[TEST] Fix test cache #1588
Merged
[TEST] Fix test cache #1588
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
ptillet
approved these changes
Apr 28, 2023
jayfurmanek
added a commit
to ROCm/triton
that referenced
this pull request
May 22, 2023
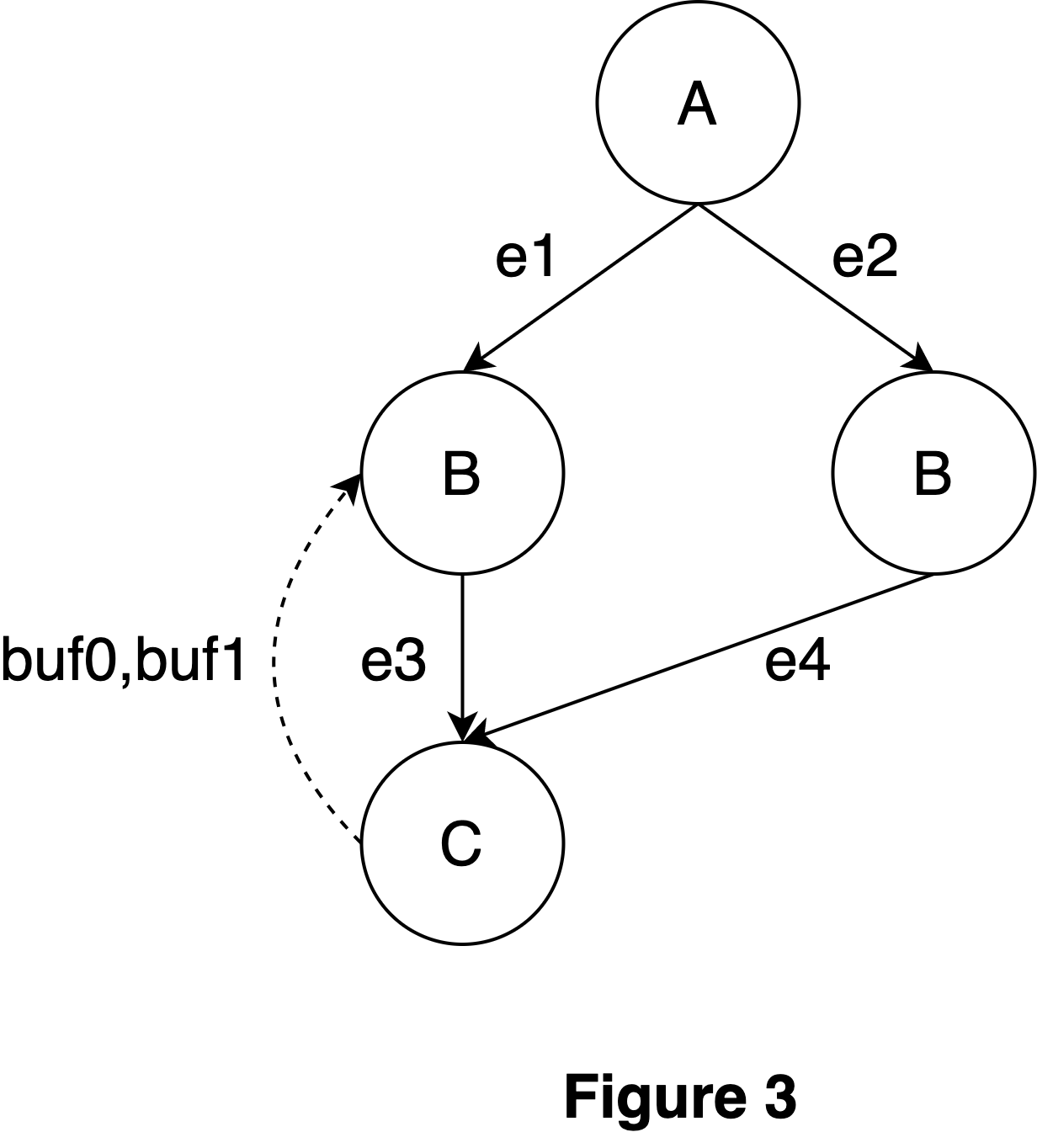
* [OPTIMIZER] simplified pipeline pass (triton-lang#1582) directly rematerialize for loop with the right values, instead of replacing unpipelined load uses a posteriori * [OPTIMIZER] Added kWidth attribute to DotOperandEncoding (triton-lang#1584) This is a pre-requisist for efficient mixed-precision matmul * [TEST] Fix test cache (triton-lang#1588) To avoid puzzling segment fault problems caused by multiprocessing, this PR: - Uses "spawn" instead of "fork". - Define the `instance_descriptor` namedtuple globally. - Make the `kernel_sub` JITFunction defined by the child process only. * [BACKEND] Updated slice layout semantics, updated vectorization logic used for load/store ops. (triton-lang#1587) * [FRONTEND][BACKEND] Add the `noinline` annotation for `triton.jit` (triton-lang#1568) # Introducing the `noinline` Parameter for Triton JIT Decorator We're excited to introduce a new parameter, `noinline`, that can be added to the `jit` decorator in Triton. This parameter allows developers to specify that a particular Triton function should not be inlined into its callers. In this post, we'll dive into the syntax, purpose, and implementation details of this new feature. ## Syntax To use the `noinline` parameter, simply add `noinline=True` to the `jit` decorator for the function that you don't want to be inlined. Here's an example: ```python @triton.jit(noinline=True) def device_fn(x, y, Z): z = x + y tl.store(Z, z) def test_noinline(): @triton.jit def kernel(X, Y, Z): x = tl.load(X) y = tl.load(Y) device_fn(x, y, Z) ``` In this example, the `device_fn` function is decorated with `@triton.jit(noinline=True)`, indicating that it should not be inlined into its caller, `kernel`. ## Purpose The `noinline` parameter serves several key purposes: - Reducing code size: By preventing inlining, we can reduce the size of the compiled code. - Facilitating debugging: Keeping functions separate can make it easier to debug the code. - Avoiding common subexpression elimination (CSE) in certain cases: CSE can sometimes be avoided by using the `noinline` parameter to reduce register pressure. - Enabling dynamic linking: This parameter makes it possible to dynamically link Triton functions. ## Implementation The implementation of the `noinline` parameter involves significant changes to three analysis modules in Triton: *Allocation*, *Membar*, and *AxisInfo*. Prior to this update, these modules assumed that all Triton functions had been inlined into the root kernel function. With the introduction of non-inlined functions, we've had to rework these assumptions and make corresponding changes to the analyses. ### Call Graph and Limitations <div style="text-align: center;"> <img src="https://user-images.githubusercontent.com/2306281/234663904-12864247-3412-4405-987b-6991cdf053bb.png" alt="figure 1" width="200" height="auto"> </div> To address the changes, we build a call graph and perform all the analyses on the call graph instead of a single function. The call graph is constructed by traversing the call edges and storing them in an edge map. Roots are extracted by checking nodes with no incoming edges. The call graph has certain limitations: - It does not support recursive function calls, although this could be implemented in the future. - It does not support dynamic function calls, where the function name is unknown at compilation time. ### Allocation <div style="text-align: center;"> <img src="https://user-images.githubusercontent.com/2306281/234665110-bf6a2660-06fb-4648-85dc-16429439e72d.png" alt="figure 2" width="400" height="auto"> </div> In Triton, shared memory allocation is achieved through two operations: `triton_gpu.convert_layout` and `triton_gpu.alloc_tensor`. The `convert_layout` operation allocates an internal tensor, which we refer to as a *scratch* buffer, while the `alloc_tensor` operation returns an allocated tensor and is thus known as an *explicit* buffer. To accommodate the introduction of function calls, we are introducing a third type of buffer called a *virtual* buffer. Similar to scratch buffers, virtual buffers are allocated internally within the scope of a function call, and the buffers allocated by the called functions remain invisible to subsequent operations in the calling function. However, virtual buffers are distinct from scratch buffers in that the call operation itself does not allocate memory—instead, it specifies the total amount of memory required by all the child functions being called. The actual allocation of buffers is performed by individual operations within these child functions. For example, when invoking edge e1, no memory is allocated, but the total amount of memory needed by function B is reserved. Notably, the amount of shared memory used by function B remains fixed across its call sites due to the consideration of dynamic control flows within each function. An additional challenge to address is the calculation of shared memory offsets for functions within a call graph. While we can assume a shared memory offset starting at 0 for a single root function, this is not the case with a call graph, where we must determine each function's starting offset based on the call path. Although each function has a fixed memory consumption, the starting offset may vary. For instance, in Figure 2, the starting offset of function C through edges e1->e2 differs from that through edges e2->e4. To handle this, we accumulate the starting offset at each call site and pass it as an argument to the called function. Additionally, we amend both the function declaration and call sites by appending an offset variable. ### Membar <div style="text-align: center;"> <img src="https://user-images.githubusercontent.com/2306281/234665157-844dd66f-5028-4ef3-bca2-4ca74b8f969d.png" alt="figure 3" width="300" height="auto"> </div> The membar pass is dependent on the allocation analysis. Once the offset and size of each buffer are known, we conduct a post-order traversal of the call graph and analyze each function on an individual basis. Unlike previous analyses, we now return buffers that remain unsynchronized at the end of functions, allowing the calling function to perform synchronization in cases of overlap. ### AxisInfo <div style="text-align: center;"> <img src="https://user-images.githubusercontent.com/2306281/234665183-790a11ac-0ba1-47e1-98b1-e356220405a3.png" alt="figure 4" width="400" height="auto"> </div> The AxisInfo analysis operates differently from both membar and allocation, as it traverses the call graph in topological order. This is necessary because function arguments may contain axis information that will be utilized by callee functions. As we do not implement optimizations like function cloning, each function has a single code base, and the axis information for an argument is determined as a conservative result of all axis information passed by the calling functions. --------- Co-authored-by: Philippe Tillet <phil@openai.com> * [FRONTEND] add architecture to hash to avoid invalid image on cubin load (triton-lang#1593) Closes triton-lang#1556 triton-lang#1512 The current hash used for caching the cubin does not include the architecture. This leads to the following error when compiling against one arch and running against another (with no code changes to trigger a recompilation). ``` RuntimeError: Triton Error [CUDA]: device kernel image is invalid ``` Was not sure what unit tests would be appropriate here (if any) Co-authored-by: davidma <davidma@speechmatics.com> * [FRONTEND] Fix calling local variables’ attribute functions in the if statement (triton-lang#1597) If `node.func` is an `ast.Attribute`, it won't cause an early return. (Not sure if I interpret it correctly) triton-lang#1591 * [OPTIMIZER][BACKEND] Enabled elementwise ops (including casts) between ldmatrix and mma.sync (triton-lang#1595) * [RUNTIME] Ensure we hold the GIL before calling into CPython API in cubin binding (triton-lang#1583) Formatting of the diff is not the best. I only indented the whole function, moved the creation of the py::bytes and the return out of the scope and declared and assigned the cubin variable appropriately. Everything else is unchanged. Today it triggers the following error on CPython debug build: ``` Fatal Python error: _PyMem_DebugMalloc: Python memory allocator called without holding the GIL Python runtime state: initialized ``` --------- Co-authored-by: Keren Zhou <kerenzhou@openai.com> Co-authored-by: Philippe Tillet <phil@openai.com> * Merge branch `llvm-head` (triton-lang#1600) * Zahi/slice reduce rebased (triton-lang#1594) [BACKEND] Enable slice layout support for reduce op * [OPTIMIZER] Fix crash in loop pipelining. (triton-lang#1602) Fixes issue triton-lang#1601. * [FRONTEND] make torch optional (triton-lang#1604) make torch optional to fix circular dependency issue * [OPTIMIZER] Clean-up Utility.cpp and fixed bug in RematerializeForward (triton-lang#1608) ConvertLayoutOp can be folded in other ConvertLayoutOp * [BACKEND] Fixed up ConvertLayout for slices (triton-lang#1616) * [FRONTEND] Add `tl.expand_dims` (triton-lang#1614) This exposes `semantic.expand_dims` in the public API and builds upon it with support for expanding multiple dimensions at once. e.g. ```python tl.expand_dims(tl.arange(0, N), (0, -1)) # shape = [1, N, 1] ``` Compared to indexing with `None`, this API is useful because the dimensions can be constexpr values rather than hard-coded into the source. As a basic example ```python @triton.jit def max_keepdim(value, dim): res = tl.max(value, dim) return tl.expand_dims(res, dim) ``` * [BACKEND] Modified store op thread masking (triton-lang#1605) * [CI] no longer runs CI job on macos-10.15 (triton-lang#1624) * [BACKEND] Allow noinline functions to return multiple values of primitive types (triton-lang#1623) Fix triton-lang#1621 * [BACKEND] Updated predicate for atomic ops (triton-lang#1619) * [TEST] Added convert layout test from/to sliced blocked/mma (triton-lang#1620) * [BACKEND] fix typo in Membar class about WAR description and refine some code (triton-lang#1629) Co-authored-by: Philippe Tillet <phil@openai.com> * [SETUP] Removing `torch` as a test dependency (triton-lang#1632) circular dependency is causing troubles now that our interpreter depends on torch 2.0 ... * [DOCS] Fix docstrings for sphinx docs (triton-lang#1635) * [FRONTEND] Added interpreter mode (triton-lang#1573) Simple mechanism to run Triton kernels on PyTorch for debugging purpose (upstream from Kernl). Todo: - random grid iteration - support of atomic ops - more unit tests - cover new APIs? * [CI] Build wheels for musllinux (triton-lang#1638) Ideally you would also build source distributions so that it is in principle possible to build `triton` on other platforms, but building `musllinux` wheels would at least help with openai/whisper#1328. I suspect you will also get people showing up at some point asking for `aarch64` wheels as well. It might be worth taking a look at the [`cibuildwheel` output matrix](https://cibuildwheel.readthedocs.io/en/stable/#what-does-it-do) to see what you are comfortable with shipping (particularly if you aren't shipping source distributions). * [FRONTEND] Fix return op related control flow issues (triton-lang#1637) - Case 1: Return after static control flow is taken. Peel off instructions after the first `return` for each basic block. ```python if static_condition: tl.store(...) return return ``` - Case 2: Return exists in both `if` and `else` branches of an inlined `JITFunction` function ```python def foo(): if dynamic_condition: return a else: return b ``` - Case 3: Return exists in a `JITFunction` from another module ```python import module if cond: a = module.func() ``` - Case 4: A chain of calls through undefined local variables ```python import module if cond: a = x a = a.to(tl.int32).to(tl.int32) ``` - Case 5: Call a function `func` without returning variables. `func` is recognized as an `Expr` first instead of a `Call`. ```python if cond: foo() else: bar() ``` - Case 6: Call a `noinline` function. We don't need to check if the function contains any return op. * [CI] Upload CUDA test artifacts (triton-lang#1645) * [FRONTEND] Add support for scalar conditions in `device_assert` (triton-lang#1641) This sometimes happens in TorchInductor. See pytorch/pytorch#100880. More generally, it's useful to be able to write `tl.device_assert(False, msg)`. Co-authored-by: Keren Zhou <kerenzhou@openai.com> * [FRONTEND] Hotfix for `contains_return_op` (triton-lang#1651) `noinline` can be None, False, or True, so we have to check the callee in the first two cases. * [TEST] Fixed and re-enabled reduce test (triton-lang#1644) Re-enabled reduce test after fixing the %cst stride in the ttgir, and modifying the sweep parameters to make sure the shape per CTA to be less than or equal to the tensor shape. * [FRONTEND] Don't call set_device in tl.dot (triton-lang#1646) This breaks multiprocess compilation * [TESTS] Add regression test for issue triton-lang#1601. (triton-lang#1611) Following up on triton-lang#1603, I am adding a new file meant to contain functional regression tests to the repository. Let me know if another folder would be a more appropriate place for these tests. Co-authored-by: Philippe Tillet <phil@openai.com> * [BUILD] Move canonicalization patterns of Load/Store to Ops.cpp. (NFC) (triton-lang#1650) This breaks a cyclic dependency between the TritonAnalysis and the TritonIR libraries (see triton-lang#1649). It also follows the convention from upstream (for example, see the AMDGPU, Affine, and Arith dialects). * [FRONTEND] Better error messages for noinline functions (triton-lang#1657) ``` at 10:18:def val_multiplier_noinline(val, i): return val * i ^ Function val_multiplier_noinline is marked noinline, but was called with non-scalar argument val:fp32[constexpr[128]] ``` * [BUILD] Add missing CMake link-time dependencies. (triton-lang#1654) * [BACKEND] Move isSharedEncoding to TritonGPUIR. (triton-lang#1655) This breaks a cyclic dependency between TritonAnalysis and TritonGPUIR (see triton-lang#1649). * [FRONTEND] Do not use exceptions do guide control flow in compilation runtime (triton-lang#1663) Triton runtime currently relies on KeyError to check whether a kernel has been compiled. This results in somewhat confusing backtraces when running the kernel crashes, as the stack traces includes not only the actual crash, but also the stack trace for the original KeyError which was caught. * [FRONTEND] Assert that for loop bounds must be ints (triton-lang#1664) * [OPTIMIZER] Fix-up reduction cloning * [DEPENDENCIES] Update LLVM to 17.0.0 (c5dede880d17) and port changes. (triton-lang#1668) This depends on a [pending LLVM release](ptillet/triton-llvm-releases#10). * Implement setCalleeFromCallable in CallOp. * Cast type to ShapedType for various getters. * Improve TritonDialect::materializeConstant due to breaking change in constructor of arith::ConstantOp. * Add OpaqueProperties argument in inferReturnTypes. Co-authored-by: Philippe Tillet <phil@openai.com> * [OPTIMIZER] adjusted selection heuristics for when `mmaLayout.warpsPerTile[1] = 1` (triton-lang#1675) this fixes fused attention with D_HEAD=128 * [BUILD] stop depending on dlfcn-win32 by implementing `dladdr` natively with WIN32 API (triton-lang#1674) Co-authored-by: Philippe Tillet <phil@openai.com> * [BUILD] minor fixes (triton-lang#1676) Remove unused variables, fix member initializer list order. * [FRONTEND] Differentiate between bool and int in the frontend (triton-lang#1678) `bool` is a subclass of `int`, so `isinstance(bool_var, int) == True`, and a `bool` constant will be converted to an `int` constant. In triton specifically, if a bool var is treated as an integer, it prevents us using the `logical_and` operator which requires both operands have the same bit length. > Cannot bitcast data-type of size 32 to data-type of size 1 By differentiating int and bool, it allows us to make the syntax more close to native python. We can now use `if bool_var and condition` to check the truthiness, and `if bool_var is True` to check identity. * [BUILD] Add deduction guide for `Interval` (triton-lang#1680) This avoids `ctad-maybe-unsupported` warning. * [OPS] Remove duplicated function already defined in `triton` module. (triton-lang#1679) * IFU 230517 Resolve merge conflicts * Fix is_hip() check * [ROCM] Fix hardcoded warpsize in getMask --------- Co-authored-by: Philippe Tillet <phil@openai.com> Co-authored-by: Keren Zhou <kerenzhou@openai.com> Co-authored-by: Zahi Moudallal <128723247+zahimoud@users.noreply.github.com> Co-authored-by: David MacLeod <macleod.david@live.co.uk> Co-authored-by: davidma <davidma@speechmatics.com> Co-authored-by: albanD <desmaison.alban@gmail.com> Co-authored-by: Christian Sigg <chsigg@users.noreply.github.com> Co-authored-by: Benjamin Chetioui <3920784+bchetioui@users.noreply.github.com> Co-authored-by: Michaël Benesty <pommedeterresautee@users.noreply.github.com> Co-authored-by: peterbell10 <peterbell10@live.co.uk> Co-authored-by: long.chen <lipracer@gmail.com> Co-authored-by: q.yao <streetyao@live.com> Co-authored-by: Paul Ganssle <1377457+pganssle@users.noreply.github.com> Co-authored-by: Mario Lezcano Casado <3291265+lezcano@users.noreply.github.com> Co-authored-by: Natalia Gimelshein <ngimel@fb.com> Co-authored-by: Ingo Müller <github.com@ingomueller.net> Co-authored-by: Ingo Müller <ingomueller@google.com> Co-authored-by: George Karpenkov <cheshire@google.com> Co-authored-by: Sophia Wisdom <sophia.wisdom1999@gmail.com> Co-authored-by: cloudhan <cloudhan@outlook.com> Co-authored-by: Daniil Fukalov <1671137+dfukalov@users.noreply.github.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
pingzhuu
pushed a commit
to siliconflow/triton
that referenced
this pull request
Apr 2, 2024
To avoid puzzling segment fault problems caused by multiprocessing, this PR: - Uses "spawn" instead of "fork". - Define the `instance_descriptor` namedtuple globally. - Make the `kernel_sub` JITFunction defined by the child process only.
ZzEeKkAa
pushed a commit
to ZzEeKkAa/triton
that referenced
this pull request
Aug 5, 2024
The tests cases mentioned in triton-lang#983 have been added to A770 skip list. Fixes triton-lang#1579.
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
To avoid puzzling segment fault problems caused by multiprocessing, this PR:
instance_descriptornamedtuple globally.kernel_subJITFunction defined by the child process only.