DL with h2o #28
Comments
|
@arnocandel: any comments/suggestions on the above? #28 |
|
Yes, after a bit of tinkering, I also cannot get higher than 0.735 test set AUC. On my i7 5820k home PC: system.time({ user system elapsed h2o.performance(md, dx_test)@metrics$AUC Adding input_dropout_ratio=0.2, l1 = 1e-5, l2 = 1e-5, hidden_dropout_ratios=c(0.4,0.3,0.2) didn’t change much, since the above setting has plenty of regularization (0.5 hidden dropout throughout). A faster way to get to 0.733 (here with input dropout on a smaller network, hidden dropout would hurt too much, not enough hidden neurons): system.time({ user system elapsed h2o.performance(md, dx_test)@metrics$AUC The DepTime feature has the highest importance (set variable_importances=T), so I’d suggest doing some feature engineering (e.g., cutting the original DepTime into 48 categorical half-hour slots). Out of 675 input neurons, only 2 are always populated with non-zero values (the two numeric features), and 673 values are mostly 0, only 6 categoricals are set to 1. That’s where the inefficiency comes from. GBM/DRF are much more efficient at simply cutting up the feature space, which is was seems to be needed here. Best,
|
|
Thanks @arnocandel for help and insights. I'll try to do some feature engineering and see if that helps. However, the main point of this project is what tools/algos work out-of-the-box. DL does not need to be the best in everything, it is certainly best for images and a few other domains, and surely on the Higgs data that I also looked at in this project same https://github.com/szilard/benchm-ml/tree/master/x1-data-higgs I wonder if the problem you mentioned in the last paragraph is in general with datasets with categorical features with medium/high dimensionality (which is very common in business datasets of the like of credit scoring, fraud detection etc.) I don't see much public materials about DL for these kind of biz problems, except maybe the Paypal talk at H2O World 2014, but they did not compare there with RF/GBM. Any ideas about this? (i.e. DL for "biz" problems non-image, non-speech...) |
|
H2O DL is certainly applicable to common business datasets, but unfortunately there aren't too many great public-facing benchmark blogs like yours :) The main reason holding back DL in many business use cases is the lack of transparency/interpretability more than the lack of accuracy, I think. High cardinality categorical datasets can be problematic and we have several ways to deal with them, in order of quality (best to worst):
In general, the beauty of DL is that it can quickly build “good” enough models that are often significantly more accurate than GLM, and most of the time nearly as accurate or even competitive with tree models. All you need is hidden=c(20,20,20) or something like that for a model that’s very fast to train. Another benefit is that the resulting POJO model is smaller than a tree model, and might be faster to score as well. Obviously, the smaller the number of neurons, the faster the scoring (L1/L2 cache effects). Since it’s totally different than a tree model, it’s an excellent ensemble member for stacking / metalearning. Lastly, DL also handles N-class problems more efficiently than other models (the cost grows typically much less than N times, as only the output layer is affected).
|
|
Thanks @arnocandel for further insights. I'm having greater success with a non-public dataset with a few more features, but still mainly categorical variables. I actually dropped a few variables of high cardinality (DL was erring out initially) - that's the last on your list but the easiest to do ;) The AUC's I've got are GLM 0.68 DL 0.86 RF 0.87 GBM 0.88 with just a bit of playing in the hyper parameter space, so DL is way better for that dataset. I'll also try ensembles soon. One still open question I have for you regarding the airline dataset is about DL finishing with early stopping so soon: The "problem" is DL learns very fast, the best AUC reached after 1.3 epochs on 1M rows train and 0.15 epochs on 10M (and early stopping kicks in around 9 and 0.9, rsp). On the other hand RF/GBM runs ~1hr to get good accuracy. That is the DL model seems underfitted to me. What do you think? |
|
Thanks Szilard, that’s great and in line with my experience :) For early stopping, you can simply specify more stopping_rounds to wait until it “really” doesn’t improve anymore. You can try stopping_rounds=10, for example. Note that it then takes at least 20 scoring events to even consider early stopping in that case, so you need to make sure it scores often enough (but not too often), otherwise you might overfit before then. It’ll take 10 scoring rounds to compute the moving average of length 10, and then 10 more scoring rounds to see if any of them isn’t better than the last scoring event. The default settings are usually fine, but you then want to control the size of your validation dataset to avoid slowness in scoring (as it won’t score more than for 10% of the time by default), for large models. DL with 1000s of neurons can take a long time to converge, but I doubt that it’s going to get much better than 0.74 ever. Too little signal/noise on the expanded categoricals.
|
|
I tried several values for early stopping before, what I was trying to say is that training stops "very early" (maybe 10 epochs) and the optimal AUC on validation happens even earlier ~1 epoch for 1M records dataset and even 0.1 epochs (!!) for 10M dataset. Do you think things would improve (as final AUC) if instead of adaptive I would use manual learning rate (and a small one?), or adaptive is almost always at least as good or better? |
|
Yes, to see if it learns too fast, you can tune rho/epsilon for adaptive_rate=T or rate{,_decay,annealing} and momentum{start,ramp,stable} for adaptive_rate=F. nesterov_momentum and fast_mode rarely need to be changed.
|
|
I'll try that because "learning is fun", but since you say you've been playing around a bit, I see little chance that I would find a better setting. What do you think about this: it seems to me that the model settings we played with should have the complexity/capacity enough to do a good representation/function approximation and therefore better AUC. In that case we are just not able to get to the global minimum, but we are stuck (quite rapidly) in some far sub-optimal local minimum? |
|
Yes, it would appear that way. Here’s a comparison of DL vs GBM for a “rough cut” model:
So not bad for out-of-the-box performance for people who just need a small model to put into production that works and beats most other models. GLM gets 0.709 in 11 seconds. But yes, it seems that the optimization precision of hundreds or thousands of tree models is not easily obtained for DL here.
|
|
Just got 0.735074 with hidden=c(10) and early stopping based on validation AUC in 60 seconds… so it really doesn’t need much complexity to get there.
|
|
Cool, thanks Arno! So the last one you did is a "traditional" 1-hidden layered NN Just for fun i did |
|
BTW, one more thing for Higgs: If you ignore the last 7 features, and only use the first 21 features, then DL will beat all other methods (GBM,DRF,GLM) by a much larger margin (0.86 vs 0.76). See http://www.slideshare.net/0xdata/h2odeeplearning/32 for example. |
|
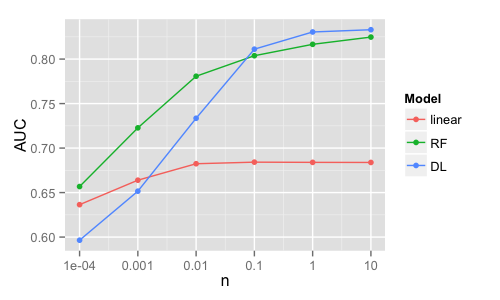
Yes, I've seen your slides on Higgs. That was actually the main reason I added Higgs to the benchmark, hehe. :) The thing I'm interested also is learning curves. My conjecture is that on dense data all linear models will reach capacity soon and will not get better AUC with larger data. For a few datasets (airline/Higgs/etc) RF was beating GLM even on small samples (but in theory GLM's high-bias low variance could beat RF's lower bias, higher variance(?)) If you look at DL vs GLM or RF here https://raw.githubusercontent.com/szilard/benchm-ml/master/x1-data-higgs/3a-AUC.png With different hyperparam values for DL across the sizes (tuned for each size), I'm sure DL would beat GLM, but maybe even RF for Higgs across all sizes. The conventional wisdom is that DL needs more data, so maybe it will beat RF only on larger data and the curves would still cross. I should play around with this. |
{kind=link}
Trying to see if DL can match RF/GBM in accuracy on the airline dataset (where train is sampled from years 2005-2006, while validation and test sets sampled disjunctly from 2007). Also, some variables are kept categorical artificially and are intentionally not encoded as ordinal variables (to better match the structure of business datasets).
Recap: with 10M records training (largest in the benchmark) RF AUC
0.80GBM0.81(on test set).So far I get
0.73with DL with h2o on 1M and 10M train as well:https://github.com/szilard/benchm-ml/blob/master/4-DL/1-h2o.R
I tried a few architectures/activation/regularizations, but it won't beat the default. Runs about 2-3 minutes with early stopping (using validation set) on a 32 cores EC2 box.
The "problem" is DL learns very fast, the best AUC reached after 1.3 epochs on 1M rows train and 0.15 epochs on 10M (and early stopping kicks in around 9 and 0.9, rsp). On the other hand RF/GBM runs ~1hr to get good accuracy. That is the DL model seems underfitted to me.
Surely, DL might not beat GBM on this kind of data (proxy for general business data such as credit risk or fraud detection), but it should do better than
0.73.Datasets:
https://s3.amazonaws.com/benchm-ml--main/train-1m.csv
https://s3.amazonaws.com/benchm-ml--main/train-10m.csv
https://s3.amazonaws.com/benchm-ml--main/valid.csv
https://s3.amazonaws.com/benchm-ml--main/test.csv
The text was updated successfully, but these errors were encountered: