Training of the networks
Training of a network means basically adjusting its weights in order to fit it to the function of the inputs to the desired outputs. This way the model learns to predict the classes even for repositories it has never seen before. The only thing we have to do is show the network our sample inputs, let it do its prediction (which is random at the beginning of training) and give it a feedback. This is called Supervised Learning.
This section describes the training of each network which is basically the same procedure for all.
The first thing one has to do to prepare a net for training is to initialize the weights. You could either say, they will be trained anyhow, so let's just set assign them to a constant value ((\neq 0), because 0-weights would propagate nothing). But the problem with this is that the back-propagated error will be the same for each weight which makes the model unable to learn.
So what you definitely do is, you take initial weights from a random distribution like a Gaussian (bell curve) or a uniform distribution. In this case you have to specify the range, i.e. a min and a max weight, and commonly you center the distribution at 0, so you have negative weights, too.
Even better is to choose the range for initialization with respect to the size of the layers ((in) and (out))the weight is between. As Xavier et. al. suggested in 2010, one should rather use a range of ([-x, x]) with (x = \sqrt{6/(in, out)}) for uniform distributions or a standard deviation of (\sqrt{3/(in, out)}) for Gaussian. That's how we do it.
After initializing the weights, the network is able to propagate its input towards the output layer. It gets one input of our dataset at a time, one after the other. When the whole samples are seen once, we call this an epoch. However, for convergence to the global minimum the net will need many of these epochs. How many, is really a matter of choice, if you are satisfied with the result you can stop training. Of course you should stop earlier if you see that it does not make any learning progress any more, whatever the reason.
During the training we need to provide the feedback. There are different timepoints when you can do this: Either you do it after each sample (Stochastic/online learning) or you accumulate the error for all samples and only update the weights after an epoch is finished. In the first case, the learning will fluctuate very much, in the latter it will be inflexible in terms of reacting differently to different inputs. A good compromise is to use so-called (mini) batches that consist of a subset of samples, say e.g. a 10th of the whole dataset. Giving the feedback after each batch makes learning much more stable and efficient. Again, the size of the batches is a value that is individual for each classification and comes from experience. We use batch sizes of 200-300 samples.
Another preparation concerns the order of the training samples. They should be learned in a way that each sample is independent from its predecessors, i.e. consequent samples should not be of the same category. Otherwise the network would specialize into one category too much and does not generalize so easily. This can be prevented by shuffling the data before training.
As stated above, Supervised Learning is based on giving the network a feedback. This feedback is proportional to the error it makes for each sample (x \in X), so we need to define an error function, aka. a Loss function. It is supposed to measure the 'distance' between the generated output (\hat{y}) and (y \in Y), the actual output, in our case the real category of repo (x). Let's assume there are (N) training samples in the following. There are different measurements in use, for example the root mean square error (RSME) defined for numeric classes as follows: [RMSE(Y, \hat{Y}) = \sqrt{\frac{1}{N} \sum_{i=1}^N (y_i - \hat{y}_i)^2}]
The one we are using is a bit different because it does not make too much sense to subtract class labels (even if we encoded them numerically). Instead we use the so-called Cross-entropy loss defined like this: [CEL(Y, \hat{Y}) = \frac{1}{N} \sum_{i=1}^N H(y_i, \hat{y}_i)]
where (H) is the cross entropy which one can think of as the probability for a sample of being in class (\hat{Y}) while actually being in class (Y) (here for one-hot encoded outputs): [H(Y, \hat{Y}) = - \sum_{y \in Y} y \log \hat{y}]
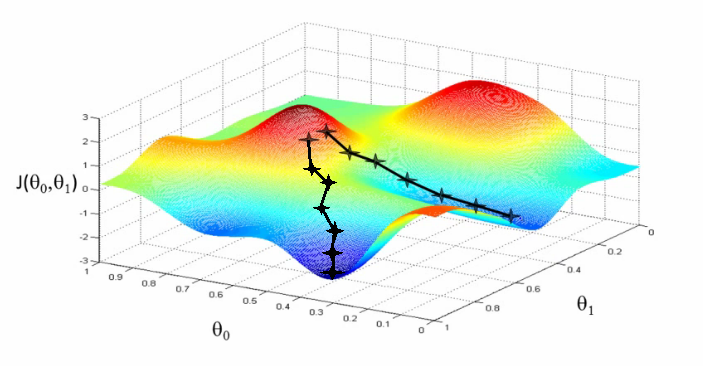
Now that we have an loss function, we want to minimize the error, i.e. we want to find a (hopefully) global minimum on its surface [1]:
{kind=link}

This is done by adjusting the weights (in the image there are only two, depicted as (\theta_i)) in a way that leads us to the valleys of the function. This in turn can be achieved by calculating the gradient of the loss function, i.e. the derivative with respect to each weight. Intuitively, one can think of the gradient as a vector pointing to the steepest direction of the error surface. Because we want to 'go down the hill', we take the negative derivative: [w_{new} = w - \eta \cdot \frac{\partial CEL}{\partial w}]
(\eta) is a proportional factor called the learning rate, a value that we can think of as constant for now.
We do this update for all the weights starting at the last weight layer. The layers before are a little bit more complex to update, but there is an algorithm for that: Backpropagation of Error or just BP. As the name suggests, the updates are performed from the output layer backwards, again by differentiating. This involves repeated use of the chain-rule over all the activation functions until one arrives at the desired weight. Suppose, we have the following chain of neurons (i), (j) and (k) in the net...

In this situation, you would calculate the update (\Delta w_{i,j}) by: [\Delta w_{i,j} = \frac{\partial CEL}{\partial \sigma(k)} \cdot \frac{\partial \sigma(k)}{\partial relu(j)} \cdot \frac{\partial relu(j)}{\partial relu(i)} \cdot \frac{\partial relu(i)}{\partial w_{i,j}}]
Luckily this is done by the Tensorflow framework for us ;)
The real difficulty with gradient descent approaches is to find a good global minimum. This does depend on your choice of the learning rate. If you choose it too small, gradients will be weighted very low. That means, if you are on a flat place you will get stuck eventually. On the other hand, if (\eta) is too high, you would do big jumps on the error surface and may end up jumping back and forth over a valley. The best of the two worlds is to make (\eta) dependent on the training cycle, i.e. decrease it over time. This resembles the way humans would learn, namely beginning in big steps and later doing the fine tuning. In our implementation we use a starting (\eta_0) of 0.001 and an exponential decay factor of 0.999.
Another way of optimizing gradient descent is to consider gradients from earlier training cycles. This is useful if you have sparse data and some of the inputs are very rare. Then you might want to perform a bigger update for infrequently used weights. An algorithm can do this by storing the average of the last updates per weight.
Both is done by the ADAM (Adaptive Moment Estimation) optimizer. For more information see original paper.
Another method for tweaking gradients is so-called gradient clipping. It is a rather rigorous approach that cuts of gradients, that exceed an upper limit (in our case a value of 5.0). It has the purpose to prevent exploding gradients.
Also we define a dropout-probability, that is a probability allowing the network to ignore a neuron during training. The problem with large nets is that they tend to overfit and, in fact, only train parts of its structure. A dropout forces the net to use all neurons in order to maintain plasticity. We choose dropout-to-keep a ratio of 0.5.
Last but not least, we use so-called L2 regularization. This is another way to prevent over-fitting and urging the network to have small weights. It uses the mean squared error of all current weights and subs tracts it from each weight as a penalty, independently from the loss function.