This is the repository which contains our code for our DL4CV final project. Our project aims to allow users to develop an end to end architecture which allows users create their own story. We develop a deep learning based model which is used to get the captions for an image. These captions are then fed into a GPT3 model, which then generates the corresponding story.

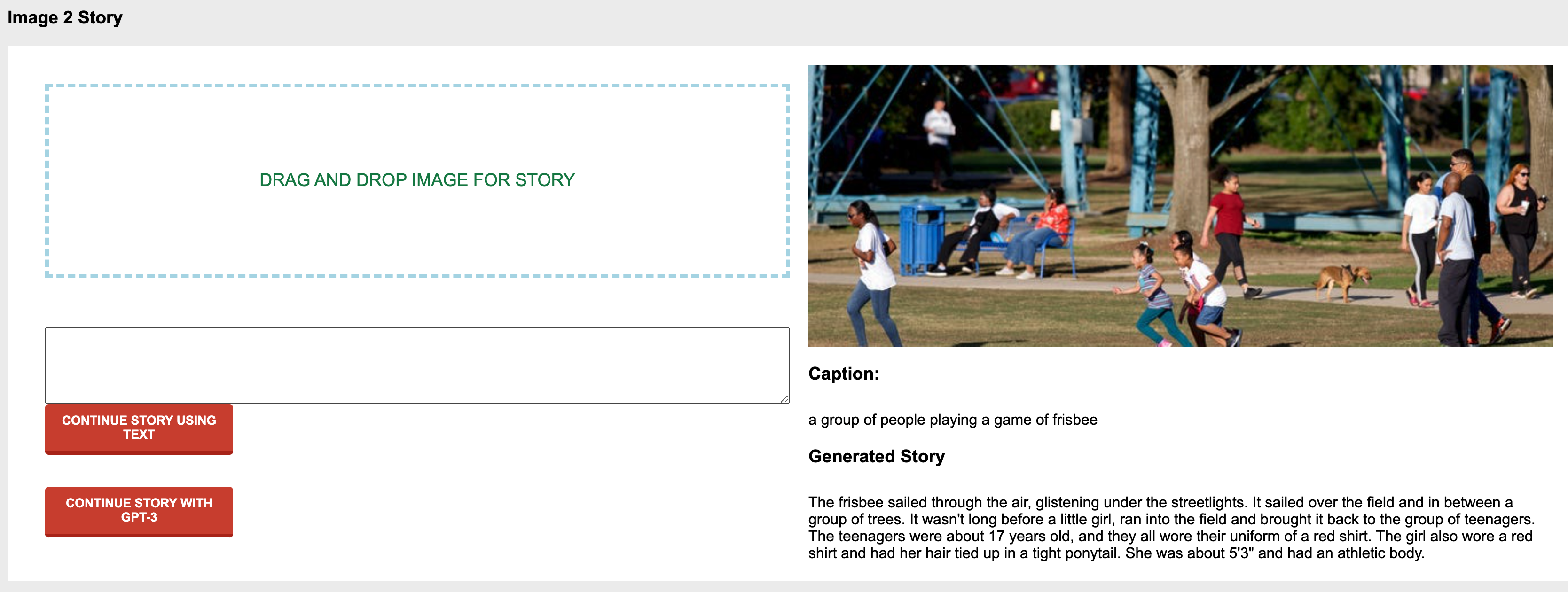
The user is able to:
-
spearhead the story by feeding in a new image
-
continue the story
-
Continue the story by uploading a new image and thus changing the direction of the story
-
Use your own text to change the direction of the story
There are 2 main folders in our repository:
-
Model: This directory contains the code to run and train the image captioning models. Our work is based on the Show, Attend and Tell Paper with quite significant modifications which we describe in the report
-
App: This directory contains the code for the full stack architecture. It is being run using flask in the backend and HTML, Css and Vanilla JS in the frontend.
A list of python modules that our environment was using during the development can be found in requirements.txt. I've also
shared the conda environment's yml file in case you want to use the exact
same environment as us NOTE: A lot of them might be unnecessary but if you install these, you'd be fine
If the above don't suite you and you're a control freak, I'm listing the modules which I can think from the top of my mind:
- flask
- pytorch
- torchvision
- matplotlib
- pandas
- numpy
- scipy
- nltk
- bcolz
- json
- pickle
Note: There are places in our code where we've hardcoded the directories. You will need to change those to run. They're notably present in train_*.py files and decoder_with_attention.py
The first step to train the image captioning model is to download the dataset. We're using MSCOCO dataset for training the image
captioning model. You'll need to download the Training set and the Validation set.
We've assumed that the train and test data has been put in 2 separate directories titled train2014 and val2014 and both these directories are present in a parent directory titled caption_data
Andrej Karpathy's training, validation and test splits for the captions would also need to be put in this directory. This zip file contains the captions.
To get the word embeddings, we're using glove embeddings; so those need to be downloaded as well. You can find the zip file over here. We've used the glove.6b.zip and the one which has 300 dimensions after the extraction.
Change the hardcoded path for the datset and the glove embeddings as described in the note above.
Once this is done, you're almost ready to go!
After completing the above steps, we are ready to train the model. We trained the model on a really powerful IBM Cloud machine. The model was trained on 2 Tesla V100-PCIE-32G GPUs (each of which costs over 10 grand on Amazon!). Given the huge size of the dataset, it was impossible to use our local machines - even training on the cloud took almost a day.
As mentioned before, our image captioning is based on the work mentioned of the paper Show, Attend and Tell. We also used 2 github repositories - first and second to develop our code.
Notably, our work differs from the show, attend and tell in the following ways:
-
We finetuned different encoders in order to train our model - Resnet, Wide ResNet, ResNeSt, DenseNet, Squeezenet, Mobilenet, Shufflenet. Our motivation for training Squeezenet, Mobilenet, Shufflenet: These models are highly compact, with a relatively low parameter space. We wanted to experiment and train such nets which would give us the ability to run most of our Img2Story model on device (on the edge) in exchange for slightly lower performance. The results (BLEU score) along with training hyperparameters are described in the report.
-
We use glove word embeddings to initilize the embedding matrix in the LSTM cell of the decoder
-
The paper mentions soft attention and hard attention - we use soft attention just because it is differentiable.
-
We enable our LSTM cell output layer as well as Attenion model weight update layer to learn more complicated function approximators by introducing additional fully connected layers
There are several files in the Model directory. On a high level,
decoder_with_attention.py contains the code to create the decoder module.
As mentinoned before, we tried to various different architectures for the encoders. Each of them are present in the files titled as encoder_[architecture].py. To train the different models, we created different train files - each titled train_[encoder_architecture].py.
To train the model, all you need to do is:
-
Change the code specifying if the device to be used for training (cpu or the gpu number)
-
Run
python train_[encoder_architecture].py
We highly recommend the usage of a powerful computer given how enormous the model and the data is
The code for the full stack architecture is present in the directory app. It is based on flask and is assuming that the we have pretrained weights of the image captioning model available as a .pth file. This pretrained weight file has been hardcoded inside the file predictor_api.py. You will need to provide your own pretrained weight file's path in here.
Once this has been done, all that you need to do is run the flask app.
export FLASK_APP=captioning.py
python -m flask run
NOTE: You will also need to provide your own GPT3 api key in gpt3_functions.py. GPT3 is not publicly available right now. You can request one at openAI or if you wish to run the entire system locally, please reach out to me (Jaidev, js5161@columbia.edu) and I can temporarily lend you mine. We have made available, as an alternative, a live publicly hosted version of our system hosted on my Cloud GPU (Link in next Section)
Public url: http://3e3952d5b604.ngrok.io/
A working final demo video of the end to end full stack system after training can be found in this youtube video
Team Presentation Video: https://youtu.be/fwgrLuLqBe0
Slides: https://docs.google.com/presentation/d/16LKtssldO2Xm4qC24-YURQKGYFyw_61KUHK77y_VH88/edit?usp=sharing