-
Notifications
You must be signed in to change notification settings - Fork 110
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
## 安装 <div> <a href="https://www.kaggle.com/code/ccsufengwen/sd3-comfyui/notebook"> SD3 Speedup Quick Start</a> <a href="https://www.kaggle.com/code/ccsufengwen/sd3-comfyui/notebook"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a> </div> ## Run WorkFlow - 28 step image 1024x1024 mode: max-optimize:max-autotune:low-precision | Accelerator | Baseline (non-optimized) | OneDiff (optimized) | Percentage improvement | | --------------------- | ------------------------ | ------------------- | ---------------------- | | NVIDIA A800-SXM4-80GB | ~4.03 sec | ~2.93 sec | ~27.29 % | ``` 动态 shape print("Test run with multiple resolutions...") sizes = [1024, 512, 768, 256] for h in sizes: for w in sizes: ``` 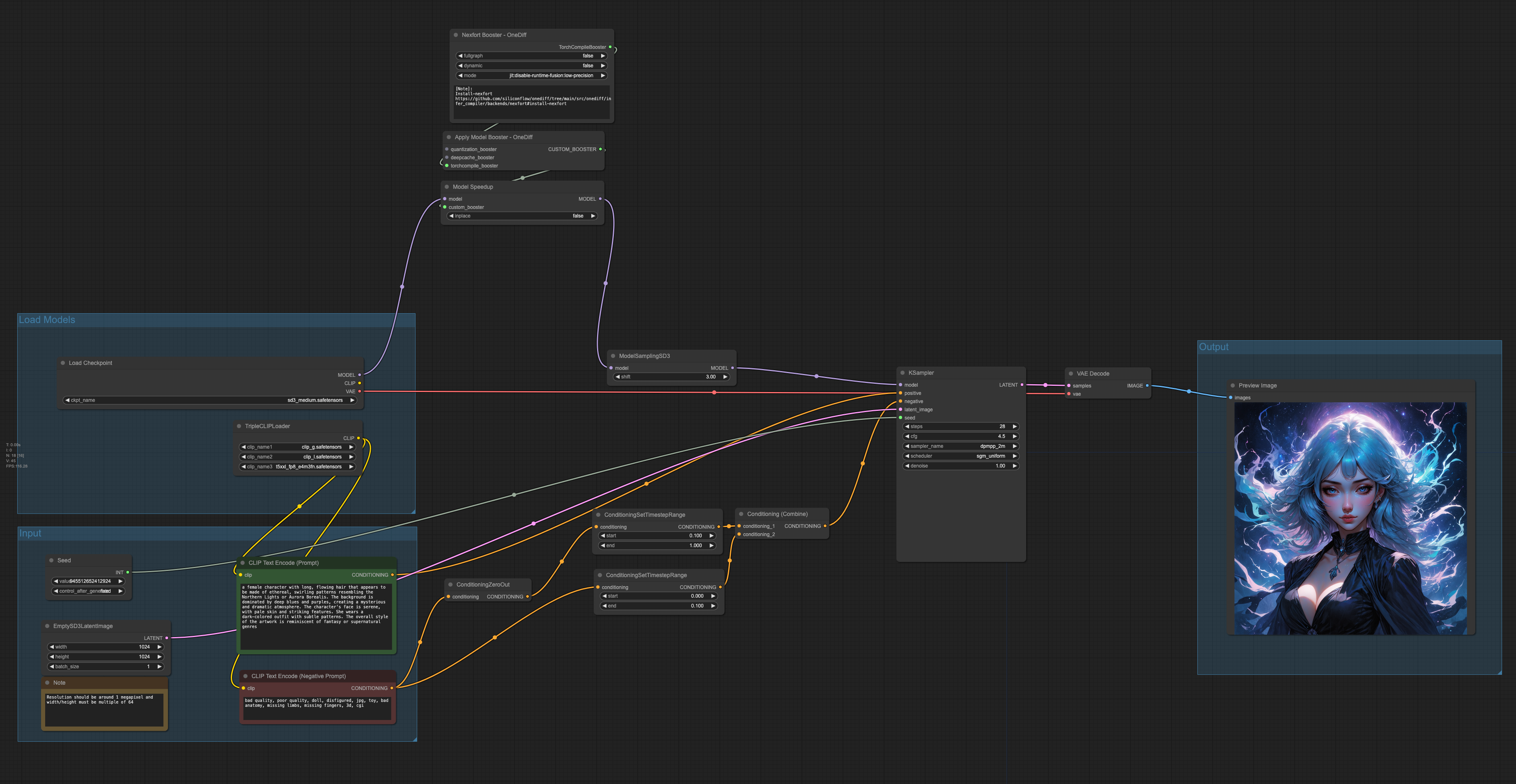 --------- Co-authored-by: Xiaoyu Xu <xiaoyulink@gmail.com>
{kind=link}
- Loading branch information
Showing
3 changed files
with
173 additions
and
1 deletion.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,97 @@ | ||
| ## Accelerate SD3 by using onediff | ||
| huggingface: https://huggingface.co/stabilityai/stable-diffusion-3-medium | ||
|
|
||
|
|
||
| ### Feature | ||
| - ✅ Multiple resolutions | ||
|
|
||
| ### Performance | ||
|
|
||
| - Timings for 28 steps at 1024x1024 | ||
| - OneDiff[Nexfort] Compile mode: max-optimize:max-autotune:low-precision | ||
|
|
||
| | Accelerator | Baseline (non-optimized) | OneDiff (optimized) | Percentage improvement | | ||
| | --------------------- | ------------------------ | ------------------- | ---------------------- | | ||
| | NVIDIA A800-SXM4-80GB | ~4.03 sec | ~2.93 sec | ~27.29 % | | ||
|
|
||
|
|
||
|
|
||
|
|
||
| The following table shows the comparison of the plot, seed=1, Baseline (non optimized) on the left, and OneDiff (optimized) on the right | ||
|
|
||
| | | | | ||
| | -------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------- | | ||
| |  |  | | ||
|
|
||
|
|
||
| ### Multiple resolutions | ||
| test with multiple resolutions and support shape switching in a single line of Python code | ||
| ``` | ||
| [print(f"Testing resolution: {h}x{w}") for h in [1024, 512, 768, 256] for w in [1024, 512, 768, 256]] | ||
| ``` | ||
|
|
||
| ## Usage Example | ||
|
|
||
| ### Install | ||
|
|
||
| ```shell | ||
| # python 3.10 | ||
| COMFYUI_DIR=$pwd/ComfyUI | ||
| git clone https://github.com/siliconflow/onediff.git | ||
| cd onediff && pip install -r onediff_comfy_nodes/sd3_demo/requirements.txt && pip install -e . | ||
| ln -s $pwd/onediff/onediff_comfy_nodes $COMFYUI_DIR/custom_nodes | ||
| git clone https://github.com/comfyanonymous/ComfyUI.git | ||
| ``` | ||
|
|
||
| <details close> | ||
| <summary> test_install.py </summary> | ||
|
|
||
| ```python | ||
| # Compile arbitrary models (torch.nn.Module) | ||
| import torch | ||
| from onediff.utils.import_utils import is_nexfort_available | ||
| assert is_nexfort_available() == True | ||
|
|
||
| import onediff.infer_compiler as infer_compiler | ||
|
|
||
| class MyModule(torch.nn.Module): | ||
| def __init__(self): | ||
| super().__init__() | ||
| self.lin = torch.nn.Linear(100, 10) | ||
|
|
||
| def forward(self, x): | ||
| return torch.nn.functional.relu(self.lin(x)) | ||
|
|
||
| mod = MyModule().to("cuda").half() | ||
| with torch.inference_mode(): | ||
| compiled_mod = infer_compiler.compile(mod, | ||
| backend="nexfort", | ||
| options={"mode": "max-autotune:cudagraphs", "dynamic": True, "fullgraph": True}, | ||
| ) | ||
| print(compiled_mod(torch.randn(10, 100, device="cuda").half()).shape) | ||
|
|
||
| print("Successfully installed~") | ||
| ``` | ||
| </details> | ||
|
|
||
| ### Run ComfyUI | ||
| ```shell | ||
| # run comfyui | ||
| # For CUDA Graph | ||
| export NEXFORT_FX_CUDAGRAPHS=1 | ||
| # For best performance | ||
| export TORCHINDUCTOR_MAX_AUTOTUNE=1 | ||
| # Enable CUDNN benchmark | ||
| export NEXFORT_FX_CONV_BENCHMARK=1 | ||
| # Faster float32 matmul | ||
| export NEXFORT_FX_MATMUL_ALLOW_TF32=1 | ||
| # For graph cache to speedup compilation | ||
| export TORCHINDUCTOR_FX_GRAPH_CACHE=1 | ||
| # For persistent cache dir | ||
| export TORCHINDUCTOR_CACHE_DIR=~/.torchinductor_cache | ||
| cd $COMFYUI_DIR && python main.py --gpu-only --disable-cuda-malloc | ||
| ``` | ||
|
|
||
| ### WorkFlow | ||
|  | ||
|
|
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,74 @@ | ||
| accelerate==0.31.0 | ||
| aiohttp==3.9.5 | ||
| aiosignal==1.3.1 | ||
| async-timeout==4.0.3 | ||
| attrs==23.2.0 | ||
| certifi==2024.6.2 | ||
| cffi==1.16.0 | ||
| charset-normalizer==3.3.2 | ||
| click==8.1.7 | ||
| cryptography==42.0.8 | ||
| Deprecated==1.2.14 | ||
| diffusers==0.29.0 | ||
| einops==0.8.0 | ||
| filelock==3.15.1 | ||
| frozenlist==1.4.1 | ||
| fsspec==2024.6.0 | ||
| gitdb==4.0.11 | ||
| GitPython==3.1.43 | ||
| huggingface-hub==0.23.3 | ||
| idna==3.7 | ||
| importlib_metadata==7.1.0 | ||
| Jinja2==3.1.4 | ||
| markdown-it-py==3.0.0 | ||
| MarkupSafe==2.1.5 | ||
| matrix-client==0.4.0 | ||
| mdurl==0.1.2 | ||
| mpmath==1.3.0 | ||
| multidict==6.0.5 | ||
| networkx==3.3 | ||
| nexfort==0.1.dev242 | ||
| numpy==1.26.4 | ||
| nvidia-cublas-cu12==12.1.3.1 | ||
| nvidia-cuda-cupti-cu12==12.1.105 | ||
| nvidia-cuda-nvrtc-cu12==12.1.105 | ||
| nvidia-cuda-runtime-cu12==12.1.105 | ||
| nvidia-cudnn-cu12==8.9.2.26 | ||
| nvidia-cufft-cu12==11.0.2.54 | ||
| nvidia-curand-cu12==10.3.2.106 | ||
| nvidia-cusolver-cu12==11.4.5.107 | ||
| nvidia-cusparse-cu12==12.1.0.106 | ||
| nvidia-nccl-cu12==2.20.5 | ||
| nvidia-nvjitlink-cu12==12.5.40 | ||
| nvidia-nvtx-cu12==12.1.105 | ||
| packaging==24.1 | ||
| pillow==10.3.0 | ||
| psutil==5.9.8 | ||
| pycparser==2.22 | ||
| Pygments==2.18.0 | ||
| PyJWT==2.8.0 | ||
| PyNaCl==1.5.0 | ||
| PyYAML==6.0.1 | ||
| regex==2024.5.15 | ||
| requests==2.32.3 | ||
| rich==13.7.1 | ||
| safetensors==0.4.3 | ||
| scipy==1.13.1 | ||
| shellingham==1.5.4 | ||
| smmap==5.0.1 | ||
| sympy==1.12.1 | ||
| tokenizers==0.19.1 | ||
| torch==2.3.1 | ||
| torchaudio==2.3.1 | ||
| torchsde==0.2.6 | ||
| torchvision==0.18.1 | ||
| tqdm==4.66.4 | ||
| trampoline==0.1.2 | ||
| transformers==4.41.2 | ||
| triton==2.3.1 | ||
| typer==0.12.3 | ||
| typing_extensions==4.12.2 | ||
| urllib3==1.26.18 | ||
| wrapt==1.16.0 | ||
| yarl==1.9.4 | ||
| zipp==3.19.2 |