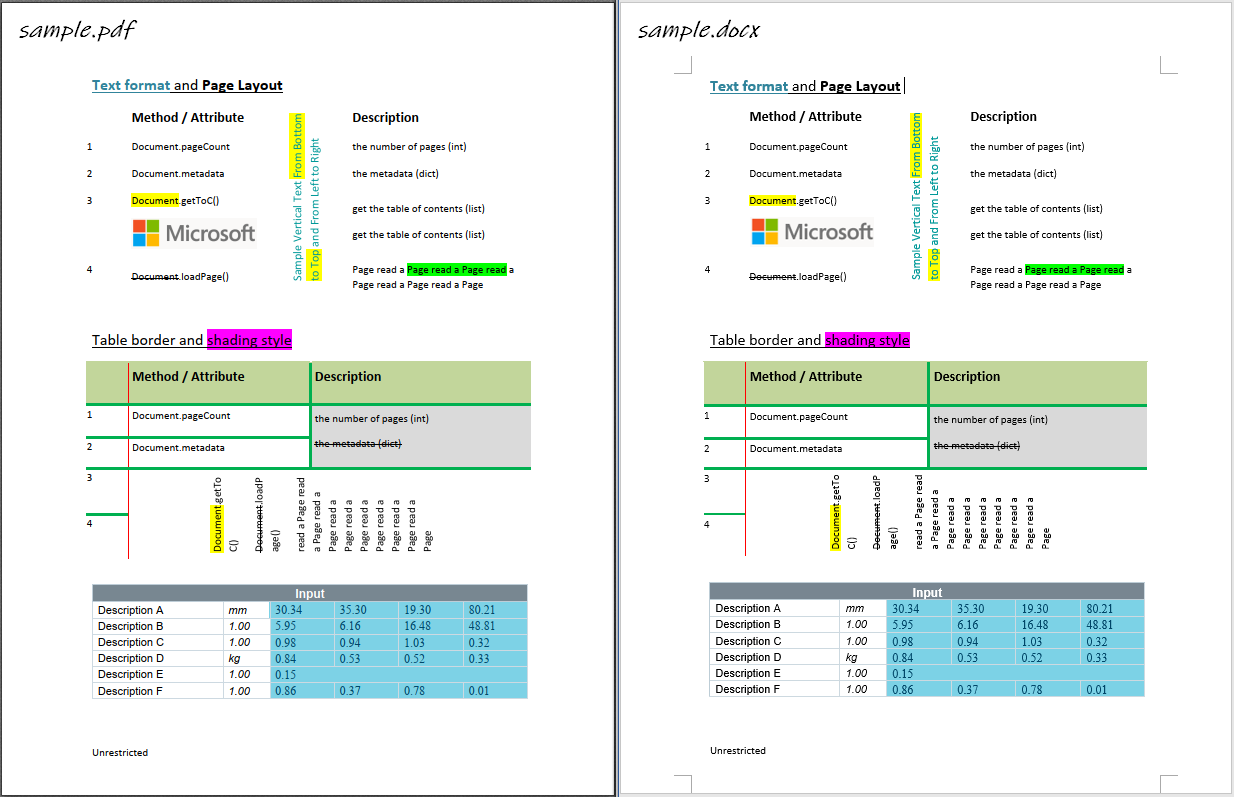
- Parse text, table and layout from PDF file with
PyMuPDF - Generate docx with
python-docx
-
Parse and re-create paragraph
- text in horizontal direction: from left to right
- text in vertical direction: from bottom to top
- font style, e.g. font name, size, weight, italic and color
- text format, e.g. highlight, underline, strike-through
- text alignment, e.g. left/right/center/justify
- list style
- paragraph layout: horizontal alignment and vertical spacing
-
Parse and re-create image
- in-line image
- image in Gray/RGB/CMYK mode
- transparent image
-
Parse and re-create table
- border style, e.g. width, color
- shading style, i.e. background color
- merged cells
- vertical direction cell
- table with partly hidden borders
-
Parsing pages with multi-processing
It can also be used as a tool to extract table contents since both table content and format/style is parsed.
- Text-based PDF file only
- Normal reading direction only
- horizontal/vertical paragraph/line/word
- no word transformation, e.g. rotation
- No floating images
$ pip install pdf2docx
Clone or download this project, and navigate to the root directory:
$ python setup.py install
Or install it in developing mode:
$ python setup.py develop
$ pip uninstall pdf2docx
$ pdf2docx --help
NAME
pdf2docx - Run the pdf2docx parser.
SYNOPSIS
pdf2docx PDF_FILE <flags>
DESCRIPTION
Run the pdf2docx parser.
POSITIONAL ARGUMENTS
PDF_FILE
PDF filename to read from
FLAGS
--docx_file=DOCX_FILE
DOCX filename to write to
--start=START
first page to process, starting from zero
--end=END
last page to process, starting from zero
--pages=PAGES
range of pages
--multi_processing=MULTI_PROCESSING
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
$ pdf2docx test.pdf test.docx --start=5 --end=10
$ pdf2docx test.pdf test.docx --pages=5,7,9
$ pdf2docx test.pdf --multi_processing=True
''' With this library installed with
`pip install pdf2docx`, or `python setup.py install`.
'''
from pdf2docx import parse
pdf_file = '/path/to/sample.pdf'
docx_file = 'path/to/sample.docx'
# convert pdf to docx
parse(pdf_file, docx_file, start=0, end=1)Or just to extract tables,
from pdf2docx import extract_tables
pdf_file = '/path/to/sample.pdf'
tables = extract_tables(pdf_file, start=0, end=1)
for table in tables:
print(table)
# outputs
...
[['Input ', None, None, None, None, None],
['Description A ', 'mm ', '30.34 ', '35.30 ', '19.30 ', '80.21 '],
['Description B ', '1.00 ', '5.95 ', '6.16 ', '16.48 ', '48.81 '],
['Description C ', '1.00 ', '0.98 ', '0.94 ', '1.03 ', '0.32 '],
['Description D ', 'kg ', '0.84 ', '0.53 ', '0.52 ', '0.33 '],
['Description E ', '1.00 ', '0.15 ', None, None, None],
['Description F ', '1.00 ', '0.86 ', '0.37 ', '0.78 ', '0.01 ']]