Improve HTML code element clipping #11281
Comments
|
3.0.13依旧是复制网页元素,截图:
如果是单单是复制 不知道你用的是什么解析剪切板的富文本信息,剪切板都是HTML富文本形式,操作截图:
import win32clipboard
def GetAvailableFormats():
"""
Return a possibly empty list of formats available on the clipboard
返回剪切板可能有的一些格式
"""
formats = []
try:
win32clipboard.OpenClipboard(0)
cf = win32clipboard.EnumClipboardFormats(0)
while (cf != 0):
formats.append(cf)
cf = win32clipboard.EnumClipboardFormats(cf)
finally:
win32clipboard.CloseClipboard()
return formats
# CF_HTML=49433
CF_HTML = win32clipboard.RegisterClipboardFormat("HTML Format")
if CF_HTML in GetAvailableFormats():
win32clipboard.OpenClipboard(0)
src = win32clipboard.GetClipboardData(CF_HTML)
src = src.decode("UTF-8")
print(src)
else:
print("当前剪切板没有富文本内容")完整的剪切板内容输出: 表格在代码其中: table代码直接粘贴到Github的MD编辑器就显示成表格: 操作截图:
善用富文本,MD写作笔记中的富文本地位很高 |



|
我这里测试正文中提到的网页 DOM 结构已经没有问题: issue.webm其他网页的话麻烦单独提 issue 进行改进,谢谢。 |
|

|
收到,这种情况下个版本改进,谢谢。 |
|
是否有考虑:
Github的Issue编辑框的 其它: |
|
思源笔记的编辑器不是 Markdown 编辑器,所以不考虑源码编辑模式。 @Vanessa219 表格最后一行 Enter 跳出创建新块考虑一下。 |
自研编辑器?那更多的MD语法还考虑支持吗?😬 |
|
暂时不考虑了哦。
…---Original---
From: ***@***.***>
Date: Sat, May 11, 2024 02:25 AM
To: ***@***.***>;
Cc: ***@***.***>;"State ***@***.***>;
Subject: Re: [siyuan-note/siyuan] Improve HTML code element clipping (Issue#11281)
思源笔记的编辑器不是 Markdown 编辑器,所以不考虑源码编辑模式。
自研编辑器?那更多的MD语法还考虑支持吗?😬
—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you modified the open/close state.Message ID: ***@***.***>
|
|
复制Github的引用链接出错,无法转为 |

|
这个 a 标签的锚文本是个 svg,编辑器进行处理,所以导致锚文本为空,从而无法转换渲染为正常的超链接:
下个版本会改进为直接丢弃锚文本为空的超链接元素。 |


|
这时候就体现富文本HTML的优势了,放到Github编辑框能自动显示为合适的格式,siyuan应该添加富文本/HTML支持,这样无论下次剪切/复制什么内容,siyuan就直接读取HTML转为合适的格式
剪切板的问题陆陆续续遇到了好几次,这次解决了,但下次又双叒叕遇到了咋办😂 |

|
支持不了 HTML 的,遇到问题继续解决。
…---Original---
From: ***@***.***>
Date: Mon, May 13, 2024 03:38 AM
To: ***@***.***>;
Cc: ***@***.***>;"State ***@***.***>;
Subject: Re: [siyuan-note/siyuan] Improve HTML code element clipping (Issue#11281)
这时候就体现富文本HTML的优势了,放到Github编辑框能自动显示为合适的格式,siyuan应该添加富文本/HTML支持,这样无论下次剪切/复制什么内容,siyuan就直接读取HTML转为合适的格式
SiYuan_x3BnSQ8sH4.gif (view on web)
剪切板的问题陆陆续续遇到了好几次,这次解决了,但下次又双叒叕遇到了咋办😂
—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you modified the open/close state.Message ID: ***@***.***>
|
剪切板的富文本内容是千奇百怪的,注定了要维护很久……不太建议使用这种维护方式,哪天siyuan弃坑了,很多类似的方面就不好维护了 随手复制就遇到了新问题,没有换行: 粘贴到notepad或github的编辑框,粘贴的内容能保留换行符: 还有一个问题:
我从网页复制的富文本,能在siyuan的代码片段里粘贴为普通文本…… |



|
没有其他更好的方案了,从各式各样的 HTML 复制粘贴后只能进行适配,这个处理步骤无法避免的,这就是富文本编辑器开发中很麻烦的一个地方。 视频中没有换行的地方多半是因为网页 DOM 中没有换行元素(比如 p/div 或者 br),可以给一下网址以便排查。
思源中复制是以 text(md)/html 复制的,剪切板里面我记得有这两种格式,具体用哪种要看粘贴的地方的选择。思源中粘贴使用的话优先是带格式的,其次才是文本,所以在代码块里面用文本就会带 |
https://www.dataleadsfuture.com/combining-traditional-thread-based-code-and-asyncio-in-python/ 开启了沉浸式翻译
不能往剪切板放富文本吗?剪切板有几十种格式,MD格式的文本转为HTML格式的代码,以富文本格式往剪切板放进去,这样复制粘贴就不会有问题了 |

应该是放了的,但是主要看粘贴的时候软件如何处理了。 |
那估计就是没有换行了,这种无法解析出来的。 |
观察了下从思源获取的内嵌代码 可能是因为思源的编辑器读取到 刚测了下,如果
什么意思?沉浸式翻译是把译文的HTML元素内嵌到网页啊?看了下源码,译文前头是有 |
|
我测试复制行级元素和复制块级元素后直接粘贴,两种情况都会带有 issue.webm用 粘贴为纯文本 就可以不带 issue.webm
处理
|

因为复制的时候,思源的写入剪切板的文本是 Python参考代码:
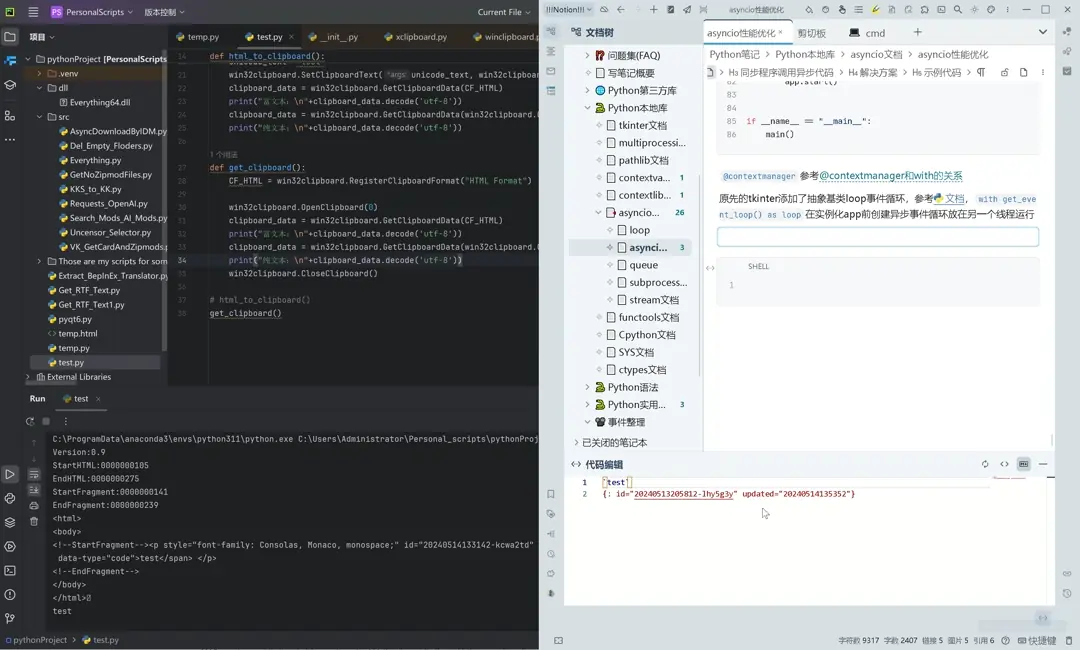
但是,Pycharm用的'lxml'解析器解析剪切板的html代码,get_text()获取的文本有换行,要不你换个解析器?
|

|
换不了解析器的....
…---Original---
From: ***@***.***>
Date: Tue, May 14, 2024 14:18 PM
To: ***@***.***>;
Cc: ***@***.***>;"State ***@***.***>;
Subject: Re: [siyuan-note/siyuan] Improve HTML code element clipping (Issue#11281)
我测试复制行级元素和复制块级元素后直接粘贴,两种情况都会带有 ` 的:
因为复制的时候,思源的写入剪切板的文本是`XXX`,或测试 `XXX` 测试,在使用CF_TEXT或CF_UNICODETEXT剪切板格式的时候,TEXT应该为不带`的XXX
Python参考代码:
from re import search text = '''Version:0.9 StartHTML:0000000105 EndHTML:0000000272 StartFragment:0000000141 EndFragment:0000000236 <html> <body> <!--StartFragment--><p style="font-family: Consolas, Monaco, monospace;" id="20240514135730-37ivg0u" updated="20240514135730"><span data-type="code">loop</span></p> <!--EndFragment--> </body> </html>''' import win32clipboard,bs4 def html_to_clipboard(): CF_HTML = win32clipboard.RegisterClipboardFormat("HTML Format") win32clipboard.OpenClipboard(0) win32clipboard.EmptyClipboard() win32clipboard.SetClipboardData(CF_HTML, text.encode('utf-8')) unicode_text ='loop' win32clipboard.SetClipboardText(unicode_text, win32clipboard.CF_UNICODETEXT) clipboard_data = win32clipboard.GetClipboardData(CF_HTML) print("富文本:\n"+clipboard_data.decode('utf-8')) clipboard_data = win32clipboard.GetClipboardData(win32clipboard.CF_UNICODETEXT) print("纯文本:\n"+clipboard_data) def get_clipboard(): CF_HTML = win32clipboard.RegisterClipboardFormat("HTML Format") win32clipboard.OpenClipboard(0) clipboard_data = win32clipboard.GetClipboardData(CF_HTML) clipboard_data=bs4.BeautifulSoup(search('<!--StartFragment-->([\\s\\S]+)<!--EndFragment-->|<html>([\\s\\S]+)</html>',clipboard_data.decode('utf-8')).group(0),'lxml').prettify() print("富文本:\n"+clipboard_data) clipboard_data = win32clipboard.GetClipboardData(win32clipboard.CF_UNICODETEXT) print("纯文本:\n"+clipboard_data) win32clipboard.CloseClipboard() html_to_clipboard() # get_clipboard()
处理 <font> 时其中的 <br> 会被替换为空格:
但是,Pycharm用的'lxml'解析器解析剪切板的html代码,get_text()获取的文本有换行,要不你换个解析器?
chrome_0hjrvM1P51.gif (view on web)
—
Reply to this email directly, view it on GitHub, or unsubscribe.
You are receiving this because you modified the open/close state.Message ID: ***@***.***>
|



[功能改善] 复制网页元素转为md格式时,不应该复制网页元素
Is there an existing issue for this?
Can the issue be reproduced with the default theme (daylight/midnight)?
Could the issue be due to extensions?
Describe the problem
粘贴到issue的md编辑器,它只会粘贴成这样:
ctypes 是 Python 的外部函数库。它提供了与 C 兼容的数据类型,并允许调用 DLL 或共享库中的函数。可使用该模块以纯 Python 形式对这些库进行封装。
Expected result
它把span元素也一起粘贴了,为什么不能取元素文本呢?就像上面github把span的文本放在xxx
Screenshot or screen recording presentation
No response
Version environment
Log file
NO
More information
No response
The text was updated successfully, but these errors were encountered: