Description
tl;dr: Current IR generated by && chain too hard to optimize for LLVM and always compiles to chain of jumps.
I started of investigation of this from this Reddit thread about lack of using SIMD instructions in PartialEq implementations.
Current Rust PartialEq
I assumed that PartialEq implementation generates code like:
handwritten eq
pub struct Blueprint {
pub fuel_tank_size: u32,
pub payload: u32,
pub wheel_diameter: u32,
pub wheel_width: u32,
pub storage: u32,
}
impl PartialEq for Blueprint{
fn eq(&self, other: &Self)->bool{
(self.fuel_tank_size == other.fuel_tank_size)
&& (self.payload == other.payload)
&& (self.wheel_diameter == other.wheel_diameter)
&& (self.wheel_width == other.wheel_width)
&& (self.storage == other.storage)
}
}
<example::Blueprint as core::cmp::PartialEq>::eq:
mov eax, dword ptr [rdi]
cmp eax, dword ptr [rsi]
jne .LBB0_1
mov eax, dword ptr [rdi + 4]
cmp eax, dword ptr [rsi + 4]
jne .LBB0_1
mov eax, dword ptr [rdi + 8]
cmp eax, dword ptr [rsi + 8]
jne .LBB0_1
mov eax, dword ptr [rdi + 12]
cmp eax, dword ptr [rsi + 12]
jne .LBB0_1
mov ecx, dword ptr [rdi + 16]
mov al, 1
cmp ecx, dword ptr [rsi + 16]
jne .LBB0_1
ret
.LBB0_1:
xor eax, eax
retgodbolt link for handwritten Eq
It is quite ineffective because have 5 branches which probably can be replaced by few SIMD instructions.
State on Clang land
So I decided to look how Clang compiles similar code (to know, if there some LLVM issue). So I written such code:
clang code and asm
#include <cstdint>
struct Blueprint{
uint32_t fuel_tank_size;
uint32_t payload;
uint32_t wheel_diameter;
uint32_t wheel_width;
uint32_t storage;
};
bool operator==(const Blueprint& th, const Blueprint& arg)noexcept{
return th.fuel_tank_size == arg.fuel_tank_size
&& th.payload == arg.payload
&& th.wheel_diameter == arg.wheel_diameter
&& th.wheel_width == arg.wheel_width
&& th.storage == arg.storage;
}And asm
operator==(Blueprint const&, Blueprint const&): # @operator==(Blueprint const&, Blueprint const&)
movdqu xmm0, xmmword ptr [rdi]
movdqu xmm1, xmmword ptr [rsi]
pcmpeqb xmm1, xmm0
movd xmm0, dword ptr [rdi + 16] # xmm0 = mem[0],zero,zero,zero
movd xmm2, dword ptr [rsi + 16] # xmm2 = mem[0],zero,zero,zero
pcmpeqb xmm2, xmm0
pand xmm2, xmm1
pmovmskb eax, xmm2
cmp eax, 65535
sete al
retAlso, godbolt with Clang code.
As you see, Clang successfully optimizes the code to use SIMD instructions and doesn't ever generates branches.
Rust variants of good asm generation
I checked other code variants in Rust.
Rust variants and ASM
pub struct Blueprint {
pub fuel_tank_size: u32,
pub payload: u32,
pub wheel_diameter: u32,
pub wheel_width: u32,
pub storage: u32,
}
// Equivalent of #[derive(PartialEq)]
pub fn eq0(a: &Blueprint, b: &Blueprint)->bool{
(a.fuel_tank_size == b.fuel_tank_size)
&& (a.payload == b.payload)
&& (a.wheel_diameter == b.wheel_diameter)
&& (a.wheel_width == b.wheel_width)
&& (a.storage == b.storage)
}
// Optimizes good but changes semantics
pub fn eq1(a: &Blueprint, b: &Blueprint)->bool{
(a.fuel_tank_size == b.fuel_tank_size)
& (a.payload == b.payload)
& (a.wheel_diameter == b.wheel_diameter)
& (a.wheel_width == b.wheel_width)
& (a.storage == b.storage)
}
// Optimizes good and have same semantics as PartialEq
pub fn eq2(a: &Blueprint, b: &Blueprint)->bool{
if a.fuel_tank_size != b.fuel_tank_size{
return false;
}
if a.payload != b.payload{
return false;
}
if a.wheel_diameter != b.wheel_diameter{
return false;
}
if a.wheel_width != b.wheel_width{
return false;
}
if a.storage != b.storage{
return false;
}
true
}example::eq0:
mov eax, dword ptr [rdi]
cmp eax, dword ptr [rsi]
jne .LBB0_1
mov eax, dword ptr [rdi + 4]
cmp eax, dword ptr [rsi + 4]
jne .LBB0_1
mov eax, dword ptr [rdi + 8]
cmp eax, dword ptr [rsi + 8]
jne .LBB0_1
mov eax, dword ptr [rdi + 12]
cmp eax, dword ptr [rsi + 12]
jne .LBB0_1
mov ecx, dword ptr [rdi + 16]
mov al, 1
cmp ecx, dword ptr [rsi + 16]
jne .LBB0_1
ret
.LBB0_1:
xor eax, eax
ret
example::eq1:
mov eax, dword ptr [rdi + 16]
cmp eax, dword ptr [rsi + 16]
vmovdqu xmm0, xmmword ptr [rdi]
sete cl
vpcmpeqd xmm0, xmm0, xmmword ptr [rsi]
vmovmskps eax, xmm0
cmp al, 15
sete al
and al, cl
ret
example::eq2:
vmovdqu xmm0, xmmword ptr [rdi]
vmovd xmm1, dword ptr [rdi + 16]
vmovd xmm2, dword ptr [rsi + 16]
vpxor xmm1, xmm1, xmm2
vpxor xmm0, xmm0, xmmword ptr [rsi]
vpor xmm0, xmm0, xmm1
vptest xmm0, xmm0
sete al
retAnd godbolt link with variants
Function eq0 uses &&, eq1 uses & so has different semantics, eq2 has similar semantics but optimized better.
eq1 is very simple case (we have one block generated by rustc which easily optimized) and has different semantics so we skip it.
We would use eq0 and eq2 further.
Investigation of LLVM IR
clang and eq2 cases successfully proved that LLVM capable to optimization of && so I started to investigate generated LLVM IR and optimized LLVM IR. I decided to check differences of IR for clang, eq0 and eq2.
I would put first generated LLVM IR, its diagram, and optimized LLVM IR for cases. Also, I used different code in files than godbolt so function names aren't match for case names.
Clang IR
I compiled code to LLVM IR using clang++ is_sorted.cpp -O0 -S -emit-llvm, removed optnone attribut manually, then looked optimizations using opt -O3 -print-before-all -print-after-all 2>passes.ll
Code and diagrams
real code
#include <cstdint>
struct Blueprint{
uint32_t fuel_tank_size;
uint32_t payload;
uint32_t wheel_diameter;
uint32_t wheel_width;
uint32_t storage;
};
bool operator==(const Blueprint& th, const Blueprint& arg)noexcept{
return th.fuel_tank_size == arg.fuel_tank_size
&& th.payload == arg.payload
&& th.wheel_diameter == arg.wheel_diameter
&& th.wheel_width == arg.wheel_width
&& th.storage == arg.storage;
}So first generated LLVM IR
%struct.Blueprint = type { i32, i32, i32, i32, i32 }
; Function Attrs: noinline nounwind optnone uwtable
define dso_local zeroext i1 @_ZeqRK9BlueprintS1_(%struct.Blueprint* nonnull align 4 dereferenceable(20) %0, %struct.Blueprint* nonnull align 4 dereferenceable(20) %1) #0 {
%3 = alloca %struct.Blueprint*, align 8
%4 = alloca %struct.Blueprint*, align 8
store %struct.Blueprint* %0, %struct.Blueprint** %3, align 8
store %struct.Blueprint* %1, %struct.Blueprint** %4, align 8
%5 = load %struct.Blueprint*, %struct.Blueprint** %3, align 8
%6 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %5, i32 0, i32 0
%7 = load i32, i32* %6, align 4
%8 = load %struct.Blueprint*, %struct.Blueprint** %4, align 8
%9 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %8, i32 0, i32 0
%10 = load i32, i32* %9, align 4
%11 = icmp eq i32 %7, %10
br i1 %11, label %12, label %44
12: ; preds = %2
%13 = load %struct.Blueprint*, %struct.Blueprint** %3, align 8
%14 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %13, i32 0, i32 1
%15 = load i32, i32* %14, align 4
%16 = load %struct.Blueprint*, %struct.Blueprint** %4, align 8
%17 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %16, i32 0, i32 1
%18 = load i32, i32* %17, align 4
%19 = icmp eq i32 %15, %18
br i1 %19, label %20, label %44
20: ; preds = %12
%21 = load %struct.Blueprint*, %struct.Blueprint** %3, align 8
%22 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %21, i32 0, i32 2
%23 = load i32, i32* %22, align 4
%24 = load %struct.Blueprint*, %struct.Blueprint** %4, align 8
%25 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %24, i32 0, i32 2
%26 = load i32, i32* %25, align 4
%27 = icmp eq i32 %23, %26
br i1 %27, label %28, label %44
28: ; preds = %20
%29 = load %struct.Blueprint*, %struct.Blueprint** %3, align 8
%30 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %29, i32 0, i32 3
%31 = load i32, i32* %30, align 4
%32 = load %struct.Blueprint*, %struct.Blueprint** %4, align 8
%33 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %32, i32 0, i32 3
%34 = load i32, i32* %33, align 4
%35 = icmp eq i32 %31, %34
br i1 %35, label %36, label %44
36: ; preds = %28
%37 = load %struct.Blueprint*, %struct.Blueprint** %3, align 8
%38 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %37, i32 0, i32 4
%39 = load i32, i32* %38, align 4
%40 = load %struct.Blueprint*, %struct.Blueprint** %4, align 8
%41 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %40, i32 0, i32 4
%42 = load i32, i32* %41, align 4
%43 = icmp eq i32 %39, %42
br label %44
44: ; preds = %36, %28, %20, %12, %2
%45 = phi i1 [ false, %28 ], [ false, %20 ], [ false, %12 ], [ false, %2 ], [ %43, %36 ]
ret i1 %45
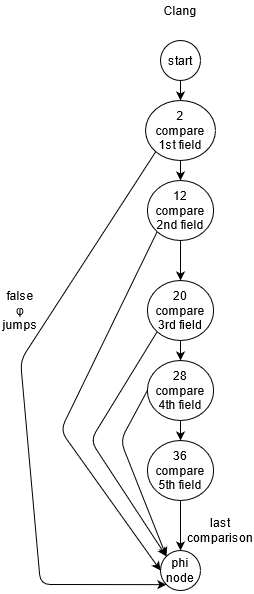
}Picture of control flow
Optimized LLVM
; Function Attrs: noinline norecurse nounwind readonly uwtable
define dso_local zeroext i1 @_ZeqRK9BlueprintS1_(%struct.Blueprint* nocapture nonnull readonly align 4 dereferenceable(20) %0, %struct.Blueprint* nocapture nonnull readonly align 4 dereferenceable(20) %1) local_unnamed_addr #0 {
%3 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %0, i64 0, i32 0
%4 = load i32, i32* %3, align 4
%5 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %1, i64 0, i32 0
%6 = load i32, i32* %5, align 4
%7 = icmp eq i32 %4, %6
br i1 %7, label %8, label %32
8: ; preds = %2
%9 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %0, i64 0, i32 1
%10 = load i32, i32* %9, align 4
%11 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %1, i64 0, i32 1
%12 = load i32, i32* %11, align 4
%13 = icmp eq i32 %10, %12
br i1 %13, label %14, label %32
14: ; preds = %8
%15 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %0, i64 0, i32 2
%16 = load i32, i32* %15, align 4
%17 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %1, i64 0, i32 2
%18 = load i32, i32* %17, align 4
%19 = icmp eq i32 %16, %18
br i1 %19, label %20, label %32
20: ; preds = %14
%21 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %0, i64 0, i32 3
%22 = load i32, i32* %21, align 4
%23 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %1, i64 0, i32 3
%24 = load i32, i32* %23, align 4
%25 = icmp eq i32 %22, %24
br i1 %25, label %26, label %32
26: ; preds = %20
%27 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %0, i64 0, i32 4
%28 = load i32, i32* %27, align 4
%29 = getelementptr inbounds %struct.Blueprint, %struct.Blueprint* %1, i64 0, i32 4
%30 = load i32, i32* %29, align 4
%31 = icmp eq i32 %28, %30
br label %32
32: ; preds = %26, %20, %14, %8, %2
%33 = phi i1 [ false, %20 ], [ false, %14 ], [ false, %8 ], [ false, %2 ], [ %31, %26 ]
ret i1 %33
}As you see, Clang original code doesn't changed much, it removed only copying from source structs to temporary locals.
Original control flow is very clear and last block utilizes single phi node with a lot of inputs to fill result value.
Rust eq2 case
I generated LLVM code using such command: rustc +nightly cmp.rs --emit=llvm-ir -C opt-level=3 -C codegen-units=1 --crate-type=rlib -C 'llvm-args=-print-after-all -print-before-all' 2>passes.ll
Rust eq2 case IR and graphs
real code
pub struct Blueprint {
pub fuel_tank_size: u32,
pub payload: u32,
pub wheel_diameter: u32,
pub wheel_width: u32,
pub storage: u32,
}
impl PartialEq for Blueprint{
fn eq(&self, other: &Self)->bool{
if self.fuel_tank_size != other.fuel_tank_size{
return false;
}
if self.payload != other.payload{
return false;
}
if self.wheel_diameter != other.wheel_diameter{
return false;
}
if self.wheel_width != other.wheel_width{
return false;
}
if self.storage != other.storage{
return false;
}
true
}
}It generates such IR:
; Function Attrs: nonlazybind uwtable
define zeroext i1 @"_ZN55_$LT$cmp..Blueprint$u20$as$u20$core..cmp..PartialEq$GT$2eq17h7ce388cf7c1072a4E"(%Blueprint* noalias readonly align 4 dereferenceable(20) %self, %Blueprint* noalias readonly align 4 dereferenceable(20) %other) unnamed_addr #0 {
start:
%0 = alloca i8, align 1
%1 = bitcast %Blueprint* %self to i32*
%_4 = load i32, i32* %1, align 4
%2 = bitcast %Blueprint* %other to i32*
%_5 = load i32, i32* %2, align 4
%_3 = icmp ne i32 %_4, %_5
br i1 %_3, label %bb1, label %bb2
bb1: ; preds = %start
store i8 0, i8* %0, align 1
br label %bb11
bb2: ; preds = %start
%3 = getelementptr inbounds %Blueprint, %Blueprint* %self, i32 0, i32 3
%_7 = load i32, i32* %3, align 4
%4 = getelementptr inbounds %Blueprint, %Blueprint* %other, i32 0, i32 3
%_8 = load i32, i32* %4, align 4
%_6 = icmp ne i32 %_7, %_8
br i1 %_6, label %bb3, label %bb4
bb3: ; preds = %bb2
store i8 0, i8* %0, align 1
br label %bb11
bb4: ; preds = %bb2
%5 = getelementptr inbounds %Blueprint, %Blueprint* %self, i32 0, i32 5
%_10 = load i32, i32* %5, align 4
%6 = getelementptr inbounds %Blueprint, %Blueprint* %other, i32 0, i32 5
%_11 = load i32, i32* %6, align 4
%_9 = icmp ne i32 %_10, %_11
br i1 %_9, label %bb5, label %bb6
bb5: ; preds = %bb4
store i8 0, i8* %0, align 1
br label %bb11
bb6: ; preds = %bb4
%7 = getelementptr inbounds %Blueprint, %Blueprint* %self, i32 0, i32 7
%_13 = load i32, i32* %7, align 4
%8 = getelementptr inbounds %Blueprint, %Blueprint* %other, i32 0, i32 7
%_14 = load i32, i32* %8, align 4
%_12 = icmp ne i32 %_13, %_14
br i1 %_12, label %bb7, label %bb8
bb7: ; preds = %bb6
store i8 0, i8* %0, align 1
br label %bb11
bb8: ; preds = %bb6
%9 = getelementptr inbounds %Blueprint, %Blueprint* %self, i32 0, i32 9
%_16 = load i32, i32* %9, align 4
%10 = getelementptr inbounds %Blueprint, %Blueprint* %other, i32 0, i32 9
%_17 = load i32, i32* %10, align 4
%_15 = icmp ne i32 %_16, %_17
br i1 %_15, label %bb9, label %bb10
bb9: ; preds = %bb8
store i8 0, i8* %0, align 1
br label %bb11
bb10: ; preds = %bb8
store i8 1, i8* %0, align 1
br label %bb11
bb11: ; preds = %bb10, %bb9, %bb7, %bb5, %bb3, %bb1
%11 = load i8, i8* %0, align 1, !range !2
%12 = trunc i8 %11 to i1
ret i1 %12
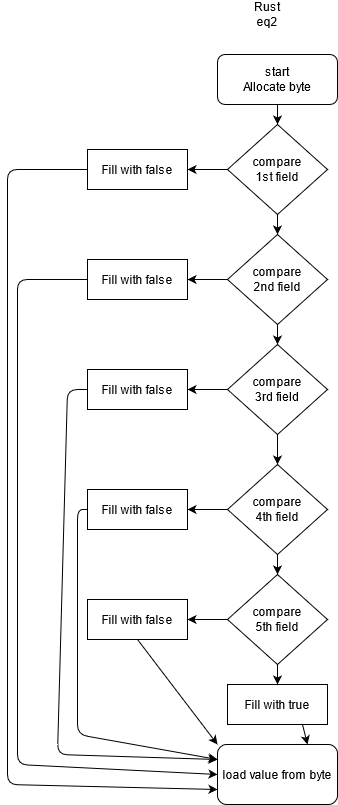
}Which can be described with such picture
And after optimizations it would end with:
; Function Attrs: norecurse nounwind nonlazybind readonly uwtable willreturn
define zeroext i1 @"_ZN55_$LT$cmp..Blueprint$u20$as$u20$core..cmp..PartialEq$GT$2eq17h7ce388cf7c1072a4E"(%Blueprint* noalias nocapture readonly align 4 dereferenceable(20) %self, %Blueprint* noalias nocapture readonly align 4 dereferenceable(20) %other) unnamed_addr #0 {
start:
%0 = getelementptr inbounds %Blueprint, %Blueprint* %self, i64 0, i32 0, i64 0
%_4 = load i32, i32* %0, align 4
%1 = getelementptr inbounds %Blueprint, %Blueprint* %other, i64 0, i32 0, i64 0
%_5 = load i32, i32* %1, align 4
%_3.not = icmp eq i32 %_4, %_5
br i1 %_3.not, label %bb2, label %bb11
bb2: ; preds = %start
%2 = getelementptr inbounds %Blueprint, %Blueprint* %self, i64 0, i32 3
%_7 = load i32, i32* %2, align 4
%3 = getelementptr inbounds %Blueprint, %Blueprint* %other, i64 0, i32 3
%_8 = load i32, i32* %3, align 4
%_6.not = icmp eq i32 %_7, %_8
br i1 %_6.not, label %bb4, label %bb11
bb4: ; preds = %bb2
%4 = getelementptr inbounds %Blueprint, %Blueprint* %self, i64 0, i32 5
%_10 = load i32, i32* %4, align 4
%5 = getelementptr inbounds %Blueprint, %Blueprint* %other, i64 0, i32 5
%_11 = load i32, i32* %5, align 4
%_9.not = icmp eq i32 %_10, %_11
br i1 %_9.not, label %bb6, label %bb11
bb6: ; preds = %bb4
%6 = getelementptr inbounds %Blueprint, %Blueprint* %self, i64 0, i32 7
%_13 = load i32, i32* %6, align 4
%7 = getelementptr inbounds %Blueprint, %Blueprint* %other, i64 0, i32 7
%_14 = load i32, i32* %7, align 4
%_12.not = icmp eq i32 %_13, %_14
br i1 %_12.not, label %bb8, label %bb11
bb8: ; preds = %bb6
%8 = getelementptr inbounds %Blueprint, %Blueprint* %self, i64 0, i32 9
%_16 = load i32, i32* %8, align 4
%9 = getelementptr inbounds %Blueprint, %Blueprint* %other, i64 0, i32 9
%_17 = load i32, i32* %9, align 4
%_15.not = icmp eq i32 %_16, %_17
ret i1 %_15.not
bb11: ; preds = %bb6, %bb4, %bb2, %start
ret i1 false
}In general, algorithm can be described as
- Allocate single byte in stack and store its reference
- In bad cases stores
falseinto the byte and jump to end. - In last check store last comparison into byte and jump to end
- return data from byte.
This indirect usage of byte is optimized in mem2reg phase to pretty SSA form and control flow remains forward only.
Rust eq0 case (which used in reality very often and optimizes bad)
IR code and control flow diagrams
Real code
pub struct Blueprint {
pub fuel_tank_size: u32,
pub payload: u32,
pub wheel_diameter: u32,
pub wheel_width: u32,
pub storage: u32,
}
impl PartialEq for Blueprint{
fn eq(&self, other: &Self)->bool{
(self.fuel_tank_size == other.fuel_tank_size)
&& (self.payload == other.payload)
&& (self.wheel_diameter == other.wheel_diameter)
&& (self.wheel_width == other.wheel_width)
&& (self.storage == other.storage)
}
}So, rustc generates such code:
; Function Attrs: nonlazybind uwtable
define zeroext i1 @"_ZN55_$LT$cmp..Blueprint$u20$as$u20$core..cmp..PartialEq$GT$2eq17h7ce388cf7c1072a4E"(%Blueprint* noalias readonly align 4 dereferenceable(20) %self, %Blueprint* noalias readonly align 4 dereferenceable(20) %other) unnamed_addr #0 {
start:
%_5 = alloca i8, align 1
%_4 = alloca i8, align 1
%_3 = alloca i8, align 1
%0 = alloca i8, align 1
call void @llvm.lifetime.start.p0i8(i64 1, i8* %_3)
call void @llvm.lifetime.start.p0i8(i64 1, i8* %_4)
call void @llvm.lifetime.start.p0i8(i64 1, i8* %_5)
%1 = bitcast %Blueprint* %self to i32*
%_7 = load i32, i32* %1, align 4
%2 = bitcast %Blueprint* %other to i32*
%_8 = load i32, i32* %2, align 4
%_6 = icmp eq i32 %_7, %_8
br i1 %_6, label %bb15, label %bb14
bb1: ; preds = %bb3
store i8 1, i8* %0, align 1
br label %bb4
bb2: ; preds = %bb3, %bb8
store i8 0, i8* %0, align 1
br label %bb4
bb3: ; preds = %bb8
%3 = getelementptr inbounds %Blueprint, %Blueprint* %self, i32 0, i32 9
%_19 = load i32, i32* %3, align 4
%4 = getelementptr inbounds %Blueprint, %Blueprint* %other, i32 0, i32 9
%_20 = load i32, i32* %4, align 4
%_18 = icmp eq i32 %_19, %_20
br i1 %_18, label %bb1, label %bb2
bb4: ; preds = %bb2, %bb1
call void @llvm.lifetime.end.p0i8(i64 1, i8* %_3)
%5 = load i8, i8* %0, align 1, !range !2
%6 = trunc i8 %5 to i1
ret i1 %6
bb5: ; preds = %bb7
store i8 1, i8* %_3, align 1
br label %bb8
bb6: ; preds = %bb7, %bb12
store i8 0, i8* %_3, align 1
br label %bb8
bb7: ; preds = %bb12
%7 = getelementptr inbounds %Blueprint, %Blueprint* %self, i32 0, i32 7
%_16 = load i32, i32* %7, align 4
%8 = getelementptr inbounds %Blueprint, %Blueprint* %other, i32 0, i32 7
%_17 = load i32, i32* %8, align 4
%_15 = icmp eq i32 %_16, %_17
br i1 %_15, label %bb5, label %bb6
bb8: ; preds = %bb6, %bb5
call void @llvm.lifetime.end.p0i8(i64 1, i8* %_4)
%9 = load i8, i8* %_3, align 1, !range !2
%10 = trunc i8 %9 to i1
br i1 %10, label %bb3, label %bb2
bb9: ; preds = %bb11
store i8 1, i8* %_4, align 1
br label %bb12
bb10: ; preds = %bb11, %bb16
store i8 0, i8* %_4, align 1
br label %bb12
bb11: ; preds = %bb16
%11 = getelementptr inbounds %Blueprint, %Blueprint* %self, i32 0, i32 5
%_13 = load i32, i32* %11, align 4
%12 = getelementptr inbounds %Blueprint, %Blueprint* %other, i32 0, i32 5
%_14 = load i32, i32* %12, align 4
%_12 = icmp eq i32 %_13, %_14
br i1 %_12, label %bb9, label %bb10
bb12: ; preds = %bb10, %bb9
call void @llvm.lifetime.end.p0i8(i64 1, i8* %_5)
%13 = load i8, i8* %_4, align 1, !range !2
%14 = trunc i8 %13 to i1
br i1 %14, label %bb7, label %bb6
bb13: ; preds = %bb15
store i8 1, i8* %_5, align 1
br label %bb16
bb14: ; preds = %bb15, %start
store i8 0, i8* %_5, align 1
br label %bb16
bb15: ; preds = %start
%15 = getelementptr inbounds %Blueprint, %Blueprint* %self, i32 0, i32 3
%_10 = load i32, i32* %15, align 4
%16 = getelementptr inbounds %Blueprint, %Blueprint* %other, i32 0, i32 3
%_11 = load i32, i32* %16, align 4
%_9 = icmp eq i32 %_10, %_11
br i1 %_9, label %bb13, label %bb14
bb16: ; preds = %bb14, %bb13
%17 = load i8, i8* %_5, align 1, !range !2
%18 = trunc i8 %17 to i1
br i1 %18, label %bb11, label %bb10
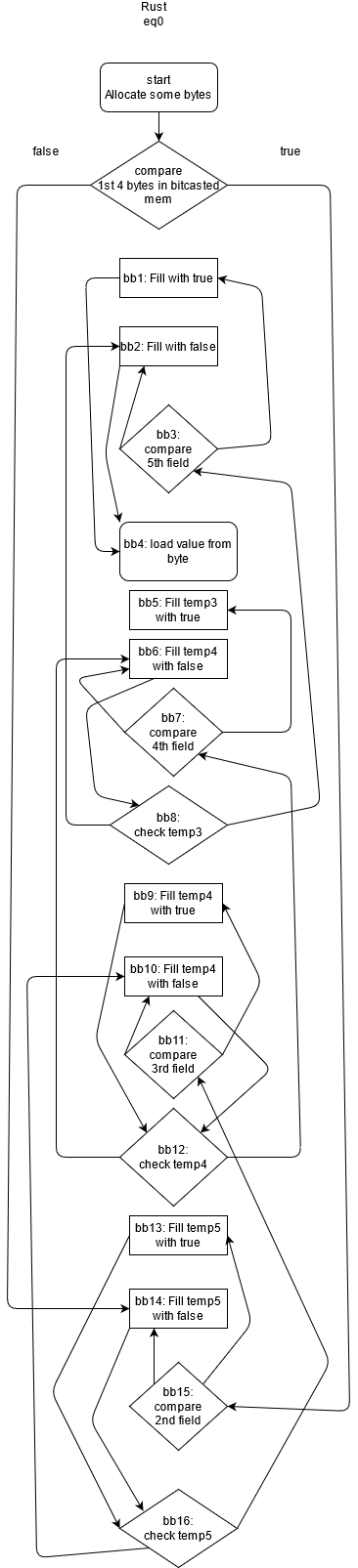
}Which has such control flow
And get optimized to this:
; Function Attrs: norecurse nounwind nonlazybind readonly uwtable willreturn
define zeroext i1 @"_ZN55_$LT$cmp..Blueprint$u20$as$u20$core..cmp..PartialEq$GT$2eq17h7ce388cf7c1072a4E"(%Blueprint* noalias nocapture readonly align 4 dereferenceable(20) %self, %Blueprint* noalias nocapture readonly align 4 dereferenceable(20) %other) unnamed_addr #0 {
start:
%0 = getelementptr inbounds %Blueprint, %Blueprint* %self, i64 0, i32 0, i64 0
%_7 = load i32, i32* %0, align 4
%1 = getelementptr inbounds %Blueprint, %Blueprint* %other, i64 0, i32 0, i64 0
%_8 = load i32, i32* %1, align 4
%_6 = icmp eq i32 %_7, %_8
br i1 %_6, label %bb15, label %bb2
bb2: ; preds = %start, %bb15, %bb11, %bb7, %bb3
br label %bb4
bb3: ; preds = %bb7
%2 = getelementptr inbounds %Blueprint, %Blueprint* %self, i64 0, i32 9
%_19 = load i32, i32* %2, align 4
%3 = getelementptr inbounds %Blueprint, %Blueprint* %other, i64 0, i32 9
%_20 = load i32, i32* %3, align 4
%_18 = icmp eq i32 %_19, %_20
br i1 %_18, label %bb4, label %bb2
bb4: ; preds = %bb3, %bb2
%.0 = phi i1 [ false, %bb2 ], [ true, %bb3 ]
ret i1 %.0
bb7: ; preds = %bb11
%4 = getelementptr inbounds %Blueprint, %Blueprint* %self, i64 0, i32 7
%_16 = load i32, i32* %4, align 4
%5 = getelementptr inbounds %Blueprint, %Blueprint* %other, i64 0, i32 7
%_17 = load i32, i32* %5, align 4
%_15 = icmp eq i32 %_16, %_17
br i1 %_15, label %bb3, label %bb2
bb11: ; preds = %bb15
%6 = getelementptr inbounds %Blueprint, %Blueprint* %self, i64 0, i32 5
%_13 = load i32, i32* %6, align 4
%7 = getelementptr inbounds %Blueprint, %Blueprint* %other, i64 0, i32 5
%_14 = load i32, i32* %7, align 4
%_12 = icmp eq i32 %_13, %_14
br i1 %_12, label %bb7, label %bb2
bb15: ; preds = %start
%8 = getelementptr inbounds %Blueprint, %Blueprint* %self, i64 0, i32 3
%_10 = load i32, i32* %8, align 4
%9 = getelementptr inbounds %Blueprint, %Blueprint* %other, i64 0, i32 3
%_11 = load i32, i32* %9, align 4
%_9 = icmp eq i32 %_10, %_11
br i1 %_9, label %bb11, label %bb2
}Well, it is really hard to tell whats going on in the generated code. Control flow operators placed basically in reversed order (first checked condition put in last position, then it jumps in both cases back than jumps against after condition), and such behaviour doesn't change during optimization passes and in final generated ASM we end with a lot of jumps and miss SIMD usage.
It looks like that LLVM fails to reorganize this blocks in more natural order and probably fails to understand many temporary allocas.
Conclusions of LLVM IR research
Let's look the control flow diagrams last time.
Clang:
Rust eq2 (with manual early returns)
Rust eq0 with usage of && operator.
Finally, I have 2 ideas of new algorithms which can be generated by proper codegen for && chains:
First approach
We need exploit φ nodes with lots of inputs from Clang approach:
Pseudocode:
b0:
if first_equation jump to b1 else to b_last
b1:
if second_equation jump to b2 else b_last
b2: ...
...
bn: if nth_equation: jump to b_true else b_last:
b_true: jump to b_last
b_last:
%result = phi i1 [false, b0], [false, b1], ..., [false, bn], [true, b_true]
Probably, it is the best solution because LLVM tends to handle Clang approach better and this code is already in SSA form which is loved by optimizations.
Second approach
Pseudocode
start:
%byte = allocate byte here
store %byte true
b0:
if first_equation jump to b2 else to b_false
b1:
if second_equation jump to b3 else to b_false
b2:
...
bn:
if nth_equation jump to b_last else to b_false
b_false:
store %byte false
b_last:
load %byte
This version is less friendly to the optimizer because we use pointer here but it would be converted to SSA form in mem2reg phase of optimization.
Implementing of such algorithms would probably require handling of chains of && operators as one prefix operator with many arguments e.g. &&(arg0, arg1, ..., argN).
I don't know which part of pipeline is needed to be changed to fix this and which my suggested generated code is easier to produce.
Also, very I expect same problem with || operator implementation too.
Importance and final thoughts
This bug effectively prevents SIMD optimizations in most #[derive(PartialEq)] and some other places too so fixing it could lead to big performance gains. Hope my investigation of this bug would help to fix it.
Also, sorry for possible weird wording and grammar mistakes because English isn't native language for me.
And finally, which rustc and clang I used:
$ clang++-11 --version
Ubuntu clang version 11.0.0-2~ubuntu20.04.1
Target: x86_64-pc-linux-gnu
Thread model: posix
InstalledDir: /usr/bin
$ rustc +nightly --version
rustc 1.53.0-nightly (07e0e2ec2 2021-03-24)