Full Text
Approach
FFN
CNN
RNN
Ensemble
Training
Results
Discussion
When approaching this competition, we decided early on that various forms of neural networks could be an interesting and powerful solution to the task. We proceeded to seek out state-of-the-art designs of various kinds of neural networks fit to the various forms of data we could extract and developed classifiers building on that.
While some of these classifiers did not fulfill our expectations, we observed great results with convolutional networks applied to word embeddings of READMEs and commit messages. On top of this, we used a deep feed-forward neural classifier to combine the predictions of our sub-nets into a final conclusion instead of using a linear classifier.
For training, we used automatically picked repositories chosen by a heuristic. Our classifier shows good performance and could also be applied to other text classification tasks, although it is hindered by our training dataset which only includes a narrow distribution of repositories. Features we consider important
We decided to focus on the following data fields, which can be grouped into numerical, textual and temporal ones:
-
numerical
- number of commits
- number of contributors
- number of forks
- number of issues
- number of pulls
- number of stars
- number of subscribers
-
textual
- README
- commit messages
-
temporal
- times of commits
Especially for the numerical fields, there is no real justification for each of these items yet. For now we take as much information as we can get and hope that our classifiers selects the relevant ones. The other groups are more deliberately chosen...
First of all the README obviously carries very much information. This is one of the first things you would check as a human after you have seen the repo name. We will use a classifier to extract not only keywords, but rather the real semantics using topic modeling. The same holds for the commit messages. We will see, how informative they are.
The idea behind the analysis of commit times was, that there are probably certain time profiles (say within a week), that repeat over the lifetime of the repository. This could be characteristic for each category, think of weekly homework, as opposed to development repos facing far more frequent updates.
We decided to work with Neural Networks. They are very adaptive classifiers which have some biological, cognitive foundation. Also there are many possible architectures for such nets with state-of-the-art applications. To reflect the grouping we did above, we will try out...
- a simple Feed Forward Network (FFN) for the numerical data,
- a Recurrent Neural Network (RNN) for temporal analysis of commit times, and
- a Convolutional Neural Network (CNN) for text analysis.
In this way we employ networks of increasing complexity. Instead of having traditional handcrafted systems, we demonstrate the applicability and variability of Neural Networks for parameters known to be working very well for the respective architectures. Hence, our nets are specialized each in its input group and yield independent, possible different category predictions. To obtain a single prediction for a given repo, we use yet another network,
- an ensemble network that combines the output of the upper ones.
For the implementation we use the Python based Tensorflow Framework for Machine Learning. For a quick introduction, see the excellent Tensorflow Tutorials and of course the respective parts of our code documentation, especially in NumericFFN.py.
Each of the classifiers, the topologies and the training mechanism used is described separately in the following sections. In fact, we tried many different topologies for each architecture and obviously cannot report everything. Also, in the course of development certain nets (e.g. the FFN) proved not to show the expected performance. We decided to focus on adjusting the working ones, but nevertheless not to drop the others, but rather having them contribute a few percentages to the final accuracy.
We started off by writing a python script (rate_url.py) to interactively classify URLs, which we manually browsed for using Google in order to get representative amounts of samples for each class, e.g. by searching for 'GitHub physics homework' explicitly. Soon we noticed that this is no satisfactory method to get large amounts of training data, so we automated the procedure.
We used GHTorrent to dump a CSV database of all (!) GitHub repositories i.e. 39.7 million, as of January 2017. This CSV contains all the metadata of every activity on GitHub, including of course the repository names. However, we ignore the metadata here, and download only the relevant data later via the API (see below).
Also we had to clean the repository list from forks that have the same READMEs and contents, in order to not over-represent vastly forked repositories.
To filter for informative samples for each category we look only at the repository names. Upon this we run a parsing script repo_search.py looking for keywords in their names:
| No. | Category | Keywords | # Repos |
|---|---|---|---|
| 1 | DEV | app, api, lib | 1368 |
| 2 | HW | homework, exercise | 5091 |
| 3 | EDU | lecture, teaching | 1458 |
| 4 | DOCS | docs | 836 |
| 5 | WEB | website, homepage | 4513 |
| 6 | DATA | dataset, sample | 1132 |
| 7 | OTHER | none | ------- |
| Sum | 14398 |
Note that the OTHER category does not need to be learned but rather serves as an uncertainty indicator for our later classifier. Thus we obtained JSON files 'dev.json', ..., 'data.json' containing repository URLs of the same class respectively.
The next step was to download relevant data fields for each repository to learn upon. Our choice of features we want to train is described the next section.
To query GitHub repositories we primarily use GraphQL because of its efficient access to many fields at a time. However, because this has severe rate restrictions and it does not provide READMEs we also use a Python wrapper for the GitHub API: github3. This allows us to dump READMEs and all the data fields we specified above.
With the downloaded data we extend our JSON files from above. Thus we yield the following training sample format:
[
{
"Category":"1",
"URL":"https://github.com/briantemple/homeworkr",
"Commits":"...",
"NumberOfCommits":"...",
"...":"..."
},
{...}, ...
]
Note further that we will NOT train on the repository names later, otherwise we would of course overfit with respect to this information.
We split the data for each category into a 90% training set and a 10% test set. The former is used for training obviously and the latter for later validation (see the results). Feed Forward Neural Networks (FFNs) are simple networks of 'neurons' that take an input, propagate it through some hidden layers and give you an output for each individual class you specify. In a way, this structure resembles neurons in the brain, connected by one-way synapses.

The topology we use for this is the following:
| input | hidden #1 | hidden #2 | hidden #3 | output |
|---|---|---|---|---|
| 7 | 150 | 50 | 50 | 6 |
What are these neurons, what functions do they perform? Well, in our case they are so-called Rectified Linear Units (ReLUs). They get the weighted sum of the output of their predecessor neurons as their input.
[x_j = \sum_{k=1}^K w_{i,j} y_i]
On this input (x) they apply the following activation function:
[y_j = \mathrm{max}(0, x_j)]
There are other activation functions which are non-linear but sigmoid like (\mathrm{tanh}) but this kind of functions lead to the problem of so-called vanishing gradients and hence ReLUs are better suited to our needs.
The last layer, i.e. the output layer of the net, has a special task: It should give us something like a confidence for each class, e.g. 35% for DEV. One could also take only the max of the outputs (and say the most active category yields output one and the others zero) but it is easier to train the network with a derivable function. And this is why you use softmax as the activation function in the last layer:
[y_j = \frac{e^{x_j}}{\sum_{k=1}^K e^{x_k}}]
What it does is normalizing the inputs so that the outputs sum up to one and we get nice percentages. Convolutional neural networks are actually known to be very successful visual classifiers. However, they can also be applied in Computational Linguistics for semantic analysis of text. In our case, we want to learn the the topic of a Repository by 'reading' its README.
If you want to perform object recognition in visual images, probably you want to be invariant with respect to the size, orientation and the location of the object within the image. Also it makes (biologically) sense to start from recognized edges and abstract (compose) to shapes and objects.
All these are characteristic functions of CNNs and are achieved by so-called convolutions and pooling. A convolution is basically a filter (aka. kernel) sliding over a whole image, like in the following nice simulation [1]:

By applying this with several filters you obtain multiple Convolutional Layers extracting different features of the image. Further location invariance is added by Pooling where some feature information is thrown away again. For example take max-pooling: there you just take maximum of your neighbors at each pixel [2].
{kind=link}

While these concepts are very vivid in the case of images, they are not yet for language, let us see...
Linguists don't work with images but with corpora, i.e. huge amounts of real world text. Why not think of words as vectors (coordinate lists) within the n-dimensional corpus space? Note that the space would be a discrete one, it contains only its words but nothing 'in between'. However, what we want is a continuous vector space of words. Also, we want it to have substantially less dimensions (note that n is the size of a typical big data corpus). We want real-valued vectors, something like:

This reduction of dimensionality can be achieved using modern variants of the classical bag-of-words model called word embeddings. What is done is basically a packing of co-occurring words in the same 'bag'. The so obtained vectors show very cool (vector-space) behavior:
king - man + woman ~ queen
dog + big + dangerous ~ bulldog
Here is another fancy picture (produced by tSNE) showing the vector space [3]:
{kind=link}

But, lo and behold, there are pretrained datasets around that offer exactly this! The one we are using is generated by Google using its famous word2vec algorithm. It is trained on the whole Google News corpus (n=100 billion) and is available here. The model contains 300-dimensional vectors for 3 million words and phrases. This means, if you do a lookup for a word in the dataset you will get a list of 300 real numbers indicating the position of the word within the vector space.
For further theoretical explanation see the original paper by Google's group around Thomas Mikolov. You may also want to check this Blog post on GloVe, a similiar vector database (which we chose first, but failed to download).
We work with the first 300 words of the README and the first 400 words of the commits (concatenated from multiple commits). If either of both texts is not long enough, we fill the vector with padding words (\pad\).
Now, if we want to apply this to extract (hopefully) the topic of the repository, we need to be aware of two things:
First, the repo might not have a README at all (or, say it is empty). In this case classification seems to be futile, but nevertheless it tells us something. We observed for example that homework repos often lack a README (for obvious reasons). Solution: we provide an empty vector (filled with 300 pads) as a dummy for classification.
Second, texts are cluttered by punctuation signs and other 'text mess'. After we applied the word tokenizer to the texts, these are still sticking at the words. However, there are word-vectors for those signs so we do not need/want to extract them entirely. Solution: parse and split those signs from the words (see classification.Data.clean_str)
Now for the actual neural net. We construct a Convolutional Neural Network of a single convolutional and following pooling layer. Its topology looks like this [4]:

The size of the input matrix is 300 words of the mentioned vector dimensionality 300.
For the convolutional layer, we use one-dimensional filters over multiple words with sizes of k out of [3, 4, 5]. For each filter we have 164 instances of initially random weights which are learned in the training. The strides with which the filters are sliding equal 1 for all filter sizes, hence they are of course overlapping. After we applied these convolutions one layer of max pooling follows.
Then we have all the features extracted and can learn on those. This is done by the last fully connected layer with 100 hidden units.
The CNN for Commit messages looks basically the same with the only difference that the input size is 400 words and we use 200 filters.
So far we were concerned with networks that get inputs of a fixed size. But sometimes we just don't know their size, mostly in cases of (temporal) sequences. That's what Recurrent Neural Networks (RNNs) are best suited for, data that exhibits patterns over time. They find applications in recognition of (handwritten) text and speech, or at the stock market. For this they have a special ability, they 'save' previous input. As the name suggests, they have recurrent 'synapses', i.e. edges going back in circles to the same cell. Here is how it looks if you unfold this circle three times [1]:

However, the trouble with most types of RNNs is that they are essentially unable to remember things in long term, e.g. words that occurred sentences ago. This is due to the vanishing gradients problem and was first formerly proven by Hochreiter in 1991. In 1997 appeared an often-cited followup paper, also by Hochreiter and Schmidhuber, introducing the Long Short-Term Memory (LSTM) that is designed to tackle this shortcoming.
Its nodes do no longer look like simple neurons, but rather like complex memory cells, here again unfolded [2]:

Each cell gets its memory (C) from its earlier state, shown by the continuous horizontal line at the top. Further, this state can be influenced by new inputs (x) which can be whole vectors. But they are weighted by certain gates, depicted by (\sigma) or (\tanh). Internally these gates consist of a layer of neurons with sigmoid activation functions that squash the input values in ranges of [0, 1] or [-1, 1] respectively. The following list explains what is going on in the cell from left to right:
-
The first filtering is done by the so-called forget gate on the very left. It decides how much information from the old state is being kept with respect to the current input.
-
Secondly, we want to integrate the new input at the input gate. To do so, first we decide which values are to be updated ((\sigma) branch) while at the same time creating new candidate values ((\tanh) branch) and later combine both branches by pointwise vector multiplication to finally update the state.
-
At last, we have to filter the current state to produce an output (h). Again we apply a layer of (\tanh) to normalize the state and (\sigma) to select the relevant output with respect to the current input.
In fact, this is only the main principle of how LSTMs are designed but in practice there are variable implementations. For example, we use a version called Bidirectional LSTM (BLSTM), which takes into account not only states from previous inputs but also looks ahead and considers 'future' input. This of course is possible because we have the whole sequence of commits given (no real-time analysis) which we can feed into the net from both directions, once forwards once backwards. The BLST actually consists of two separate LSTMS, one for each direction. These LSTM cells are independent from each other, they do not communicate, but only their outputs are concatenated.
From our Training Data Mining we have given a list of commit timestamps within the whole lifetime of each repo. The objective was to create a time profile for a period of a week or a month to see how commits are distributed, maybe even detect class-specific peaks. The function for the preprocessing basically does a binning of our list, it can be found here: networks.Data.commit_time_profile. It yields histograms like these, here for the classes DEV and HW:

Unfortunately, as one might suspect from the graphs, there does not really seem to be that much information in the commit times with regard to the categories. Also there are many sparse profiles of repos with very few commits.
In fact, we realized after training that the net did not perform particularly well and decided to drop the LSTM from our later classifier, it will not occur in the results. After training of all the networks we needed to make a decision: Which networks are worthy to be integrated in the final classifier regarding accuracy but also regarding the amount of computation time.
We choose only the following two networks:
- the CNN for README
- and the CNN for the Commit times.
These give us their predictions and we feed them into our master net, the Ensemble Network.
This is an easy two-layer feed forward topology for learning non-linear weightings of the CNN predictions. For example it should learn to rely only on the Commits if the README is empty. Training of a network means basically adjusting its weights in order to fit it to the function of the inputs to the desired outputs. This way the model learns to predict the classes even for repositories it has never seen before. The only thing we have to do is show the network our sample inputs, let it do its prediction (which is random at the beginning of training) and give it a feedback. This is called Supervised Learning.
This section describes the training of each network which is basically the same procedure for all.
The first thing one has to do to prepare a net for training is to initialize the weights. You could either say, they will be trained anyhow, so let's just set assign them to a constant value ((\neq 0), because 0-weights would propagate nothing). But the problem with this is that the back-propagated error will be the same for each weight which makes the model unable to learn.
So what you definitely do is, you take initial weights from a random distribution like a Gaussian (bell curve) or a uniform distribution. In this case you have to specify the range, i.e. a min and a max weight, and commonly you center the distribution at 0, so you have negative weights, too.
Even better is to choose the range for initialization with respect to the size of the layers ((in) and (out))the weight is between. As Xavier et. al. suggested in 2010, one should rather use a range of ([-x, x]) with (x = \sqrt{6/(in, out)}) for uniform distributions or a standard deviation of (\sqrt{3/(in, out)}) for Gaussian. That's how we do it.
After initializing the weights, the network is able to propagate its input towards the output layer. It gets one input of our dataset at a time, one after the other. When the whole samples are seen once, we call this an epoch. However, for convergence to the global minimum the net will need many of these epochs. How many, is really a matter of choice, if you are satisfied with the result you can stop training. Of course you should stop earlier if you see that it does not make any learning progress any more, whatever the reason.
During the training we need to provide the feedback. There are different timepoints when you can do this: Either you do it after each sample (Stochastic/online learning) or you accumulate the error for all samples and only update the weights after an epoch is finished. In the first case, the learning will fluctuate very much, in the latter it will be inflexible in terms of reacting differently to different inputs. A good compromise is to use so-called (mini) batches that consist of a subset of samples, say e.g. a 10th of the whole dataset. Giving the feedback after each batch makes learning much more stable and efficient. Again, the size of the batches is a value that is individual for each classification and comes from experience. We use batch sizes of 200-300 samples.
Another preparation concerns the order of the training samples. They should be learned in a way that each sample is independent from its predecessors, i.e. consequent samples should not be of the same category. Otherwise the network would specialize into one category too much and does not generalize so easily. This can be prevented by shuffling the data before training.
As stated above, Supervised Learning is based on giving the network a feedback. This feedback is proportional to the error it makes for each sample (x \in X), so we need to define an error function, aka. a Loss function. It is supposed to measure the 'distance' between the generated output (\hat{y}) and (y \in Y), the actual output, in our case the real category of repo (x). Let's assume there are (N) training samples in the following. There are different measurements in use, for example the root mean square error (RSME) defined for numeric classes as follows: [RMSE(Y, \hat{Y}) = \sqrt{\frac{1}{N} \sum_{i=1}^N (y_i - \hat{y}_i)^2}]
The one we are using is a bit different because it does not make too much sense to subtract class labels (even if we encoded them numerically). Instead we use the so-called Cross-entropy loss defined like this: [CEL(Y, \hat{Y}) = \frac{1}{N} \sum_{i=1}^N H(y_i, \hat{y}_i)]
where (H) is the cross entropy which one can think of as the probability for a sample of being in class (\hat{Y}) while actually being in class (Y) (here for one-hot encoded outputs): [H(Y, \hat{Y}) = - \sum_{y \in Y} y \log \hat{y}]
Now that we have an loss function, we want to minimize the error, i.e. we want to find a (hopefully) global minimum on its surface [1]:
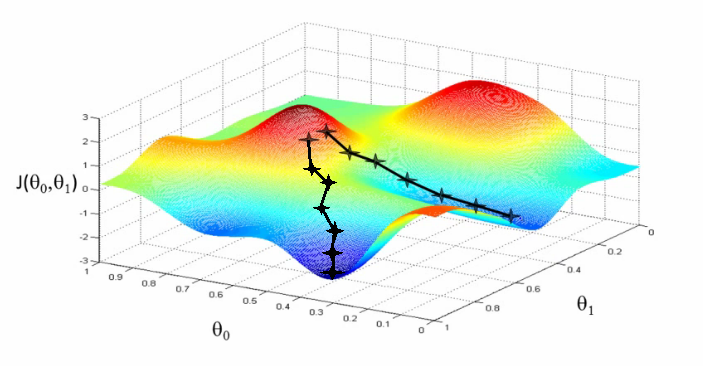{kind=link}

This is done by adjusting the weights (in the image there are only two, depicted as (\theta_i)) in a way that leads us to the valleys of the function. This in turn can be achieved by calculating the gradient of the loss function, i.e. the derivative with respect to each weight. Intuitively, one can think of the gradient as a vector pointing to the steepest direction of the error surface. Because we want to 'go down the hill', we take the negative derivative: [w_{new} = w - \eta \cdot \frac{\partial CEL}{\partial w}]
(\eta) is a proportional factor called the learning rate, a value that we can think of as constant for now.
We do this update for all the weights starting at the last weight layer. The layers before are a little bit more complex to update, but there is an algorithm for that: Backpropagation of Error or just BP. As the name suggests, the updates are performed from the output layer backwards, again by differentiating. This involves repeated use of the chain-rule over all the activation functions until one arrives at the desired weight. Suppose, we have the following chain of neurons (i), (j) and (k) in the net...

In this situation, you would calculate the update (\Delta w_{i,j}) by: [\Delta w_{i,j} = \frac{\partial CEL}{\partial \sigma(k)} \cdot \frac{\partial \sigma(k)}{\partial relu(j)} \cdot \frac{\partial relu(j)}{\partial relu(i)} \cdot \frac{\partial relu(i)}{\partial w_{i,j}}]
Luckily this is done by the Tensorflow framework for us ;)
The real difficulty with gradient descent approaches is to find a good global minimum. This does depend on your choice of the learning rate. If you choose it too small, gradients will be weighted very low. That means, if you are on a flat place you will get stuck eventually. On the other hand, if (\eta) is too high, you would do big jumps on the error surface and may end up jumping back and forth over a valley. The best of the two worlds is to make (\eta) dependent on the training cycle, i.e. decrease it over time. This resembles the way humans would learn, namely beginning in big steps and later doing the fine tuning. In our implementation we use a starting (\eta_0) of 0.001 and an exponential decay factor of 0.999.
Another way of optimizing gradient descent is to consider gradients from earlier training cycles. This is useful if you have sparse data and some of the inputs are very rare. Then you might want to perform a bigger update for infrequently used weights. An algorithm can do this by storing the average of the last updates per weight.
Both is done by the ADAM (Adaptive Moment Estimation) optimizer. For more information see original paper.
Another method for tweaking gradients is so-called gradient clipping. It is a rather rigorous approach that cuts of gradients, that exceed an upper limit (in our case a value of 5.0). It has the purpose to prevent exploding gradients.
Also we define a dropout-probability, that is a probability allowing the network to ignore a neuron during training. The problem with large nets is that they tend to overfit and, in fact, only train parts of its structure. A dropout forces the net to use all neurons in order to maintain plasticity. We choose dropout-to-keep a ratio of 0.5.
Last but not least, we use so-called L2 regularization. This is another way to prevent over-fitting and urging the network to have small weights. It uses the mean squared error of all current weights and subs tracts it from each weight as a penalty, independently from the loss function. Recap of the training
The accuracy is defined as the ratio of rightly predicted categories to all the samples. During the training we plotted the current accuracy with respect to the training data to see when the network stops to make progress with learning.
According to this we could decide, which networks to drop from our final classifier. These are the FFN which performed very low (accuracy of ~30%) and the LSTM which stoped at roughly ~50%.
For illustration here are the training plots. One can see how fast the CNNs converge. The upper graph is for the README and the one below for the commit CNN:

After training, of course we have to validate the networks against the test data, the 10% of our data that the net has never seen before.
Here we list the performance of all the networks on our own test data (not "Anhang B"!):
| Network | Performance |
|---|---|
| CNN (README) | 83% |
| CNN (Commit) | 60% |
| Ensemble | 90% |
For further data, please have a look at our Tensorboard documentation.
| Value | Amount |
|---|---|
| Total | 31 |
| Correct | 24 |
| Wrong | 7 |
| Yield | 77.4% |
| Category | RIGHT | TOTAL |
|---|---|---|
| HW | 2 | 5 |
| DEV | 5 | 8 |
| EDU | 5 | 5 |
| WEB | 4 | 4 |
| DATA | 3 | 3 |
| DOCS | 3 | 6 |
| OTHER | 1 | 1 |
| Resume of our 3 approaches |
The word2vec approach we applied to the Commits and the Readme proved to be highly satisfactory. This is what we expected because the texts carry really a lot of information.
We are not surprised by the bad performance of the FFN as we did no data preprocessing and it is in general difficult to learn on such variable numeric values.
On the other hand we realize that we expected too much from the commit time data. Therefore it is no wonder that the LSTM performs badly.
The approach of picking GitHub repos by searching for keywords only yields really clear categorizable data. We have caught few false positives with that. On the other hand we do not cover cases at the border between two classes that well.
And of course, with more data the classification would improve. For example repos of category DOCS were underrepresented in our training set. Also it would be a good idea to consider issues with our textual approach. However, we experienced shortcomings in the data retrieval with the GitHub API. Using a multi-threaded approach running on multiple computers took us (including debugging of our crawling algorithm) almost a week.
We clearly focus on the textual parts of the repo.
A problem of this is that by only considering semantic information we fail to see for data formats sometimes, for example we struggle to classify the websites that are about EDU-, HW- or other content.
While this can be a pitfall, in general the strength of our classificator is its focus on the semantics of the texts. For example repos that look like WEB but are actually hidden APIs are more likely to be rightly classified as DOCS by our classifier.
Here are three URLs on which our approach semantic approach should also perform well.
- https://github.com/MSchuwalow/StudDP
- https://github.com/fabrichter/compling
- https://github.com/petroav/6.828
The 1. is a DEV but contains many references to courses. Anyway the net is very sure that this it is DEV. No. 2 is correctly classified as a HW repo although there is no README. The last repo is a special HW, because it is very often forked and starred. List of Referenced Papers
-
Kingma, D. P., & Ba, J. L. (2015). Adam: a Method for Stochastic Optimization. International Conference on Learning Representations, 1–13.
-
Xavier Glorot and Yoshua Bengio (2010): Understanding the difficulty of training deep feedforward neural networks. International conference on artificial intelligence and statistics.