Update adaptive CFL #1036
Update adaptive CFL #1036
Conversation
SU2_CFD/src/solvers/CSolver.cpp
Outdated
| if (maxLinResid > 0.5) { | ||
| if (maxLinResid > config->GetLinear_Solver_Error()) { | ||
| reduceCFL = true; | ||
| } |
There was a problem hiding this comment.
This might have to be accompanied by some changes to the best practices that @economon had established in #790. In most RANS cases that I have run, the linear solver error is almost never below the 1E-10 within the suggested 10 linear solver iterations.
Maybe the idea behind this check was to put an upper limit on what the linear solver error can be?
There was a problem hiding this comment.
Maybe it should be some factor larger than the linear solver tolerance then, because 0.5 just seems ridiculously high.
But I guess this raises the question of if this check is even necessary. I see the logic behind why we might want to reduce CFL if the linear solver isn't fully converging, but I feel like generally a partially converged linear solver doesn't lead to failure. Perhaps we just replace this altogether with some check that the nonlinear residual isn't increasing.
There was a problem hiding this comment.
but I feel like generally a partially converged linear solver doesn't lead to failure
I've experienced otherwise, BCGSTAB is prone to blowing up and FGMRES may not make any progress at all if the system is too ill-conditioned.
This is not my business, but I think changes to this kind of highly empirical strategy should be accompanied by empirical evidence.
There was a problem hiding this comment.
Also in many of the examples we have the linear solver tolerance is set very low to force a fixed number of linear iterations, and so if you base the decision of reducing CFL on attaining the unobtainable...
There was a problem hiding this comment.
Something else I notice when using CFL adaptation is that the dependence on linear convergence can cause a saw-tooth behavior, the CFL increases at max rate and then cuts down to the minimum value. I think ideally the algorithm would find the value that the linear solver can handle and hold it.
There was a problem hiding this comment.
Yeah I can see why Tom included that as a safeguard, but I don't recall seeing a dependence on linear convergence in any of the other papers I referenced when I opened this PR (e.g. https://arc.aiaa.org/doi/10.2514/6.2011-3696). Have you tested without it to see if the saw-tooth goes away? Maybe the other checks on UR and nonlinear residual are enough.
I think ideally the algorithm would find the value that the linear solver can handle and hold it.
That's a good idea. I like that more than 0.5 or a user-specified value, which are both pretty arbitrary.
|
Might want to update your ninja and meson submodules. Seems like those are changed, but they shouldn't be. |
|
First of all, thanks @bmunguia for picking this up.. I ran out of time when we were wrapping up v7, so the approach to check for stalling residuals within the CFL adaption routine was half-baked at best. It can definitely be improved (I'm not happy that I left some magic numbers hard-coded in there!). The implementation that is there to check for stall was very loosely based on the type of check we use for computing the Cauchy criteria (accumulated residual changes over time), but we should consider different approaches altogether. Btw, the original CFL adaption routine used something close to Switched Evolution Relaxation, while the new strategy is Exponential Progression with Under-relaxation (see "A Robust Adaptive Solution Strategy for High-Order Implicit CFD Solvers," AIAA 2011-3696 for a short description of both). As you also guessed, I had wanted to experiment with separate CFL numbers for flow and turbulence but also did not get to it. In the end, as @pcarruscag says, this is a very empirical task. It will be difficult to nail down a perfect configuration for all problems, but we might be able to come up with some best practices for choosing tunable parameters if folks have the time to run a lot of numerical experiments for a range of cases to see what works best. |
|
We were discussing the failing discrete adjoint test case in this PR earlier today in the dev call (which seems a little odd). It may be worth disabling the CFL adaption features altogether in Config::SetPostprocesing() when running the discrete adjoint, since it does not make much sense given that we record just a single primal iteration. We should also then check that the CFL number used in that iteration makes sense (initial value vs final value in the primal.. prob makes sense to use initial to be conservative). |
|
I've messed around with this a bit in some of my other branches. Since I've been using python scripts, I've used the minimum CFL in the volume at the end of the flow solution (obtained from the history file) as the CFL in my adjoint runs. I figured that would be the largest CFL that could be applied everywhere and give a contractive iteration. Doing so significantly reduced the cost of the adjoint (obviously proportional to CFL_Min/CFL_Init). We could probably do even better and output the local CFL in the restart then load that into adjoint runs, maybe with a reduction factor if we want to be conservative. |
|
Tom and I wrote something for Scitech, and now that I was making the slides I thought "what happened to that pull request..." -> the stale bot did. |
|
Classic stale bot. There are only 2 fixes since the UR fix was merged into develop in #1057, the Inner vs TimeIter fix and turning off CFL adaptation for the discrete adjoint (which I just added). If we're holding off on any algorithmic changes, I guess the only thing to discuss is which CFL should be used for the discrete adjoint. As is, it'll use whatever's specified in CFL_NUMBER in the config file, but I'm personally in favor of storing the local CFL to reduce the bottleneck of the adjoint. This could also be part of a separate PR if you need the bug fixes yesterday. |
|
I'm not in a hurry, but I would not want to upset the stalebot. Practical consideration regarding storing the CFL, do we have to? In the discrete adjoint we always to a dry run before the real recording, maybe that could be use to recompute the CFL at 0 overhead? |
Isn't that what we were doing before? While I also generally wouldn't want to rely on file I/O, my issues with how we had it were
Storing the CFL would at least recreate the state at primal convergence, which should be stable if the CFL adaptation is reliable. But maybe this idea is better suited for the python wrapper where we could just keep everything in memory. |
 pcarruscag
left a comment
pcarruscag
left a comment
There was a problem hiding this comment.
I tried to address the linear solver issues I had raised, seems to work.
If you had other plans we can always revert that last commit.
| /* Number of iterations considered to check for stagnation. */ | ||
| const auto Res_Count = min(100ul, config->GetnInner_Iter()-1); |
There was a problem hiding this comment.
I added this because for unsteady and multiphysics the inner iterations may not get to 100
SU2_CFD/src/solvers/CSolver.cpp
Outdated
| /* Check if we should decrease or if we can increase, the 20% is to avoid flip-flopping. */ | ||
| const bool reduceCFL = linRes > 1.2*linTol; | ||
| const bool canIncrease = (linIter <= config->GetLinear_Solver_Iter()) && (linRes < linTol); |
There was a problem hiding this comment.
This is my proposal to avoid the saw-tooth problem, here reduce means "apply the reduction factor" rather than returning to the minimum.
If "canIncrease" is not true the increase factor is not applied.
There was a problem hiding this comment.
This logic makes sense.
would linIter <= config->GetLinear_Solver_Iter() always be true, since the number of linear iterations would be <= the limit specified in the config?
There was a problem hiding this comment.
That thought popped into my head when I went to sleep last night... It should be < and the linRes < linTol is probably redundant as well.
There was a problem hiding this comment.
Or you could just have linRes < linTol, to take care of the case where it hits the tolerance on the last iteration of the linear solver. I'll test this new adaptive CFL and give this the 👍
There was a problem hiding this comment.
Yep I made that change locally. I'm having a look at the criteria to detect stagnation, on the case I am using for testing it is getting triggered but the convergence is fine....
These last changes caused a massive change in residuals for the UQ cases, I have to look into that as well.
SU2_CFD/src/solvers/CSolver.cpp
Outdated
| const auto linIter = max(solverFlow->GetIterLinSolver(), linIterTurb); | ||
|
|
||
| /* Tolerance limited to a "reasonable" value. */ | ||
| const su2double linTol = max(0.001, config->GetLinear_Solver_Error()); |
There was a problem hiding this comment.
To work around the cases that have unreasonably low tolerances I added this 0.001.
There was a problem hiding this comment.
Might be a good idea to mention this limit in the config template
| current and previous iterations. */ | ||
| New_Func = 0.0; | ||
| for (unsigned short iVar = 0; iVar < solverFlow->GetnVar(); iVar++) { | ||
| New_Func += log10(solverFlow->GetRes_RMS(iVar)); |
There was a problem hiding this comment.
I think it makes sense to use the log of the residual as the orders of magnitude can differ significantly.
| reduceCFL |= (signChanges > Res_Count/4) && (totalChange > -0.5); | ||
|
|
||
| if (fabs(NonLinRes_Value) < 0.1*New_Func) { | ||
| NonLinRes_Counter = 0; | ||
| for (unsigned short iCounter = 0; iCounter < Res_Count; iCounter++) | ||
| NonLinRes_Series[iCounter] = New_Func; | ||
| if (totalChange > 2.0) { // orders of magnitude | ||
| resetCFL = true; |
There was a problem hiding this comment.
And this is some simple logic to detect oscillations and possible divergence.
There was a problem hiding this comment.
Just to make sure I am following this correctly, this resets if the Non linear residual increases by 2 orders of magnitude? And it reduces the CFL if the non-linear residual oscillates 25% of the time AND there is less than a 0.5 order of magnitude reduction.
This seems to work as designed. Also I appreciate the flex with the XOR operator. Don't see that very often.
There was a problem hiding this comment.
Correct, if the residuals are going down it does not care if the history does not look pretty.
Bigger flex is to compute the total change by adding consecutive deltas, which still works when it wraps around to overwrite the oldest values.
 jayantmukho
left a comment
jayantmukho
left a comment
There was a problem hiding this comment.
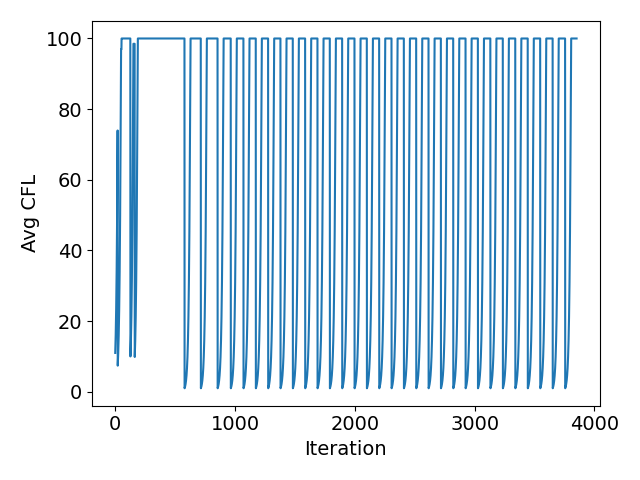
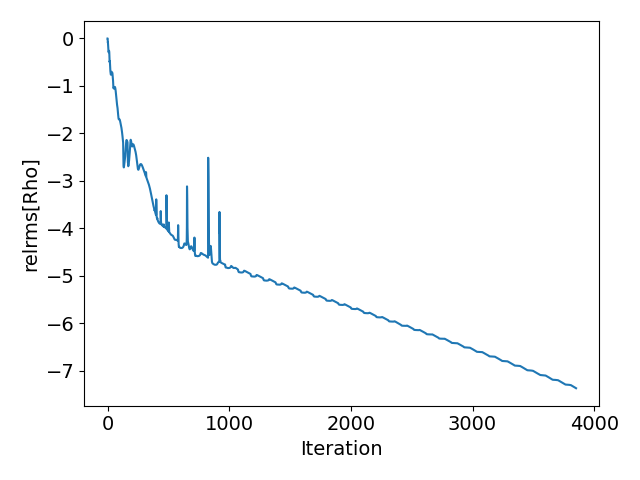
The new logic checking for oscillations in the non-linear residual works really well. For comparison I have included plots from before and after for a NACA0012 case with an anisotropically adapted mesh:
Before:
After:
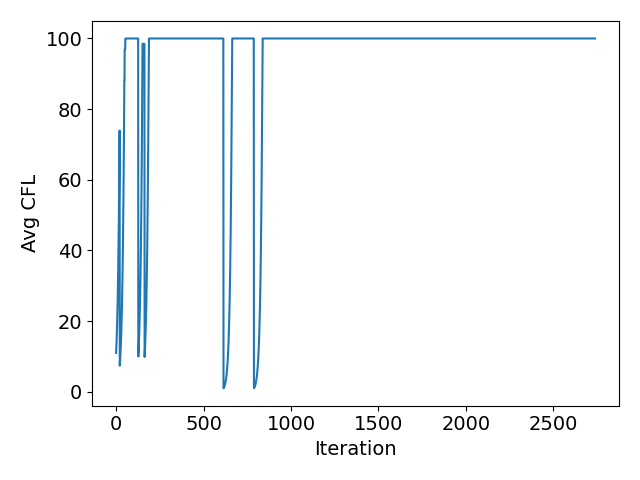
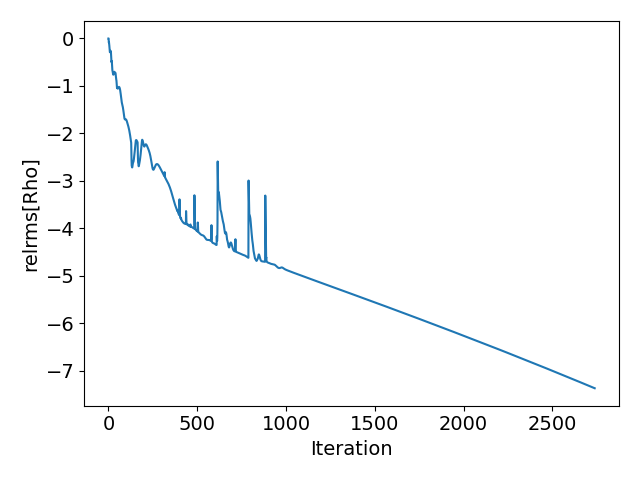
Notice how the average CFL oscillations have disappeared and that convergence takes fewer iterations. Great work @pcarruscag . Only request is to add the limit on the linear solver convergence to config_template.cfg.
| reduceCFL |= (signChanges > Res_Count/4) && (totalChange > -0.5); | ||
|
|
||
| if (fabs(NonLinRes_Value) < 0.1*New_Func) { | ||
| NonLinRes_Counter = 0; | ||
| for (unsigned short iCounter = 0; iCounter < Res_Count; iCounter++) | ||
| NonLinRes_Series[iCounter] = New_Func; | ||
| if (totalChange > 2.0) { // orders of magnitude | ||
| resetCFL = true; |
There was a problem hiding this comment.
Just to make sure I am following this correctly, this resets if the Non linear residual increases by 2 orders of magnitude? And it reduces the CFL if the non-linear residual oscillates 25% of the time AND there is less than a 0.5 order of magnitude reduction.
This seems to work as designed. Also I appreciate the flex with the XOR operator. Don't see that very often.
SU2_CFD/src/solvers/CSolver.cpp
Outdated
| const auto linIter = max(solverFlow->GetIterLinSolver(), linIterTurb); | ||
|
|
||
| /* Tolerance limited to a "reasonable" value. */ | ||
| const su2double linTol = max(0.001, config->GetLinear_Solver_Error()); |
There was a problem hiding this comment.
Might be a good idea to mention this limit in the config template
|
Thank you for re-testing Jayant. Out of curiosity did you manage to check what kind of tolerance seems "optimum" for adapted meshes? |
jayantmukho
left a comment
There was a problem hiding this comment.
Perfect! This is a really good addition and gets the solver to the point where it can arrive at an optimal CFL on its own. You can see that at work in the plots below. This is a NACA0012 case with the 4th level NASA TMR grid. I used CFL_ADAPT_PARAM= ( 0.95, 1.002, 10.0, 200.0 ). Towards the end, it is just about hitting Linear solver residual reduction of 1E-3 in the 10 iteration limit I specify.
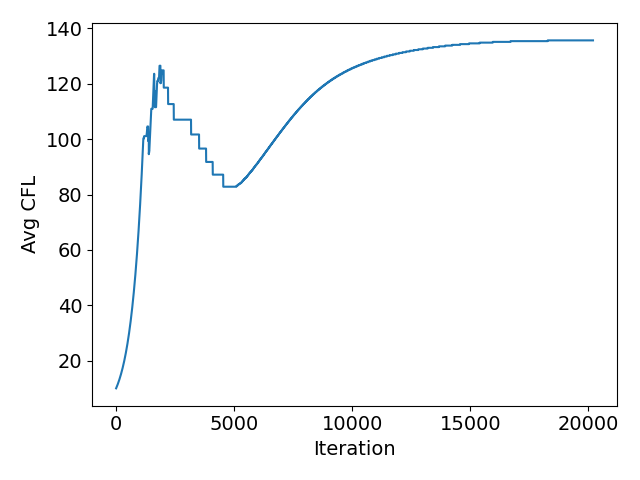
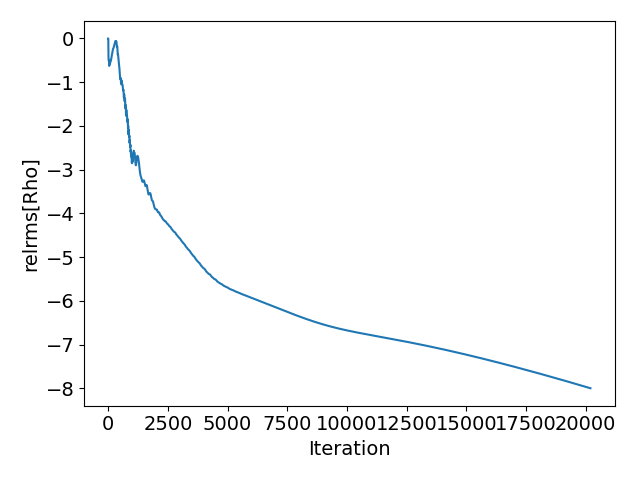
At that point, these new checks amount to having a proportional controller on the CFL that depends on the Linear Solver convergence and is robust with respect to non-linear residual oscillations and stagnation.
Proposed Changes
This PR fixes a couple issues in the nonlinear adaptive CFL scheme.
TimeIterwas used.@jayantmukho and I wanted to discuss more possible improvements to the scheme. I wanted to open this up before making any actual changes.
AdaptCFLNumberand compute their own local CFL based on their own ResRMS. I feel like this would make more sense since the solvers are decoupled anyway.PR Checklist
Put an X by all that apply. You can fill this out after submitting the PR. If you have any questions, don't hesitate to ask! We want to help. These are a guide for you to know what the reviewers will be looking for in your contribution.