Semantic Search
Embeddings are a way to represent text as a vector in a high-dimensional space. The distance between two vectors can be used to measure the similarity between the texts they represent. This powerful principle allows for semantic search, where the meaning of the text is taken into account, not just the words.
However, for embeddings to add value, context is required. Bare bookmarks do not provide a lot of content to work with.
bkmr uses the title, tags and comments as input to the OpenAI Embeddings API.
The more context you add via comments, the better the results will be.
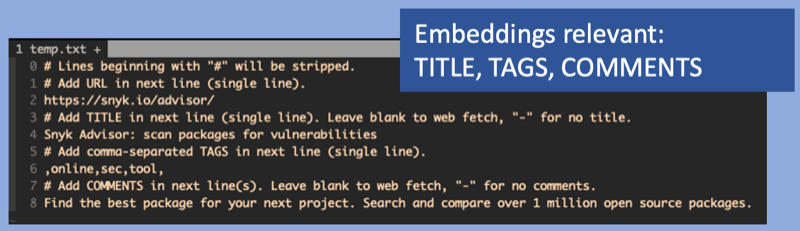
The --openai flag enables semantic search using OpenAI's Embeddings. The OPENAI_API_KEY environment variable must be set.
- embeddings will increase DB size since every embeddings has got 1536 dimensions.
- requires the
--openaiflag.
export OPENAI_API_KEY=<your-key>
# Use semantic search
bkmr --openai sem-search "python security" # requires OPENAI_API_KEY
# Search DB for bookmarks which do nat have embeddings and create them
bkmr --openai backfillbkrm is smart enough to only reach out to OpenAI if the bookmark has changed. It maintains a content checksum.
If you do not want to use this feature, just do not set --openai. Everything works just fine without
semantic search.
bkmr data model is flexible enough to generalize the idea of semantic search to arbitrary data.
When interpreting the URL as a local file, the file content can be used as input to the OpenAI Embeddings API.
After importing the data, the bookmark table will hold the embeddings with its associated URL or file path.
bkmr --openai load-texts tokenized.ndjsonThe tokenized.ndjson file must contain a list of dictionaries with the following keys:
-
id: unique identifier (URL or file path) -
content: the text to be embedded for semantic search
Example:
{
"id": "$VIMWIKI_PATH/help/qk/quarkus.md:0",
"content": "..."
}
{
"id": "$VIMWIKI_PATH/help/qk/quarkus.md:1",
"content": "..."
}
{
"id": "$VIMWIKI_PATH/help/qk/quarkus.md:2",
"content": "..."
}prepembd is a little utility to scan a directory for markdown files
and create a tokenized.ndjson input file for bkmr --openai load-texts. It allows for filtering of sensitive data
and ensures that the chunk size is not too large for the OpenAI API.