![]()
- Skeletons

- Auto refetching

- Prefetch

- Window refocus refetching
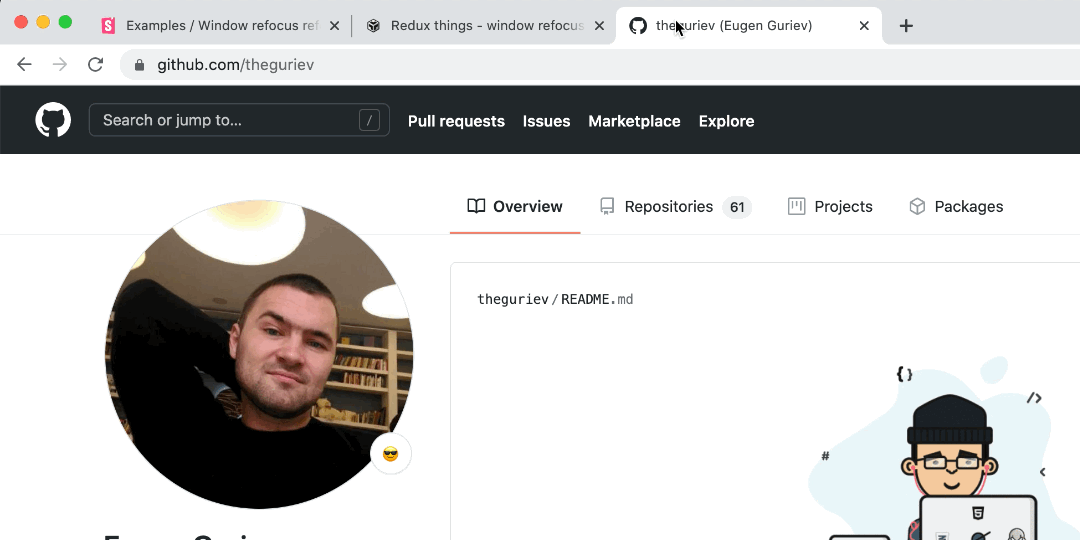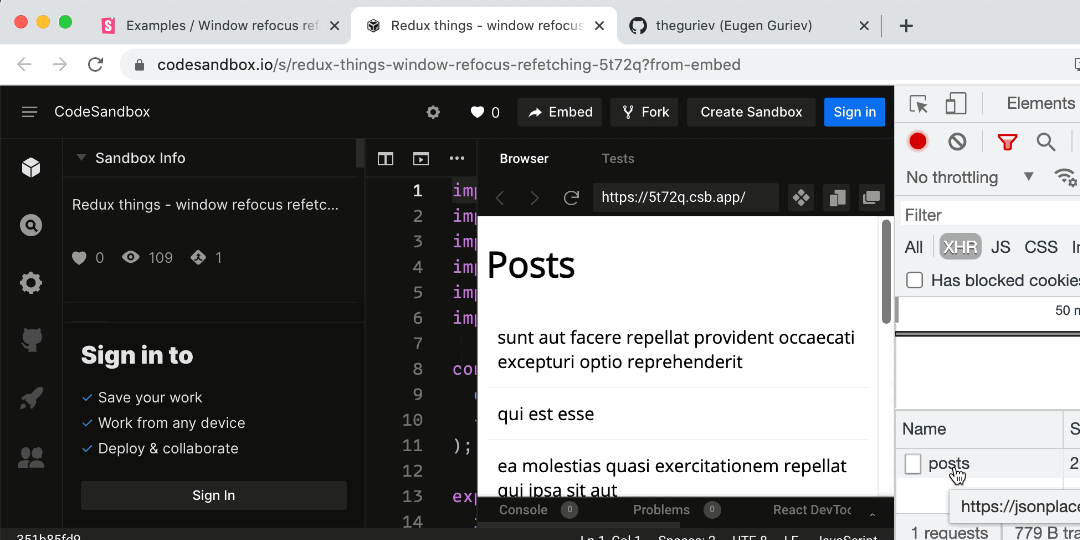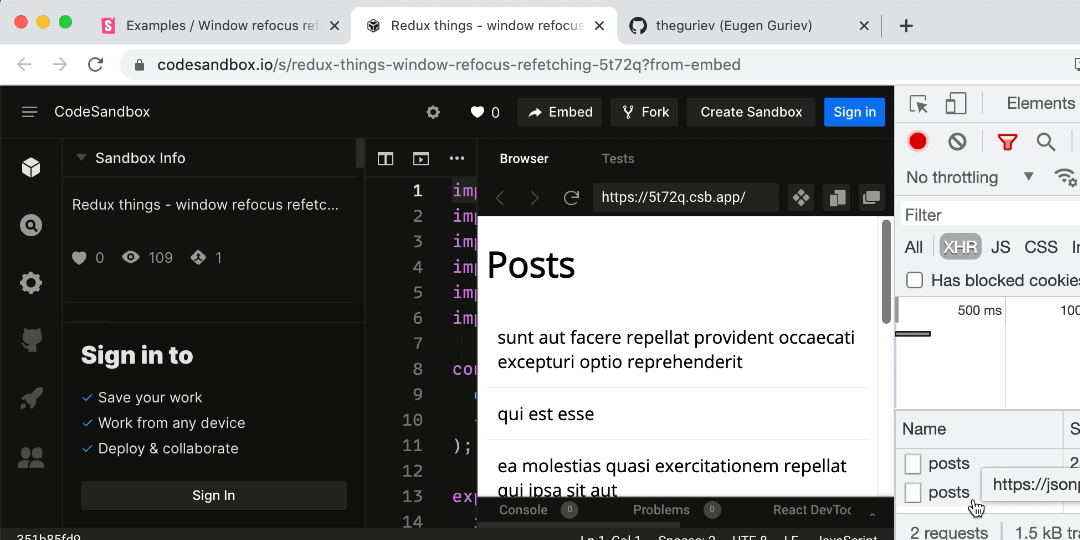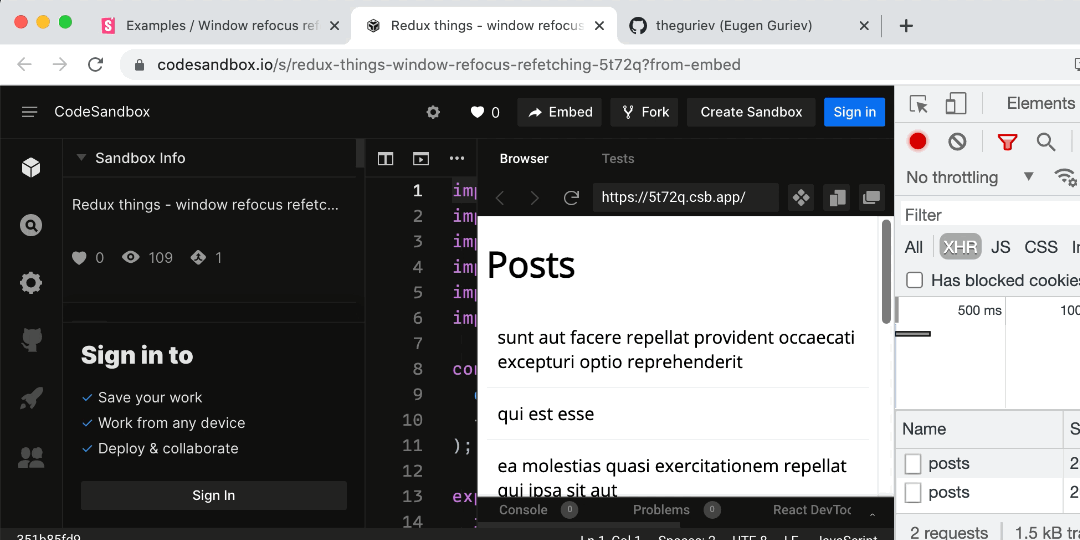
- Debouncing
- Dependend things
- And many more...



- It's easy and fast: Writing your data fetching logic by hand is over. Tell Redux Things where to get your data and how fresh you need it to be and the rest is automatic. Redux Things handles caching, background updates and stale data out of the box with almost zero-configuration. If you know how to work with promises or async/await, then you already know how to use Redux Things. Simply pass a function that resolves your data (or throws an error) and the rest is history.
- Easy integration: All your previous legacy stuff will work as it was before. Nothing new. So, you do not need to demolish the house when the roof is leaking. There's no magic here, just middleware, actions, selectors, and async reducers.
- It's extensible: Built to fit most use cases out-of-the-box, but can easily be extended with custom Redux middleware, sagas, UI integrations, network interfaces, etc.
You no longer need to worry about DDos on your own backend server. Requests will occur only when there is no data in the redux store. You can even use custom selectors, this will allow you to extract data from an external redux thing, which in turn reduces the number of requests to the server. Example:
// Request 1
/api/posts
[
{
id: 1,
title: 'Super Cool post 1'
},
{
id: 2,
title: 'Super Cool post 2'
},
{
id: 3,
title: 'Super Cool post 3'
}
]
// A request that does not launch because the data is already in the redux store
/api/post/2
{
id: 2,
title: 'Super Cool post 2'
}
Even if you run a million hooks from different components at the same time, only one request will be processed. This is very good because it does not restrict you from using it everywhere.
You can preload data and use it when you need it. This will help improve the user experience due to the responsiveness of the interface. Fast speed = happy users 😊