A Machine learning project on NLP to detect different types of toxicity like threats, obsenity, insults, and identity-based hate. in the comments given in the dataset.
The dataset used in this project consists of three files present in the 'data' folder : train.csv, test.csv and test_labels.csv The data in the training set is in the form of comments which have been labelled by human raters for toxic behavior. These comments are classified into six types of toxicity: toxic, severe_toxic, obscene, threat, insult and identity_hate .
Following are the phases in which this project has been implemented:
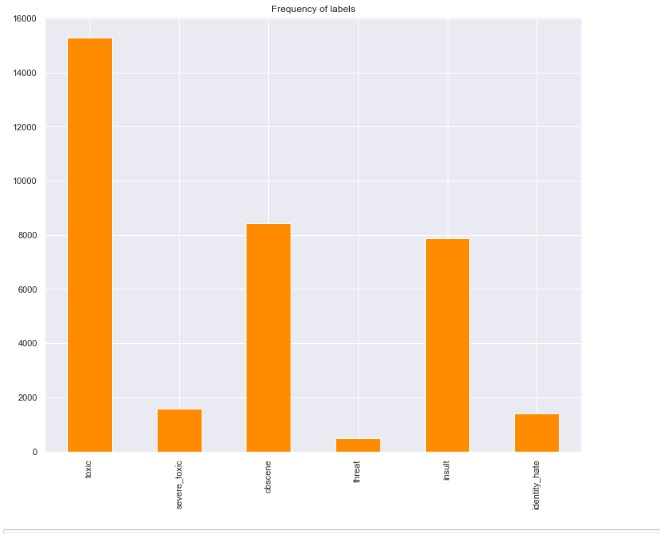
The train data has 159571 observations with 8 columns and the test data has 153164 observations with 2 columns. A plot showing the count of each of the six labels was plotted and it was observed that the label 'toxic' has the most observations in the training dataset while 'threat' label has the least observations.
A cross-correlation matrix for each label was plotted to see which labels are likely to appear together with a comment and it was observed that 'obscene' label had a higher chance to be 'insulting' at the same time. Further, to visualize the most common words contributing to different labels, separate word cloud was generated for each label.
In order to fit the comments properly into the model, tokenization was used to remove punctuations, special characters and non-ascii characters from the comments. Then another technique called as lemmatization was used and all the comments with length less than three were filtered out. Next TFIDF vectorizer was used to scale down the impact of tokens that occur very frequently in a given corpus which are empirically less informative than features that occur in a small fraction of the training corpus.
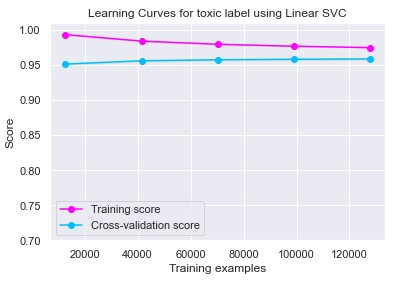
For modelling purpose, three models that are known to perform well in text classification were compared against each other, they are Linear SVM , Multinomial Naive Bayes and Logistic Regression. The evaluation metrics used to check the performance were: F1-score, Recall and Hamming Loss. Initally, the cross-validation F1-score and Recall were compared using the training dataset and it was observed that Linear SVM and Logistic Regression model performed much better than Multinomial Naive Bayes.
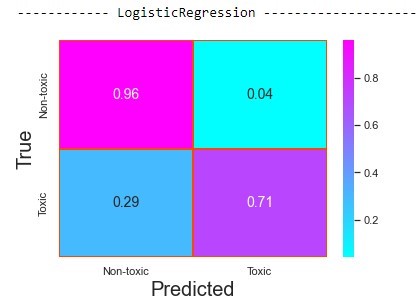
On the test dataset also, multinomial naive bayes model didn't performed well as compared to others and it was observed that Linear SVM model performed slightly better than Logistic Regression model. Further, confusion matrices were plotted for the most common label 'toxic' and it was observed that all the three models predicted non-toxic labels fairly well probably because most of the data was non-toxic.

Aggregate hamming loss was also calculated for each model and it was found that Logistic Regression had the least percentage of labels incorrectly classified.

Pipelines were constructed to compare Linear SVM and Logistic Regression models and 'class_weight' hyperparamter was manually chosen to aim for better results than the basic models itself.
The result showed that Linear SVC performed better than Logistic Regression model.
The optimal hyperparamters for the basic models were found out using Grid Search, considering only the label 'toxic' since it was the most common label, to tune the hyperparameters.

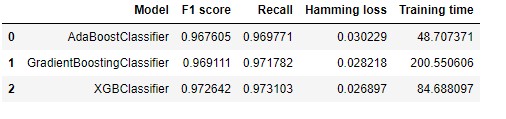
For ensembling different models, three popular tree-based boosting models : Adaptive Boosting, Gradient Boosting and XG Bossting were compared against each other on the evaluation metrics described earlier. The result showed that XGBoost Classifier performed the best out of all three classifiers and so a voting classifier was used to ensemble XGBoost model with our Logistic Regression and Linear SVM models.
Linear SVM performed the best in terms of the evaluation metrics and is the fastest of the three models we compared. But at the same time, we may get better results after tuning the hyperparameters for ensembling.