Home
](LICENSE)
![]()
![]()

The solution
This is a public site. No private information should be stored here.
If you've ever needed to pull down databases from a live environment to stage or even dev you'll need to think about masking any personal and business-sensitive information. Enterprises run the risk of breaching sensitive information when sharing data to the public or copying production data into non-production environments for the purposes of application development, testing, or data analysis. This tool was designed to help reduce this risk by irreversibly replacing the original sensitive data with fictitious data so that production data can be shared safely with non-production users.
Data masking (also known as data sanitization, protection, data replacement and data anonymization) is the process of replacing sensitive information copied from production databases to test non-production databases with realistic, but scrubbed, data based on masking rules. Data masking" means altering data from its original state to protect it. This process is ideal for virtually any situation when confidential or regulated data needs to be shared with non-production users.
Data masking enables organizations to generate realistic and fully functional data with similar characteristics as the original data to replace sensitive or confidential information while sharing the data with the public or interested partner
The Goal of data masking is to maintain the same structure of data so that it will work in applications. This often requires shuffling and replacement algorithms that leaves data such as number and data intact.
Personally-identifiable information (PII) is common to most data masking requirements. PII is any data that can be used to identify a living person, and includes such elements as name, date of birth, National Identification Number, address details, phone numbers or email addresses, disabilities, gender identity or sexual orientation, court orders, electronic wage slips, union affiliations, biometric and 'distinguishing feature' information, references to the serial number of devices such as laptops that are associated with, or assigned to, a person. Names, addresses, phone numbers, and credit card details are examples of data that require protection of the information content from inappropriate visibility. Live production database environments contain valuable and confidential data—access to this information is tightly controlled
The Data Masking tool comprises of 3 different stages;
- Reading or retrieving the Data to be mask from the production database into an object.
- Masking or manipulating the retrieved data into its classified equivalent (masking rules)
- Writing the masked data into the target environment e.g. (TEST, DEV, UAT or SQL inserts)
The data masker solution architecture is designed using the Repository Architecture pattern as part of the Domain-Driven Design (DDD) architecture patterns framework. Repositories are classes or components that encapsulate the logic required to access data sources. They centralize common data access functionality, providing better maintainability and decoupling the infrastructure or technology used to access databases from the domain model layer.
A repository performs the tasks of an intermediary between the domain model layers and data mapping, acting in a similar way to a set of domain objects in memory. Client objects declaratively build queries and send them to the repositories for answers. Conceptually, a repository encapsulates a set of objects stored in the database and operations that can be performed on them, providing a way that is closer to the persistence layer. Repositories, also, support the purpose of separating, clearly and in one direction, the dependency between the work domain and the data allocation or mapping.
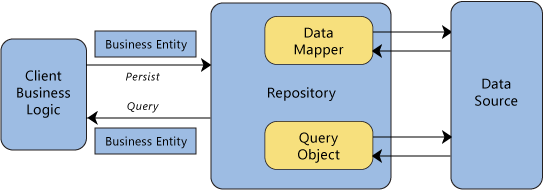
The data masking tool uses bogus algorithms for data generation. These algorithm are link to a data type respectively.
| Subject | Description |
|---|---|
| GitHub Workflow | How we use git and GitHub |
| Architecture | Data Masker architecture design information |
| Solution Delivery | DevOps and Solution Delivery information |
| Integrations | Data Masker Integrations design information |
| API | Data Masker Libraries and External API information |
| Validation Check | Security Validation Check |
| Configuration | PIMS Application information |
| DevOps CI/CD | DevOps documentation |
| Code Quality | Code Quality information |
| Data Classification | Transition Plan and Roadmap |
| Versions | Version information |
This section demonstrates the set of processes that bring the development and operations . DevOps is a set of practices that automates the processes between software development and IT teams, in order that they can build, test, and release software faster and more reliably.
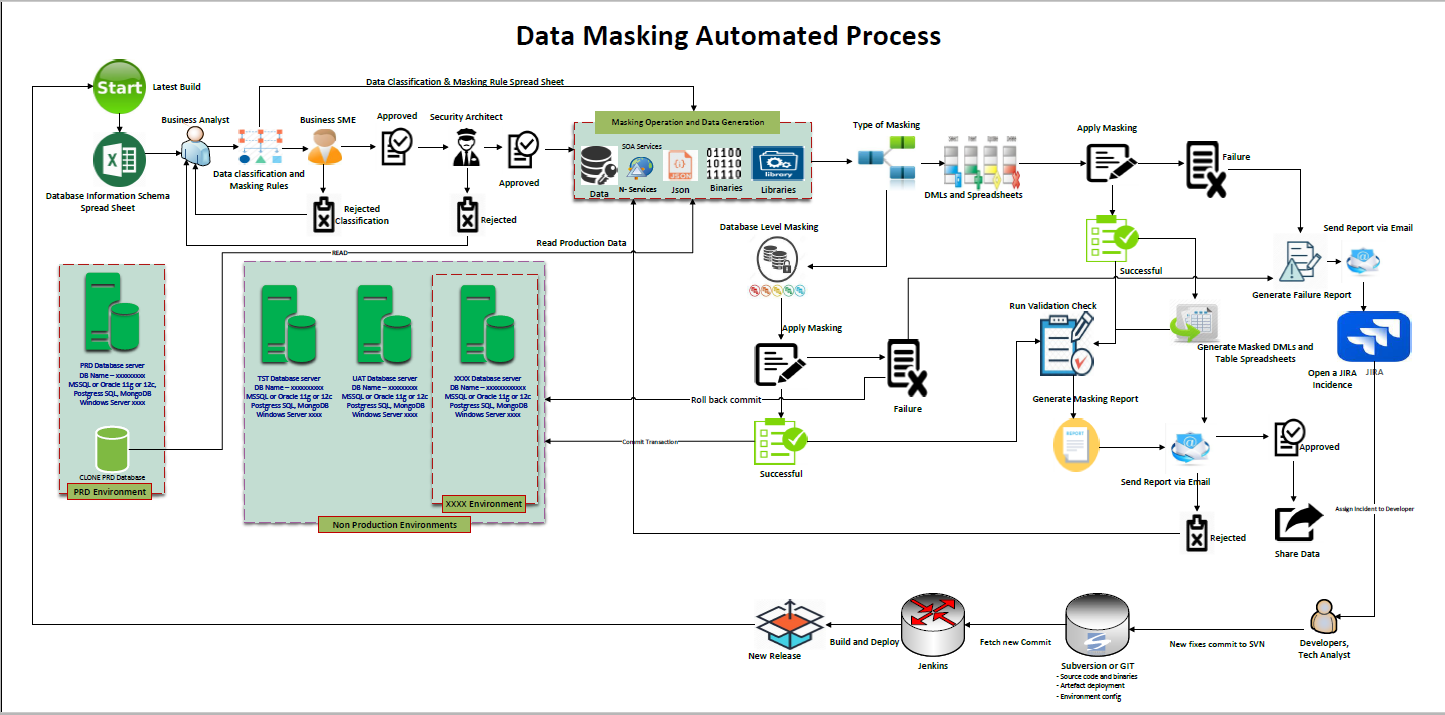
Shuffle has been tested to take longer time depending on the number of records. To improve performance, limit the numer of shuffle used or preferably use other masking type to achieve the same result. Ensure the data classification is done correctly: wrong classifcation will let to error handling which may reduce system performance Have a clean data. The data masking tool try to clean up the data before outputing the results. For example, Date field with Varchar type contains wrong data type like string or empty string. In this case, the data masking tool will clean up all irregular data in the column to a matched datetime data. E,.g. Empty string will be converted to a default dateTime type. Big data are cached in the CPU stack memory, therefore; masking a big data object (DataTables with more than 1 Million records) will require a good CPU memory for a good performance. Oracle DataSource uses ArrayBinding to write data into the Database. This improve performance by 50%.