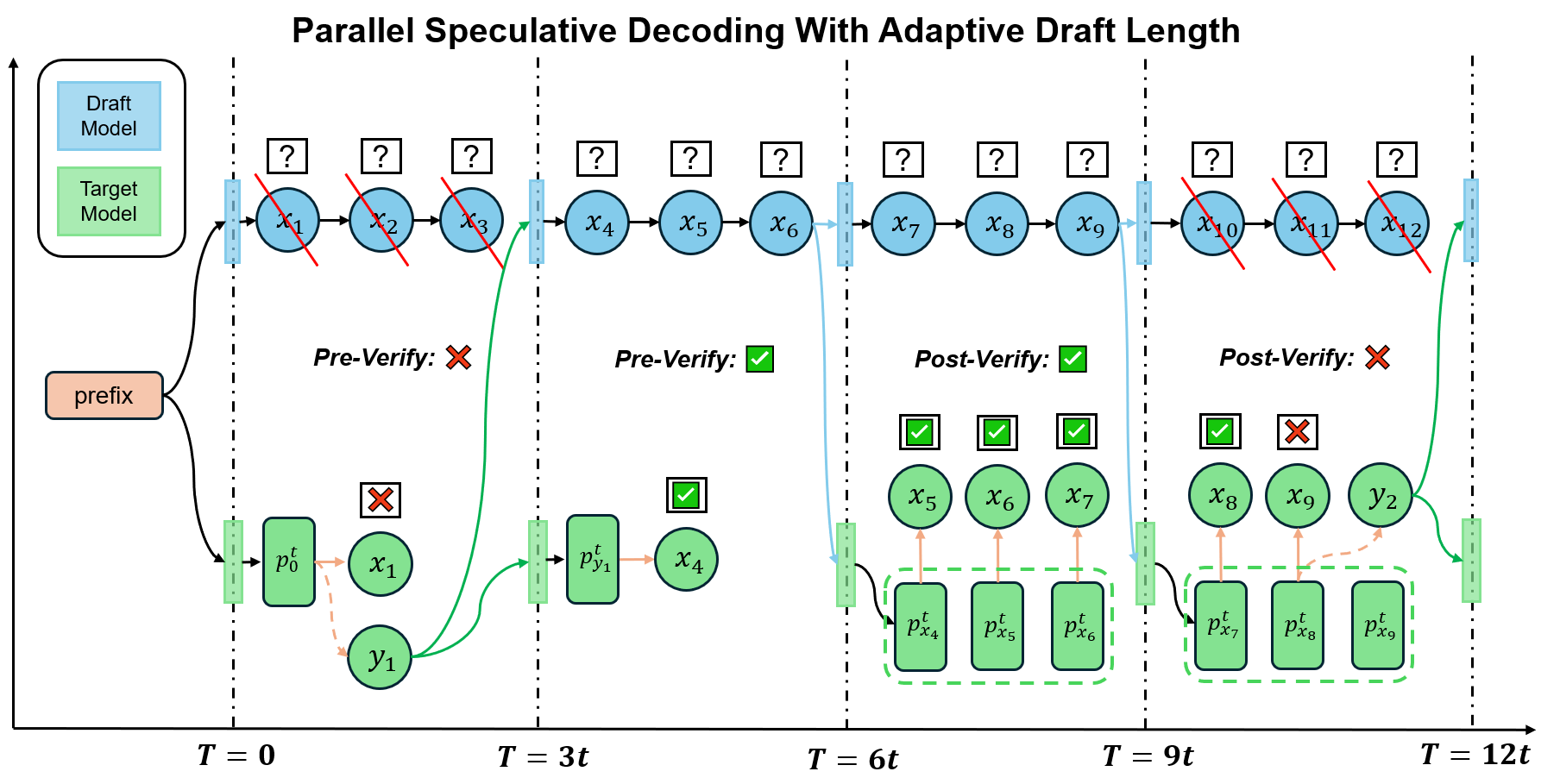
TL; DR: we introduce PEARL (Parallel spEculative decoding with Adaptive dRaft Length) to further reduce the inference latency of Large Language Models (LLMs). PEARL is a parallel inference framework based on speculative decoding which utilizes pre-verify and post-verify to achieve adaptive draft length. In summary, our PEARL is:
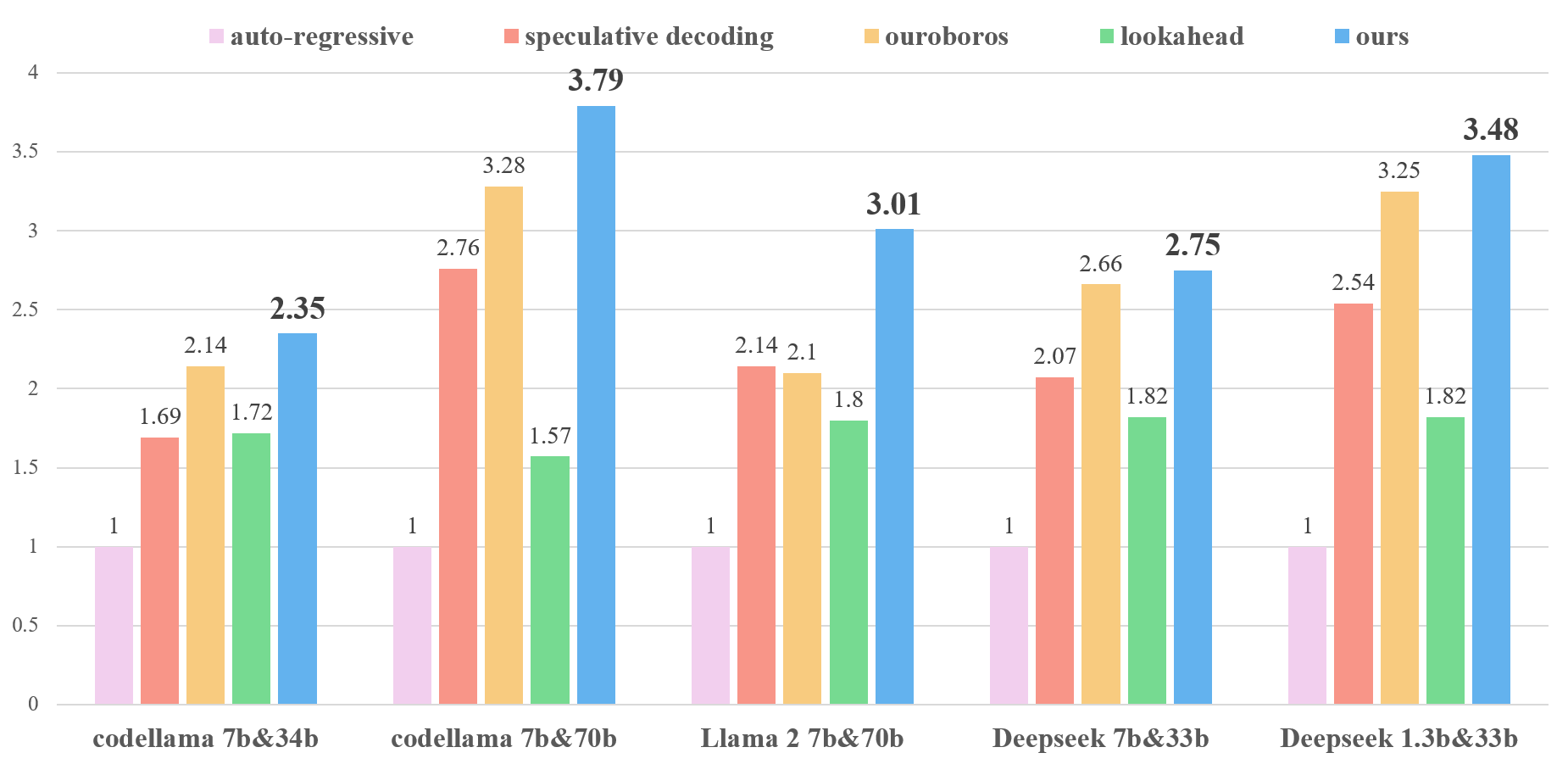
- 🔥 up to 3.87
$\times$ , 3.81$\times$ , 3.59$\times$ and 3.95$\times$ on HumanEval, GSM8K, MT-bench and MGSM, respectively.- provably lossless
- training-free, and does not need additional memory
- 🔥 can be applied to any algorithms based on draft-then-verify framework, such as EAGLE and Medusa
- 🔥 Eliminating the burden of searching the optimal draft length, together with a larger expectation of accepted tokens.

Figure 2. Generation speed of Llama 2 chat 70B using PEARL and auto-regressive decoding, with inference conducted on A100 80G GPUs at bf16 precision.
Our PEARL framework consists of a draft model, a target model and two strategies to decode tokens. The two strategies are switched according to the verification results in the last decoding step.
Follow the instructions below to prepare for reproducing the results in the paper.
- experimental environment:
sh install.shwill install the necessary packages in the project. - code changes: changes the code
src/util.pyline 31-38 and line 49, to fill in your model paths and data paths.
All the running scripts, including scripts for auto-regress decoding, vanilla speculative decoding, parallel speculative decoding, comparison, ablation studies and case studies. These scripts can be directly executed for reproduction.
sh scripts/run_para_sd.shYou can try this code with a simple command:
CUDA_VISIBLE_DEVICES=0,1,2,3 accelerate launch --num_processes 2 benchmark/eval_humaneval.py --eval_mode para_sd --gamma 5 -n 1 -e H_PSD_codellama_7_70b --draft_model codellama-7b --target_model codellama-70b --max_tokens 1024 --temp 0We have provided a suggested web interface, which you can use by running the following command.
CUDA_VISIBLE_DEVICES=0,1,2,3 accelerate launch --num_processes 2 applications --eval_mode para_sd --gamma 5 -n 1 -e applications --draft_model codellama-7b --target_model codellama-70b --max_tokens 1024 --temp 0If you find our work useful your research, please cite our paper:
@misc{liu2024parallelspeculativedecodingadaptive,
title={Parallel Speculative Decoding with Adaptive Draft Length},
author={Tianyu Liu and Yun Li and Qitan Lv and Kai Liu and Jianchen Zhu and Winston Hu},
year={2024},
eprint={2408.11850},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2408.11850},
}