深度学习研习,包括训练,部署等
NVIDIA Megatron 是一个基于PyTorch 的框架,用于训练基于Transformer 架构的巨型语言模型 Megatron设计就是为了支持超大的Transformer模型的训练的,因此它不仅支持传统分布式训练的数据并行,也支持模型并行,包括Tensor并行和Pipeline并行两种模型并行方式。
- [细读经典]Megatron论文和代码详细分析(1)
- NVIDIA Megatron:超大Transformer语言模型的分布式训练框架
- 知乎提问:对大规模 model training 感兴趣,请问有相关推荐的文章吗?
-
论文《 LoRA: Low-Rank Adaptation of Large Language Models》
-
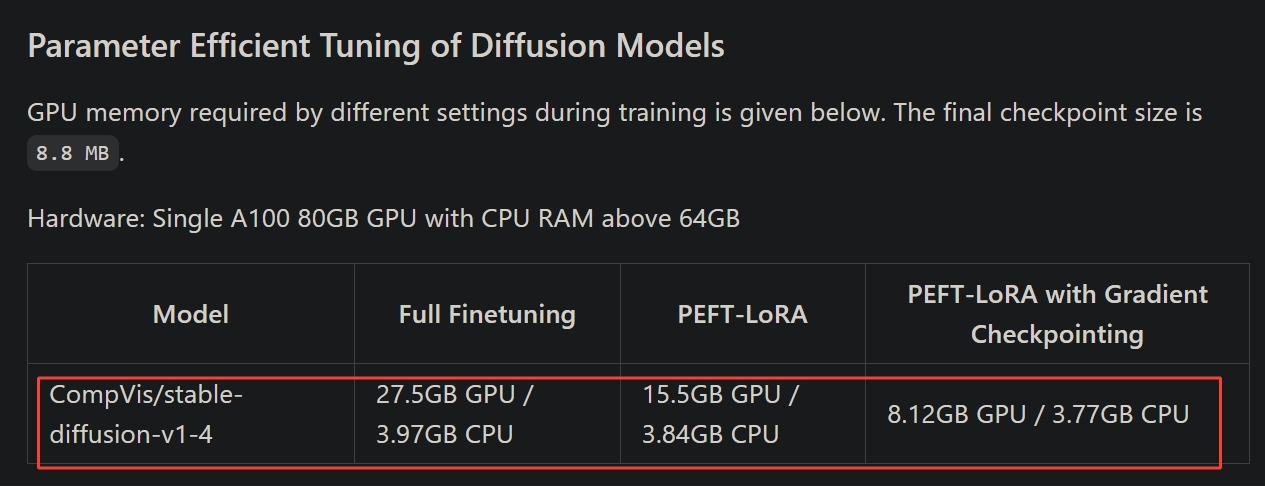
huggingface/peft, https://github.com/huggingface/peft
Parameter-Efficient Fine-Tuning (PEFT) methods enable efficient adaptation of pre-trained language models (PLMs) to various downstream applications without fine-tuning all the model's parameters.
Supported methods:
- 1, LoRA
- 2, Prefix Tuning
- 3, P-Tuning
- 4, Prompt Tuning
- 5, AdaLoRA
下面的评测方式推荐: