feat: connect traces to semgrep rpc process #95
Conversation
This stack of pull requests is managed by Graphite. Learn more about stacking. |

b3df907 to
68e079e
Compare
022ad07 to
560bd7b
Compare
68e079e to
a292fcd
Compare
560bd7b to
aa70e5b
Compare
a292fcd to
f96dba9
Compare
aa70e5b to
dda0f6c
Compare
a5b7303 to
d1fb1c2
Compare
dda0f6c to
7282056
Compare
src/semgrep_mcp/semgrep.py
Outdated
| env["SEMGREP_LOG_SRCS"] = "mcp,commons" | ||
| if top_level_span: | ||
| env["SEMGREP_TRACE_PARENT_SPAN_ID"] = trace.format_span_id( | ||
| top_level_span.get_span_context().span_id | ||
| ) | ||
| env["SEMGREP_TRACE_PARENT_TRACE_ID"] = trace.format_trace_id( | ||
| top_level_span.get_span_context().trace_id | ||
| ) |
There was a problem hiding this comment.
Couple of questions:
- Does
semgrepCLI read these variables? - How would this work with the RPC-based implementation? Should we align with the work there first?
There was a problem hiding this comment.
Yes! semgrep links spans by reading these variables. The variables are defined here.
There was a problem hiding this comment.
Thanks for clarifying!
How would this change with the new rpc implementation? So you know?
There was a problem hiding this comment.
currently, i enable tracing only when we start up the ocaml mcp process. then, when the user invoke the semgrep_scan_rpc tool, we perform the rpc call while passing the tracing info through these env vars to the ocaml mcp process so the spans can be linked!
There was a problem hiding this comment.
Sorry, I realize I have not provided enough context.
When using this semgrep rpc, I believe the strategy is to start a single semgrep mcp process thst will run in background and accept rpc calls.
If we use env variables, then the process will use the same trace.id and span.id for every call. I don't think this is what we want.
Evry rpc call should get it's own span.id/trace.id as they belong to a different transaction, right?
Am I missing something on how this is currently implemented in semgrep?
There was a problem hiding this comment.
my understanding is that server_lifespan gets triggered every time a user starts a session (e.g. when they open cursor), and we will then create a semgrep mcp process per session. so, we will have one mcp (python) server, which spins up multiple semgrep mcp processes.
There was a problem hiding this comment.
my understanding is that
server_lifespangets triggered every time a user starts a session (e.g. when they open cursor), and we will then create asemgrep mcpprocess per session. so, we will have onemcp(python) server, which spins up multiplesemgrep mcpprocesses.
This is correct. However, for obeservability, you'd normally prefer to have a new transaction, per operation. This allows for analyzing requests independently.
If we use the same transaction and span for the whole session, that means we will see all calls done by the agent under the same view and analysis on the observability cluster.
Again, I may be missing something about how this was implemented in semgrep mcp as I'm too familiar with the CLI:
- Are you familiar with the implementation?
- Do you have examples of how the transactions look like once ingested by an observability cluster?
There was a problem hiding this comment.
based on my current implementation, it is true that you will see all the calls to the tool under one top-level span. but you can still see the individual spans separately.
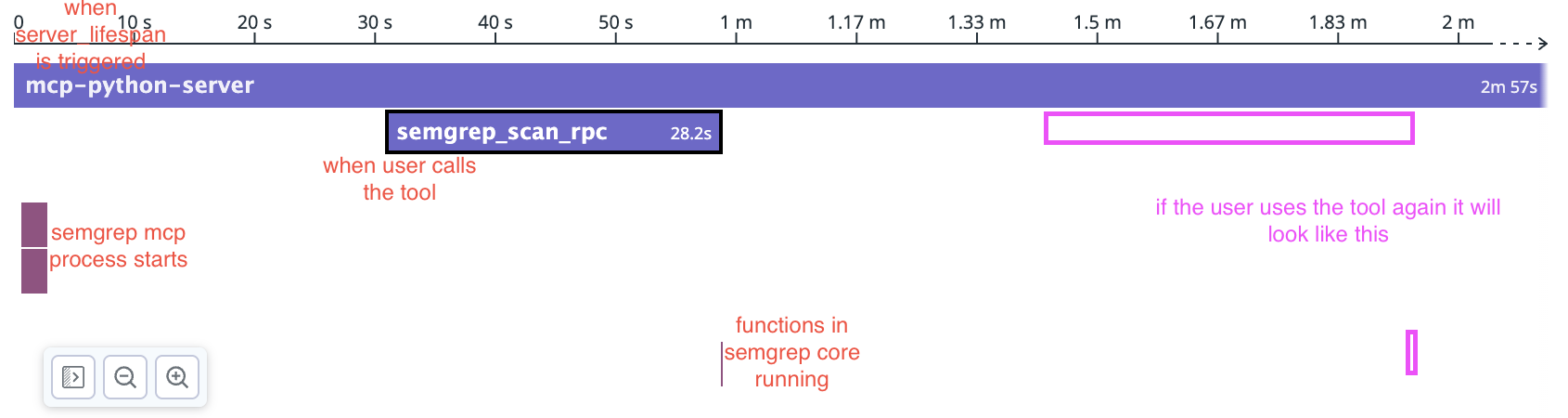
i can also look at these individual spans, the top-level span simply serves as a way for us to identify that these spans come from the same session.

i am not super familiar with tracing in general, is there a reason why separating them would make it better?
i am familiar with the semgrep mcp implementation. and i think it is still doable if we want to separate the spans and not nest them under one top-level span. i would just have to initialize a new trace and pass the env var in every time i make an rpc call (instead of using the same trace info). i can also update the tracing on the semgrep mcp side to start a top-level scan per rpc call instead of per mcp process.
There was a problem hiding this comment.
i am not super familiar with tracing in general, is there a reason why separating them would make it better?
i am familiar with the
semgrep mcpimplementation. and i think it is still doable if we want to separate the spans and not nest them under one top-level span. i would just have to initialize a new trace and pass the env var in every time i make an rpc call (instead of using the same trace info). i can also update the tracing on thesemgrep mcpside to start a top-level scan per rpc call instead of per mcp process.
I think this is what we want. The reason being that every call we make is a separate transaction, since it's a different operation run by the user. Think of this as an HTTP request to a server. Every time the agent users semgrep MCP, it is essentially doing an entire new request, which should have its own trace.id and span group.
7282056 to
954aa0f
Compare
635f1ae to
de12f0e
Compare
bb3b49a to
15cf5dc
Compare
b40ba32 to
573cd89
Compare
573cd89 to
34c2f92
Compare
|
Although the code for tracing on the |
What:
This PR lets us nest spans from the semgrep rpc process under spans for this mcp server.
How:
We pass in the span id and the trace id to the process through environment variables.
Test plan:
You can see the traces nesting properly on Datadog!

(Edit: sometimes the the top-level trace disappears...)