New architecture proposal
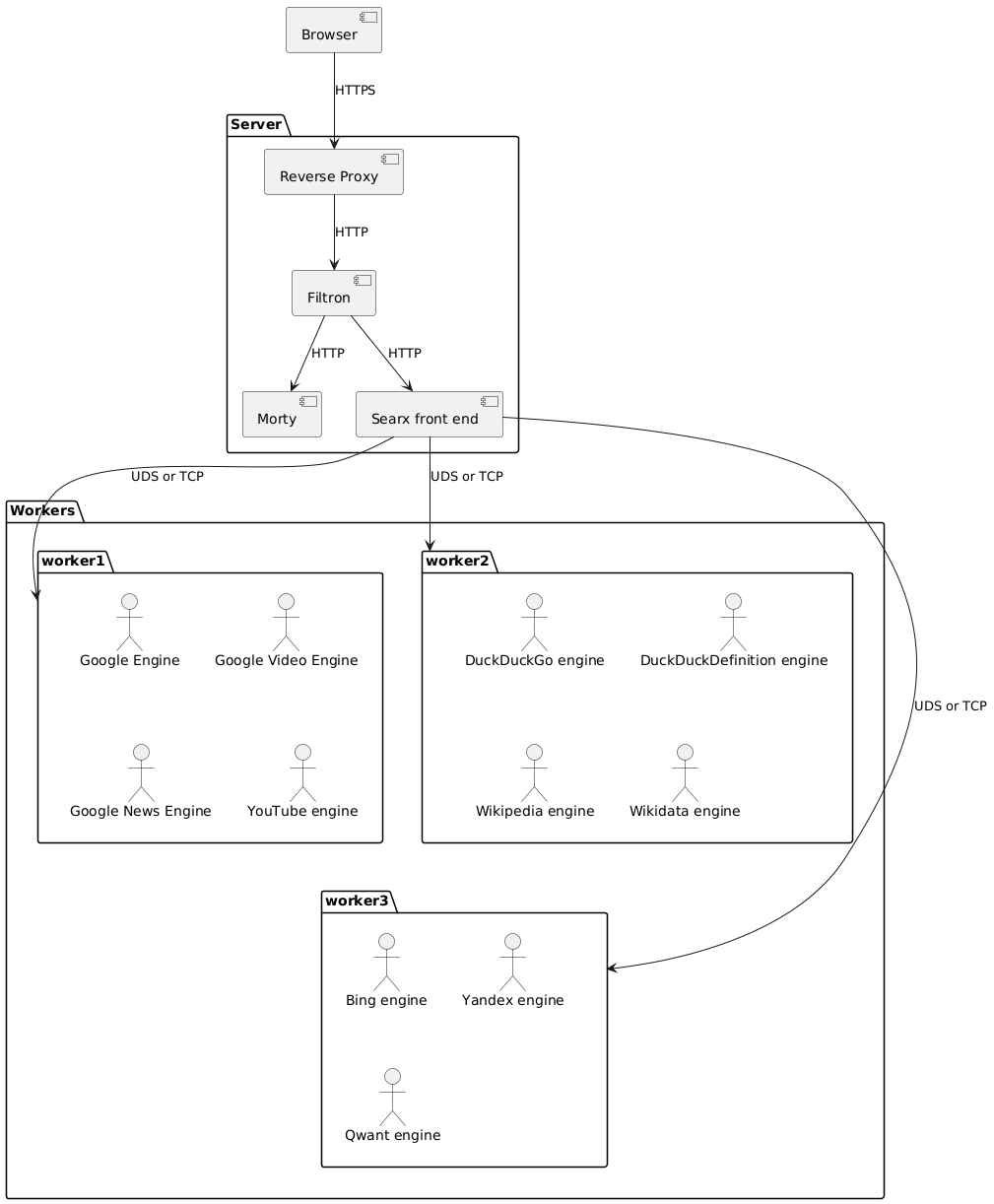
Each worker is a Python process started when searx is started and keep running as long the instance is running. It is either:
- a AGSI application (use starlette)
- a simple UDS server
- perhaps late a WebSocket server. Purpose: put the worker on a different host and use only HTTP request between the front-end and backend.
For sure there is an overhead (note: current implementation create a new thread per engine and per user request). A worker provide an internal API allows the "Searx front end" to:
- send a SearchQuery and get the results
- get the statistics.
Each worker:
- has it own HTTPS connection pool, and keep statistics.
- is dedicated to some engines. Engines from the same company are grouped on the same worker to use the same HTTP connection pool.
- most probably settings.yml will allow to configure this.
This architecture:
- solves the issue share data between uwsgi workers #1813: there is no need to share data.
- allows to use sympy: sympy runs inside a worker, if it crashes, the process can be killed.
- allows a worker to be implemented in any languages (or to use already existing code )
- may allow to skip Morty for the image proxy (if the performance are good enough).
- makes the setup easier: no need to install / configure uwsgi.
But:
- the templates are executed on the front-end (make sense actually).
- if for some reason a worker is killed and restarted, the statistics are lost. Same problem if there are different workers spread over different locations.
- the plugins are executed on the front-end.
In the current implementation (or this PR), the plugins are executed in this order:
- call pre_search plugins.
- call the engines, merge the results.
- call the on_result plugins.
- call the post_search plugins.
This PR rewrites the URL of Youtube and Twitter to use Invidious and Nitter respectively. Now if a user search for some videos, the results may contains some YouTube links and Invidious links. The results won't be merged, then the on_result plugins will rewrite the YouTube links, and may create duplicate results.
The only way to this, is to execute the on_result plugins on each workers.
Related to the issue #1225
The idea is to have a dedicated module to provide a stable API to the engine implementation:
- how to make a request.
- how to parse HTML and JSON.
The purpose is to implement this issue: Engine code: describe which XPath can fail, which must not. #1802. Then to get some statistics about which engine, XPath query and JSON query fail (in percentage). And if there is no privacy issue, searx.space can collect the different statistics to detect more easily which engines is (about to fail|failing).
requests doesn't provide an async API.
The other choices:
- pycurl will be a mess because of the different libcurl version / implementation. And it will be a lot of work to maintain the code.
- aiohttp. This is the choice of my-spot (a fork of searx).
- httpx.
I would go for httpx because the code is super clean even it seems slower on this microbenchmark.
Two third parties add socks5 proxy support:
- https://github.com/encode/httpx/issues/203
- https://github.com/romis2012/httpx-socks
There is a PR about source IP selection.
Perhaps a watchdog is requires to make sure all worker are up and running (a dedicated process). Example: a process doesn't eat all the CPU resources (like sympy can do). It is not requires as a first step.
The front-end is an AGSI application and run with starlette.
Purposes:
- answer user query:
- parse the user query
- dispatch them to the workers
- render using jinja2 template.
- provide an API to get the statistics:
- get the statistics from each worker
- merge them
- return the merged result
- image proxy (or if the performance are not good enough, remove it and rely on Morty). Link to the current implementation for reference
- deliver the static files (even if a reverse proxy can take over this task).
- deal with the localization.