키워드들을 선택하여 책을 추천하는 추천시스템
팀원:
-
YBIGTA 15기: 김용우, 김수정
-
YBIGTA 16기: 노시영, 박준민, 박솔희
- 책에 대한 설명에서 키워드들을 추출한 후, 그 키워드들을 책의 제목에 임베딩하여 책의 특징을 반영하게 한다.
- 임베딩된 데이터를 DB화하여 유저가 DB에 있는 책 제목을 검색하면 유저에게 해당되는 책에서 5가지 키워드들을 보여준다.
- 유저는 이 5가지 키워드들 중 3가지 키워드까지 선택한다.
- 선택된 키워드들과 가장 코사인유사도가 높은 책을 추천해준다.
이런 구조로 흘러가는 꽤나 간단한 추천시스템을 만들고자 한다.
CF(Collaborative Filtering), MF(Matrix Factorization), DL(Deep Learning) 알고리즘을 활용하는 복잡한 모델이 아닌, 가볍게 키워드들을 추출하여 그 키워드들 간의 유사도를 바탕으로 추천시스템을 구축하여 서비스화의 형식으로 만들고자 했다.
- 웹 스크레이핑을 통한 책 서평 수집
YES24에서 약 4만 건의 책 설명을 웹 스크레이핑(Beautiful Soup을 통해)하여 csv파일 형태로 저장
- RAKE(Rapid Automatic Keyword Extraction)알고리즘을 활용하여, 문서에서 키워드들을 추출
RAKE알고리즘: Stopword(and, a, the 등의 단어)들 주변에 있는 단어들을 Context Word들로 보고, 이들을 추출한다. 이 단어들을 행렬형태로 정리한 뒤, 각 단어마다 Keyword Score를 계산한다. Keyword Score의 계산은 다음과 같다
함께 등장한 단어들과의 빈도수 합산/해당단어의 출현 빈도
다음과 같은 예시를 보면,
Keyword extraction is not that difficult after all. There are many libraries that can help you with keyword extraction. Rapid automatic keyword extraction is one of those.
여기서 Stopwords들은 다음과 같다.
stopwords = [is, not, that, there, are, can, you, with, of, those, after, all, one]
delimiters = [., ,]
따라서, Content Words은 다음과 같다.
content_words = [keyword, extraction, difficult, many, libraries, help, rapid, automatic]
그러면 문장에서 중요한 단어들은
Keyword extraction is not that difficult after all. There are many libraries that can help you with keyword extraction. Rapid automatic keyword extraction is one of those.
이 단어들을 행렬형태로 정리하면

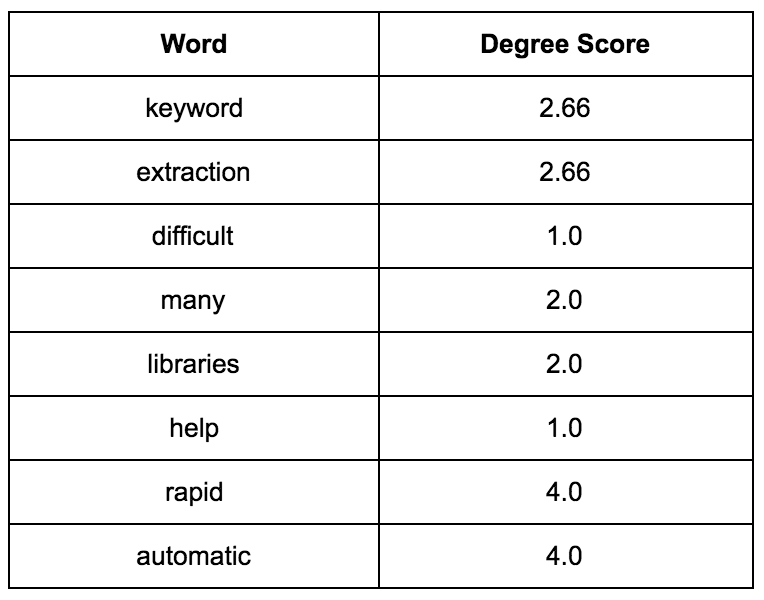
ex)"extraction"의 Keyword Score = (3+3+1+1)/3 = 8/3 = 2.66
이들 단어 중에 상위 5개를 선정하도록 하였다.
3.추출된 키워드의 TF-IDF 벡터화 추출된 단어를 현문서와 다른 문서간의 상대적 빈도수를 비교하여 임베딩하는 count-based 임베딩 기법인 TF-IDF기법을 통해 벡터공간에 나타낸다. 만약 한 단어가 특정 문서에 자주 등장하고 상대적으로 다른 문서에서 적게 등장한다면 그 TF-IDF수치는 높아진다.

- 코사인유사도를 통한 문서유사도 비교 TF-IDF을 통해 키워드들을 벡터공간에 임베딩했으니, 문서간의 코사인유사도를 비교하여 비슷한 책들을 추천할 수 있게 모델을 구성했다.
