{kind=link}
In this code I inspect a WBC subtype dataset downloaded from Kaggle API, inspect whether if it's suited for Deep learning, if not, rectify the problems if possible and then design an optimum CNN for this task to identify and differentiate between 4 of the 5 WBC(White Blood Cells) subtypes.
- White blood cells (also called leukocytes or leucocytes and abbreviated as WBCs) are the cells of the immune system that are involved in protecting the body against both infectious disease and foreign invaders.
- These can be divided into the five main subtypes: neutrophils, eosinophils (acidophiles), basophils, lymphocytes, and monocytes.
- Automated and fast classification, counting and filtering can help identify and prevent many diseases.
- The Dataset was downloaded from open-domain using Kaggle API.
- The Dataset contains 4 of the 5 WBC subtypes, namely Neutrophils, Eosinophils, Lymphocytes, and Monocytes.
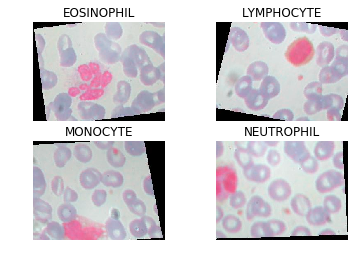
- These categories contains 88, 33, 21, and 207 images respectively.
- The dataset has two problems:
- Sparse Dataset.
- Class Imbalance.
- To tackle this we use data augmentation, after augmentation each category contains approx. 3000 class each.
-
The framework used is PyTorch.
-
To train I created a novel architecture Depth-Seperable Wide ResNets from combining techniques from three papers.
- MobileNets
- ResNets
- Wide ResNets
-
I used ADAM optimizer while I wish to replace that in the future iterations.
-
To Downsample I used Stride 2 Convolutions instead of MaxPool which I learned from DCGANs paper, this intuitively feels much natural way to downsample than hard maxpool.
-
To check the power and capacity of architecture I have learned my own trick with experience. I remove any sort of regularization and train the network overfits completely this means that network works, can learn well and has enough capacity for the given dataset.
-
With this technique, train accuracy soon converged to over 99.68% in mere 2 epochs, this meant that the model is working and is sufficient.
-
Putting back all the regularization so now it can generalize for the new data.