{kind=link}
NNDial is an open source toolkit for building end-to-end trainable task-oriented dialogue models. It is released by Tsung-Hsien (Shawn) Wen from Cambridge Dialogue Systems Group under Apache License 2.0.
In order to run the program, here are a list of packages with the suggested versions,
- Theano 0.8.2
- Numpy 1.12.0
- Scipy 0.16.1
- NLTK 3.0.0
- OpenBLAS
- NLTK stopwords corpus
- NLTK wordnet
The dataset is the CamRest676 dataset collected in Wen et al, 2017a. The dataset is public available at: https://www.repository.cam.ac.uk/handle/1810/260970
The model can be roughtly divided into encoder and decoder modules.
* The encoder modules contain:
- LSTM encoder : an LSTM network that encodes the user utterance.
- RNN+CNN tracker : a set of slot trackers that keep track of each slot/value pair across turns.
- DB operator : a discrete database accessing component.
* The decoder modules contain:
- Policy network : a decision-making module that produces the conditional vector for decoding.
- LSTM decoder : an LSTM network that generates the system response.
This software encloses the work from three publications, Wen et al, 2016, 2017a, 2017b. The models/methods supported in this software are listed below,
- The NDM model with a deterministic policy network (Wen et al 2017a).
- The Attention-based NDM model (Wen et al 2017a).
- Various decoder implementations and snapshot learning (Wen et al 2016).
- The LIDM model with a latent policy network and Reinforcement Learning (Wen et al 2017b).
The models were updated and refactored several times therefore some discrepancies in numbers are expected. Major changes since the earliest versions are:
- Optimiser has been changed from SGD to Adam.
- Encoder has been changed from uni-directional LSTM to bi-directional.
- An additional positive bias term has been added to the initialisation of all LSTM forget gates.
- Implementation of N-gram based trackers and CNN encoder has been removed for maintainence reason.
- MMI decoding has been removed because the gain was negligible.
Below are configuration parameters explained by sections:
* [learn] // hyperparamters for model learning
- lr : initial learning rate of Adam.
- lr_decay : learning rate decay.
- stop_count : the maximum of early stopping steps.
the maximum number of times when validation gets worse.
- cur_stop_count: current early stopping step.
- l2 : l2 regularisation weight.
- random_seed : random seed.
- min_impr : the relative minimal improvement allowed.
- debug : debug flag. // not properly implemented
- llogp : log prob in the last epoch.
- grad_clip : gradient clipping parameter.
* [file] // file paths
- db : database file.
- ontology : ontology, which defines the value scope of each slot.
if no values are specified, the values will be automatically loaded from DB.
- corpus : the corpus file for training the model.
- semi : semantic dictionary for delexicalisation.
- model : the path of the produced model file.
* [data] // data manipulation
- split : the proportion of data in training, validation, and testing sets.
- percent : the percentage of train/valid used.
- shuffle : shuffle mode, either static or dynamic
static: typical shuffling, do not reassign training and validation sets.
dynamic: when shuffling, shuffle the entire training+validation set and re-divide the two sets.
this is the trick to get better tracking performance on a small dataset.
- lengthen : either 0 or 1
0 : do not lengthen the dialogue. Default option.
1 : lengthen the dialogue by appending one randomly selected dialogue from the training set.
this is the trick to get better tracking performance on a small dataset.
* [mode] // training mode: trk|encdec|all
- learn_mode : the mode of training.
trk : pre-train the trackers
encdec: train the model except the trackers.
all : train the entire model jointly, not properly tested/implemented.
* [n2n] // components of network
- encoder : the encoder type.
- tracker : the tracker type.
- decoder : the decoder type.
* [enc] // structure of encoder
- ihidden : the size of the encoder hidden layer.
* [trk] // structure of tracker
- informable : whether to use informable trackers. Default yes.
- requestable : whether to use requestable trackers. Default yes.
- belief : the belief state type used for decoding. Best choice: summary.
- trkenc : tracker encoder type. Default cnn.
- wvec : pre-trained word vectors. Default none.
* [dec] // structure of decoder
- ohidden : the size of the decoder hidden layer
- struct : the decoder structures. Types are [lstm_lm|lstm_cond|lstm_mix].
Please check Wen et al, 2016 for more detail.
- snapshot : whether to use snapshot learning.
- wvec : pre-trained word vectors.
* [ply] // structure of policy network
- policy : the policy network type.
normal : a simple MLP.
attention : an MLP w/ attention mechansim on tracker outputs.
latent : the latent policy, used in LIDM.
- latent : the latent action space, used in LIDM only.
* [gen] // generation, repeat penalty: inf|none
- alpha : the weight for additional reward during decoding.
- verbose : verbose level. // not properly implemented
- topk : decode up to "topk" responses.
- beamwidth : the beamwidth during decoding.
- repeat_penalty: the additional penality when encoutering repeating slot tokens.
- token_reward : a heuristic reward used in Wen et al, 2017a.
The training of the model is done in two steps. Firstly, train the belief tracker using a tracker config file,
// Run the tracker training first
python nndial.py -config config/tracker.cfg -mode train
Now train an NDM based on the pre-trained tracker,
// Copy the pre-trained tracker model, and continue to train the other parts
cp model/CamRest.tracker-example.model model/CamRest.NDM.model
python nndial.py -config config/NDM.cfg -mode adjust
Once you have the model trained, you can validate or test its performance,
// Run the evaluation on the validation set for model selection
python nndial.py -config config/NDM.cfg -mode valid
// Run the evaluation on the test set to access the model performance
python nndial.py -config config/NDM.cfg -mode test
Or interact with it directly to see how it does,
python nndial.py -config config/NDM.cfg -mode interact
If you want an attention-based NDM model, just modified the config file,
cp model/CamRest.tracker-example.model model/CamRest.Att-NDM.model
python nndial.py -config config/Att-NDM.cfg -mode adjust
Or you can train an LIDM using semi-supervised variational inference,
cp model/CamRest.tracker-example.model model/CamRest.LIDM.model
python nndial.py -config config/LIDM.cfg -mode adjust
You can also choose to refine the LIDM policy network by corpus-based RL,
cp model/CamRest.LIDM.model model/CamRest.LIDM-RL.model
python nndial.py -config config/LIDM-RL.cfg -mode rl
The commands listed here are just examples. Please refer to scp/example_run.sh for more detail. Note, each new config file could change the intended model architecture, therefore, prompt the model to re-initiate the model parameters. For example, when training trackers it doesn't matter the structure of decoder and encoder because we can change it in the next config file.
The following benchmark results were produced by this software. We ran a small grid search over various hyperparameter settings and reported the performance of the best model on the test set. The selection criterion was success+0.5*BLEU on the validation set. The hyperparameters we were searching are,
- Initial learning rate. For NDM we searched over [0.008,0.010,0.012] while for LIDM we searched over [0.002,0.004,0.006].
The range of LIDM is lower than NDM simply because NVI requires a smaller learning rate in the beginning for efficient inference.
- L2 regularisation. We searched over [0.0, 1e-4, 1e-5, 1e-6].
- Random seed. We searched over [1, 2, 3, 4, 5].
To produce the exact numbers below, make sure you have the correct version of the following packages.
- Theano 0.8.2
- Numpy 1.12.0
- Scipy 0.16.1
- NLTK 3.0.0
Also, make sure you link your BLAS to OpenBLAS. We did observe different numbers when using different BLAS linkage. Example scripts for generating the config files for the experiments can be found at scp/batch_script/.
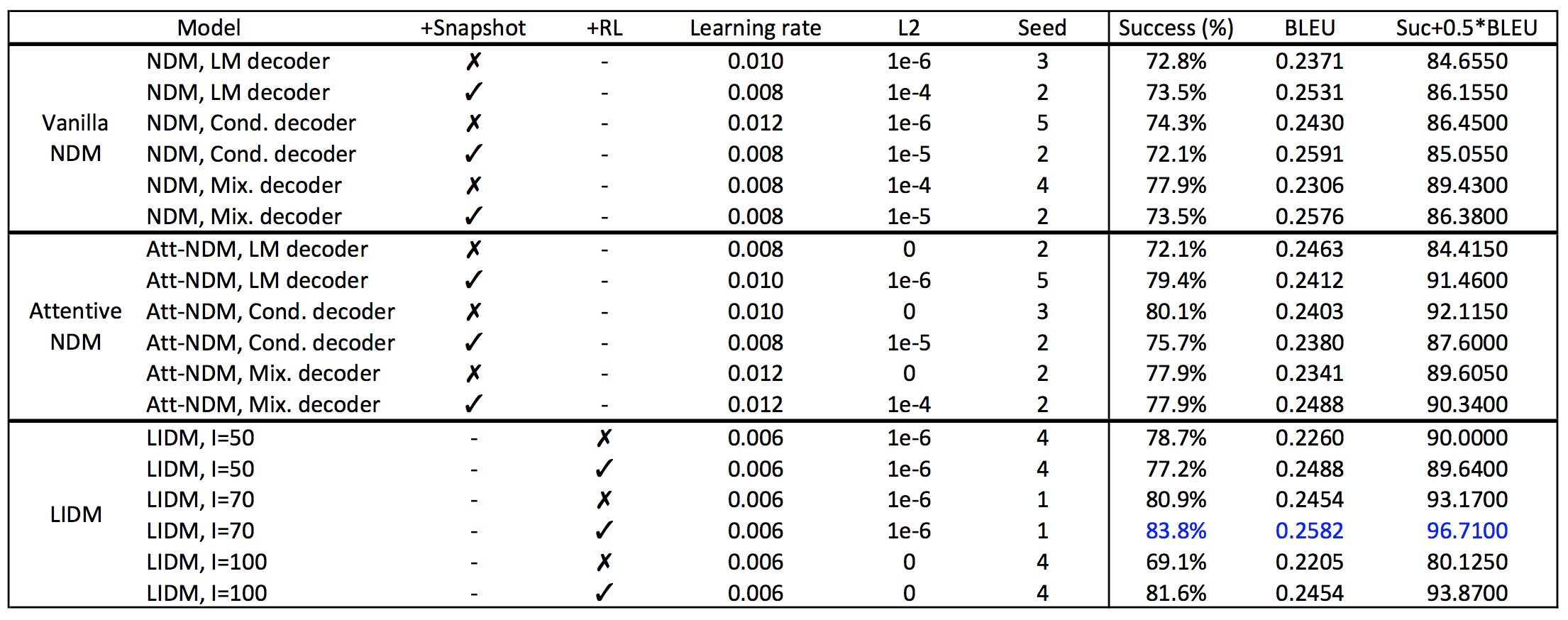
5 example models were saved at model/demo/ for reference. You can directly run testing or interaction on these models.
If you have found any bugs in the code, please contact: thw28 at cam dot ac dot uk
If you use any source codes or datasets included in this toolkit in your work, please cite the corresponding papers. The bibtex are listed below:
[Wen et al, 2017a]
@InProceedings{wenN2N17,
author = {Wen, Tsung-Hsien and Vandyke, David and Mrk\v{s}i\'{c}, Nikola and
Gasic, Milica and Rojas Barahona, Lina M. and Su, Pei-Hao and
Ultes, Stefan and Young, Steve},
title = {A Network-based End-to-End Trainable Task-oriented Dialogue System},
booktitle = {EACL},
month = {April},
year = {2017},
address = {Valencia, Spain},
publisher = {Association for Computational Linguistics},
pages = {438--449},
url = {http://www.aclweb.org/anthology/E17-1042}
}
[Wen et al, 2017b]
@inproceedings{wenLIDM17,
title = {Latent Intention Dialogue Models},
Author = {Wen, Tsung-Hsien and Miao, Yishu and Blunsom, Phil and Young, Steve},
booktitle = {ICML},
series = {ICML'17},
year = {2017},
location = {Sydney, Australia},
numpages = {10},
publisher = {JMLR.org},
}
[Wen et al, 2016]
@InProceedings{wenEMNLP2016,
author = {Wen, Tsung-Hsien and Gasic, Milica and Mrk\v{s}i\'{c}, Nikola and
Rojas Barahona, Lina M. and Su, Pei-Hao and Ultes, Stefan and
Vandyke, David and Young, Steve},
title = {Conditional Generation and Snapshot Learning in Neural Dialogue Systems},
booktitle = {EMNLP},
month = {November},
year = {2016},
address = {Austin, Texas},
publisher = {ACL},
pages = {2153--2162},
url = {https://aclweb.org/anthology/D16-1233}
}