Hybrid parallel Gradients and Limiters #834
Conversation
| void computeGradientsGreenGauss(CSolver* solver, | ||
| MPI_QUANTITIES kindMpiComm, | ||
| PERIODIC_QUANTITIES kindPeriodicComm, | ||
| CGeometry& geometry, | ||
| CConfig& config, | ||
| const FieldType& field, | ||
| size_t varBegin, | ||
| size_t varEnd, | ||
| GradientType& gradient) |
There was a problem hiding this comment.
The signature for these functions is a bit long... But by making the solver+mpi optional we can more easily devise unit tests or use the function for some other purpose.
I have also made these function able to compute gradients for only part of the variables, the idea is to use that to recompute only the velocity gradients before computing the turbulence source terms.
There was a problem hiding this comment.
I like the ability to choose variables to compute gradients for. Should trim some unnecessary computations.
| template<ENUM_LIMITER LimiterKind> | ||
| struct CLimiterDetails |
There was a problem hiding this comment.
The way I've come up with to create new limiters without copy pasting a similar implementation is to specialise this class template. I did not want to make this polymorphic.
| inline su2double raisedSine(su2double dist) | ||
| { | ||
| su2double factor = 0.5*(1.0+dist+sin(PI_NUMBER*dist)/PI_NUMBER); | ||
| return max(0.0, min(factor, 1.0)); | ||
| } |
There was a problem hiding this comment.
Initially I took this function from the sharp-edge limiter but I think it was incorrect (the way the distance was normalized and the bounds checking (replaced by min/max) did not seem to be continuous).
Now for distances less than the reference the "geometric limiter" is 0, at 3 times the distance the value is 1.
| case VENKATAKRISHNAN: | ||
| { | ||
| INSTANTIATE(VENKATAKRISHNAN); | ||
| break; | ||
| } |
There was a problem hiding this comment.
After specialising that class it is just a matter of adding the new case to this switch.
I tried to have this in a .cpp with explicit instantiation to avoid compiling the code for CSolver, CEulerSolver and CIncEulerSolver, but I was getting undefined references for AD builds.
| template<class FieldType, class GradientType, ENUM_LIMITER LimiterKind> | ||
| void computeLimiters_impl(CSolver* solver, |
There was a problem hiding this comment.
And this is the general limiter implementation, the idea is that this can stay independent of the particular details of each method.
For each point we loop over its direct neighbours, as explained in #789 this is faster than looping by edges as the computation is more local (more flops, less bytes), and it is more parallelizable.
| /*! | ||
| * \brief Get the reconstruction gradient for variables at all points. | ||
| * \return Reference to reconstruction gradient. | ||
| */ | ||
| inline VectorOfMatrix& GetGradient_Reconstruction(void) final { return Gradient_Reconstruction; } | ||
|
|
There was a problem hiding this comment.
To allow the new routines to work on primitives / solution CVariable needs to give access to the entire container... Not because the routine depends on a specific type of container, but to bypass the names of the AddGradient_XX SubtractGradient_XX methods.
To eventually vectorize the gradient and limiter computation only the container will need to implement "vector-accessors".
| PERIODIC_NONE = 99, /*!< \brief No periodic communication required. */ | ||
| PERIODIC_VOLUME = 1, /*!< \brief Volume communication for summing total CV (periodic only). */ |
There was a problem hiding this comment.
@economon the AuxVar did not have periodic gradient communications, so I had to add a do-nothing mode.
|
This just turned a month old :) If I could have some reviews please :) |
|
The residuals (and indeed the converged results) change for some cases due to these changes (by very small amounts). Looking at limiter fields there are some differences that justify this. Those differences are present mostly in smooth flow regions, why in this regions?
This is the flow field (for reference): This shows the x-mom limiters near the trailing edge for the develop version: And this for this branch: You can tell a slight "darkening" close to the blue spots, and also before the small spot close to the wall, before the shock. Near the periodic boundaries there are no visible changes. If you would like a specific test, or see some weird behavior in one of your cases let me know, but since only a few regressions changed I will only post comparisons of cases with substantial changes. |
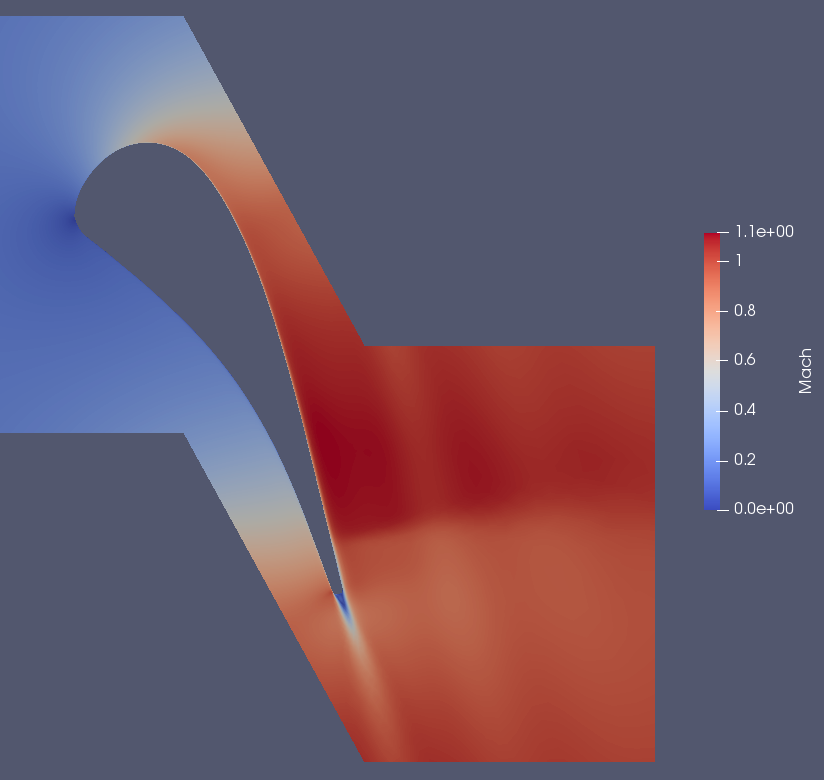
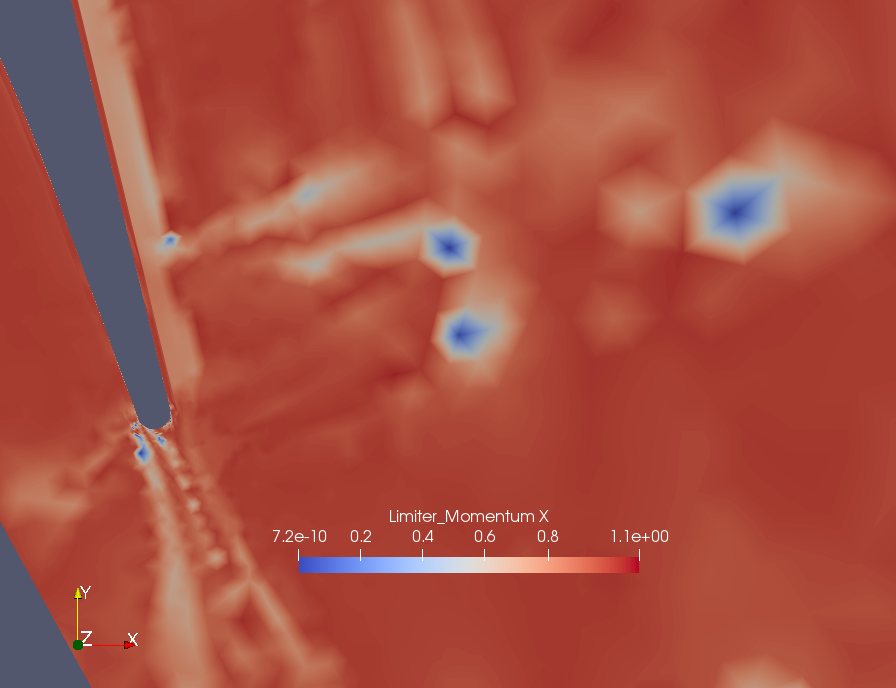
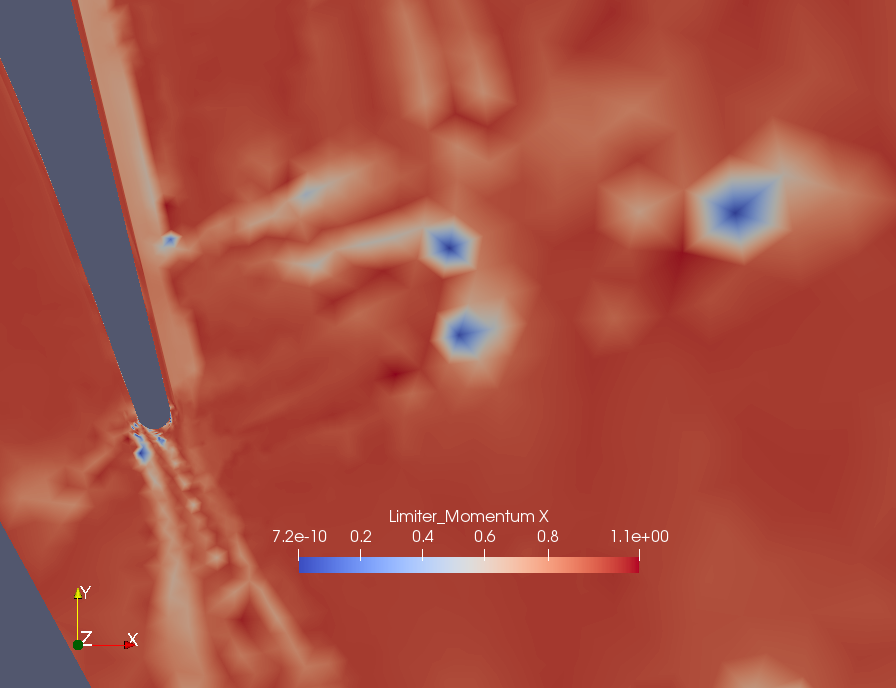
|
Of the two cases with larger residual changes:
I ran some other tests with the Venkatakrishnan-Wang limiter (which requires a global min/max) and is does not seem to be covered by the tests ATM (maybe I'll use that restart case to fix that), everything looks perfect, same results with different ranks/threads and so on, the results are tens of MB so I won't upload unless someone wants to double check. |
 jayantmukho
left a comment
jayantmukho
left a comment
There was a problem hiding this comment.
As always, a super clean implementation that'll help trim some code and some unnecessary calculations.
I can't pretend to follow how the OpenMP commands work but if it's faster and the solutions are the same, then I'm sold.
| void computeGradientsGreenGauss(CSolver* solver, | ||
| MPI_QUANTITIES kindMpiComm, | ||
| PERIODIC_QUANTITIES kindPeriodicComm, | ||
| CGeometry& geometry, | ||
| CConfig& config, | ||
| const FieldType& field, | ||
| size_t varBegin, | ||
| size_t varEnd, | ||
| GradientType& gradient) |
There was a problem hiding this comment.
I like the ability to choose variables to compute gradients for. Should trim some unnecessary computations.
| * \brief Set a small epsilon to avoid divisions by 0. | ||
| */ | ||
| template<class... Ts> | ||
| inline void preprocess(Ts&...) {eps2 = LimiterHelpers::epsilon();} |
There was a problem hiding this comment.
Had to look up what the ... was for. Didn't know about parameter packs, very cool.
Also super clean implementation of limiters.
There was a problem hiding this comment.
Thank you for the review @jayantmukho, to be honest I'm no specialist either, I am only using them to make those methods forward compatible in case some of the specializations need to be passed extra parameters in the future.
| void CFluidDriver::Output(unsigned long InnerIter) { | ||
|
|
||
| for (iZone = 0; iZone < nZone; iZone++) { | ||
| const auto inst = config_container[iZone]->GetiInst(); |
There was a problem hiding this comment.
Is there a reason to use auto as opposed to a specific type?
Also were different instantiations just not being output before you added these lines?
There was a problem hiding this comment.
Mostly because I find boring to write unsigned blabla all the time. It is a recommended practice in the book Effective Modern C++ (but for other reasons).
Neither zones nor instances were outputted before.
There was a problem hiding this comment.
is this still a problem in the SingleZoneDriver and MultiZoneDriver as well?
Its not really related to this PR, but might be worth addressing
There was a problem hiding this comment.
To my knowledge only the HBDriver deals with multiple time instances... so it should not be a problem for anything else.
| if (TapeActive) AD::StartRecording(); | ||
| #endif | ||
| computeLimiters(kindLimiter, this, SOLUTION_LIMITER, PERIODIC_LIM_SOL_1, PERIODIC_LIM_SOL_2, | ||
| *geometry, *config, 0, nVar, solution, gradient, solMin, solMax, limiter); |
There was a problem hiding this comment.
very satisfying deletion of duplicated code over the solver files 😃
 pcarruscag
left a comment
pcarruscag
left a comment
There was a problem hiding this comment.
Here is some explanation of the OpenMP stuff.
|
|
||
| /*--- Start OpenMP parallel section. ---*/ | ||
|
|
||
| SU2_OMP_PARALLEL |
There was a problem hiding this comment.
This starts a parallel section, the code within {} that comes after is executed simultaneously by the threads.
| SU2_OMP_FOR_DYN(chunkSize) | ||
| for (size_t iPoint = 0; iPoint < nPointDomain; ++iPoint) |
There was a problem hiding this comment.
This divides the loop over however many threads arrive here, without the worksharing construct the entire loop would be performed by each thread.
For reasons of spatial locality it is beneficial to divide the loop in chunks instead of individual iterations, in this case those chunks are assigned to each thread dynamically, this helps with load balancing but has some overhead. That is why you also see static work division for light loops (e.g. setting an array to 0).
There was a problem hiding this comment.
what is the chunkSize dependent on? Is it hardware? number of variables?
Does simply adding SU2_OMP_FOR_DYN(chunkSize) before the for loop automatically run the loop in chunks? (assuming you add relevant includes and calls beforehand)
Does anything new need to be done in how the code is compiled or run to ensure that multiple threads are used?
There was a problem hiding this comment.
The size is usually based on amount of work per loop iteration, if the loop is heavy a small size can be used to improve load balancing, otherwise a relatively large size needs to be used to amortize the parallelization overheads. Currently most sizes are determined such that each thread gets on average the same number of chunks but each chunk is no larger than a maximum size, there is an utility function in omp_structure.hpp for this.
Yes, distributing the work over the threads that arrive at that location, if only one arrives the code still executes properly.
The build system was updated in #843 since that introduces the first solver that is completely hybrid parallel, there is no advantage in using the feature for fluid solvers yet.
Basically you add -Dwith-omp=true to meson, the number of threads per rank can be specified with the -t option when calling SU2_CFD, e.g. mpirun -n 2 --bind-to numa SU2_CFD -t 8 config.cfg if -t is omitted the number of threads is whatever is defined for the environment.
|
|
||
| if (solver != nullptr) | ||
| { | ||
| SU2_OMP_MASTER |
There was a problem hiding this comment.
This is the OpenMP equivalent of rank == MASTER_NODE.
Proposed Changes
Compute Green-Gauss gradients and limiters via a point-loop (like we do for Least Squares), in the limit this allows one thread per point of parallelization. Parallel regions are started inside the functions and again only the master thread calls MPI routines.
Move these routines out of CSolver and make them general to reduce code duplication (compressible/incompressible, solution/primitives), and to improve test-ability (if key areas of the code depend less on large objects we can more easily treat them as units).
Introduce a way to create different limiters by defining small details like the limiter function (and its associated constants), or any geometry-based modification.
I don't seem to have "hard" failures in the regressions but I need to run tests, especially for periodic cases as I had to change the "communication model" for the min / max computed for limiters.
I will start documenting anyway.
Related Work
#789 #824
Depends on #830
PR Checklist