Data model design
This page describes a planned 2.0 revision of the Semantic Synchrony data model and protocol, as well as related changes to the SmSn-mode UI. The high-level goals of this revision are to make the interface more wiki-like while also increasing semantic expressiveness. In particular, the new model should be particularly friendly to free-form text and wiki-like formatting, and it should make it easier to map wiki content to statements and meta-statements in structured vocabularies.
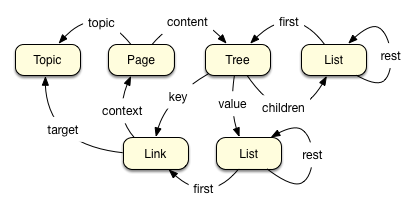
As in the current SmSn, concepts or topics will be "atoms", each of which has mandatory and optional properties, as well as optional links to other atoms. Outbound links are to retain their well-defined order.
Required properties:
- atom @title -- attached to an atom, a title provides a universal name for the atom. It does not need to be unique. This is the title of the atom's dedicated view, seen as a wiki page.
- atom @weight -- a basic indication of emphasis or importance. An atom's weight influences how it is displayed, as well as its ranking in search results.
- atom @sharabililty -- a basic visibility control, similar to a security classification level. Atoms which are less sharable than the current view are not seen in that view.
Optional properties:
- atom @alias -- an identifier, in an unstated scheme, for the atom in some other database or data set. For example, Web URLs and Semantic Web IRIs are used to link atoms to web pages or non-information resources.
- atom @priority -- a TODO marker and indication of urgency
- atom @shortcut -- a short name for an atom, used for quick retrieval. For example, the @shortcut for John Doe might be "jd", or even "me".
- section title -- an atom's title can be overridden in a particular context, seen as a section heading in another atom's view.
It must be possible to edit an atom as a textual buffer using wiki syntax. Minimal restrictions are to be placed on the format of the content, but there must be a straightforward mapping from wiki content to structured content. Headings, links, and free-form text will appear similar to a wiki format such as Markdown, with an easy transition between editable text and HTML markup. However, these syntax elements are to be given special significance (as in the current model), with headings, parent-child, and sibling relationships foremost.
A simple line of text will be similar to a child atom in the current model, but need not be bulleted as a list item. Each line has an identity as an atom; it may have own content nested under it, although that content may not be visible in its parent's view.
No special treatment is currently planned for ordered lists; the way to express relationships is with headings and links. Bulleted lists will simply be atoms in the new model, no different than non-bulleted lines of text. The relationship between an inline parent of an ordered list and the list elements, as well as the relationship between a list element and nested elements, will not receive special treatment.
As in a typical wiki, it is possible to link to a topic -- an atom -- from within a line of text. External web links will also be supported. The link can further be annotated with a "predicate" which defines the relationship between the parent and the object of the link. Whereas in the current model such predicates are inferred automatically, in the new model they are to be suggested and then accepted, or simply added manually.
Headings in wiki pages, such as the section title "Headings" above this text, not only help to break up the text into understandable pieces, but ideally tell us how the section content relates to the topic, as well. Going forward, SmSn will make use of section headings which are identified, like every line of textual content, with an atom. Atoms which are frequently re-used as headings will take on a certain semantics, such as the heading Languages under the atom for a country such as France or Germany; Languages provides a link between a country and its languages.
SmSn will have the equivalent of a topmost section with no heading, followed by labeled sections. Each section contains its own text and subsections. The semantics of the topic-heading-content relationship are not predefined, but it will be possible to specify semantics in terms of the identities of each element.
A major change to the data model includes the notion of a section, or context, as well as a line-by-line approach to free-form atom content.
Currently, an atom has a simple list of children. The child atoms may themselves have children, and so on, but an atom has no special relationship with its grandchildren. A grandchild is simply a child of a child. The new model is to include context-specific grandchildren.
For example, the country of France may have a section with the heading Languages, under which the concepts of French, German dialects, and Celtic languages are provided as sub-sections. The relationship between France and French involves the concept of Languages, while French is not necessarily a child of the concept of Languages. Languages, or language, will have its own content, such as links to concepts like linguistics and history of language.
If we suppose that the sub-section German dialects has a further sub-section, Alsatian, then we have a chain France->Languages->German dialects->Alsatian. It is up to the content owner to define the semantics, if any, of that type of chain. Again, the concept German dialects may have its own content independent of the section context France->Languages, which may or may not include Alsatian.
Each context contains:
- a title (see above)
- a list of simple content atoms, seen as header paragraphs in a wiki view (see above)
- a list of sub-contexts, seen as sections with headings
Ideally, the entire revision history of an atom should be accessible for the purpose of audit and rollback. As in a collaborative version control system, it should be possible to work with history in the form of line diffs, including metadata for time, author, and even commit messages. This should go hand in hand with a graph versioning solution tailored to the data model.
Linked Data principles should be used to seamlessly merge one's own content with external content made available on the Web. It should be possible to link from own atoms to atoms with a Web identity, and to add to or modify their content while preserving a clear distinction between own content and inherited content. See "revision history" above.
Currently, data views are specified in terms of a few simple variables: view direction (forward or backward), view depth, and filter thresholds. In the new data model, an atom can act as a leaf node in any number of trees, and also as a root node in any number of trees. Many different kinds of views/lenses are possible, but a new language is needed to read from and write to them.
In connection with revision history (see above), it would be very useful if groups of graph changes could be undone and redone. This will become especially important if batch updates are supported, as these will be difficult to recover from manually.
With the ability to give atoms a PKB-independent identity, it will be possible to converge on vocabulary for common patterns of interest. Such vocabulary might deal with:
- source and attribution -- for the sake of giving or retaining credit, and respecting copyright
- emphasis, sharing, and priority -- augmenting or replacing the simple properties for these dimensions
- intention -- indicate the purpose of the information, such as notes for own use vs. a tutorial page
- belief and trust -- what is the author's attitude toward the information? Is it trusted? Is it believed to be true, and if so, by whom? Is it to be understood as a hypothesis, an opinion one disagrees with, or just a funny idea?
Rather than treating atom text as opaque (disregarding embedded links), some users may wish to enter and view text in a particular shorthand or controlled format. In this case, the text is to be parsed whenever it changes, translating it to corresponding graph structures. Conversely, text may be generated as a representation of the graph structure. A framework for expressing and maintaining such text/graph correspondences, or for deriving them on the fly, is needed.
How IDs, IRIs, URLs and pages will work:
- every topic has an ID. In the new model, a topic is nothing more than the ID, e.g.
qAnrxm0gmzccMsYzfor the concept of Komodo dragon. This is the identifier of the topic in a SmSn context. - for every ID, there is an associated IRI, e.g.
smsn:qAnrxm0gmzccMsYz(IRI scheme or namespace to be determined; the example assumes a "smsn" scheme). This is the identifier of the topic in a Semantic Web context. - topics are described by pages, which have URLs based on the topic ID and a title. E.g.
http://fortytwo.net/things/qAnrxm0gmzccMsYz/Komodo_dragon. As I have suggested, the title is not essential to the URL, and other titles are equivalent for the purpose of retrieving the page. This way, the title is free to change over time, while the ID remains constant. Page URLs are the identifier of a topic in a Web browsing context. - pages are contained in namespaces, e.g.
http://fortytwo.net/things, which correspond to Git repositories or other SmSn datasets. - datasets are sets of pages. A dataset can be published in more than one namespace, but you can't have more than one dataset per namespace, nor more than one page for a given topic in a given namespace.
...