Problems with the --multi-scale option with CUDA #7678
Comments
|
@DP1701 your error message clearly states YOLOv5 🚀 can be trained on CPU, single-GPU, or multi-GPU. When training on GPU it is important to keep your batch-size small enough that you do not use all of your GPU memory, otherwise you will see a CUDA Out Of Memory (OOM) Error and your training will crash. You can observe your CUDA memory utilization using either the
CUDA Out of Memory SolutionsIf you encounter a CUDA OOM error, the steps you can take to reduce your memory usage are:
AutoBatchYou can use YOLOv5 AutoBatch (NEW) to find the best batch size for your training by passing
Good luck 🍀 and let us know if you have any other questions! |


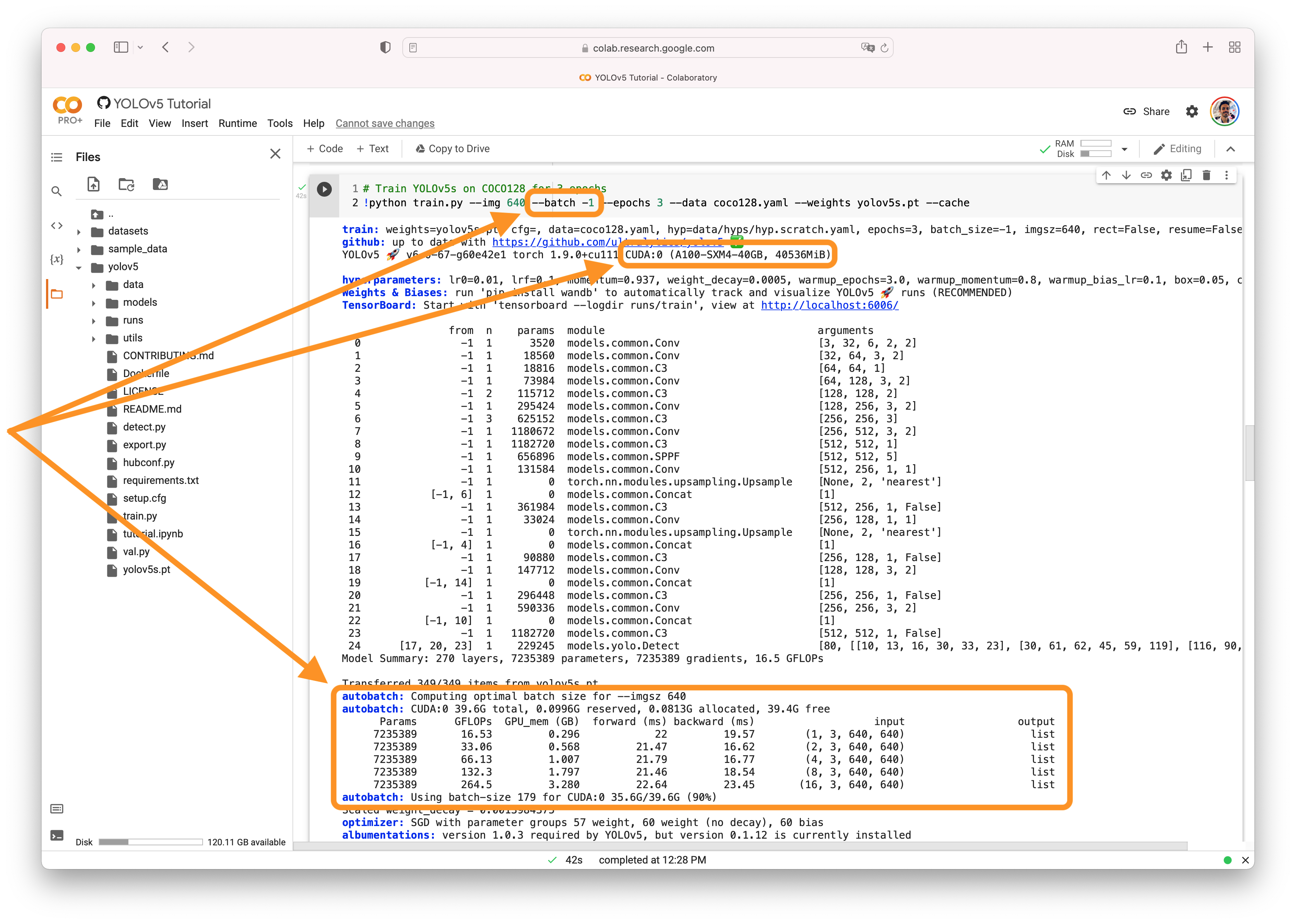
|
@glenn-jocher
With --batch 8 --epochs 10 |

|
@DP1701 👋 hi, thanks for letting us know about this possible problem with YOLOv5 🚀. If batch -1 causes issues then I'd suggest you don't use it. |
|
Hi @DP170, I am running a GPU can you guide me on how you initiated the GPU device, please? I am trying to run my GPU via a Linux server and it's proving extremely challenging! Thanx for acknowledging my digital presence in advance |
|
HI @Symbadian, You don't have to change anything in the code. The following command in the terminal is sufficient: (For mulit-gpu training) python3 -m torch.distributed.launch --nproc_per_node NUMBER_OF_GPUs train.py --data path_to_your_data --img image_size --weights weights --batch batch_size --epochs number_of_epochs --device number_of_devices The information in bold is information to be provided. Important: The stack size must be greater than 0 when using multi-GPU training. It is important that you have installed Pytorch with CUDA support. Otherwise it will not work. |
|
@DP1701 hi pal, I wish that was the case! this is my error with the torch library and I am not sure how to solve this! |
|
@DP1701 I ran this code and it came back with |
|
What packages do you have installed? Try this: Does it work? |
|
@DP1701 hey pal, I manage to install the necessary pytorch |
|
and I ran the next bits (python3 train.py) I got a new error Traceback (most recent call last):
File "/home/MattCCTV/YOLO9Classes/yolov5/train.py", line 42, in <module>
import val as validate # for end-of-epoch mAP
File "/home/MattCCTV/YOLO9Classes/yolov5/val.py", line 37, in <module>
from models.common import DetectMultiBackend
File "/home/MattCCTV/YOLO9Classes/yolov5/models/common.py", line 23, in <module>
from utils.dataloaders import exif_transpose, letterbox
File "/home/MattCCTV/YOLO9Classes/yolov5/utils/dataloaders.py", line 31, in <module>
from utils.augmentations import (Albumentations, augment_hsv, classify_albumentations, classify_transforms, copy_paste,
File "/home/MattCCTV/YOLO9Classes/yolov5/utils/augmentations.py", line 12, in <module>
import torchvision.transforms.functional as TF
ModuleNotFoundError: No module named 'torchvision.transforms.functional'; 'torchvision.transforms' is not a package```
I am now trying to find out what that is and how to solve this...I am not sure this is problematic!!!
In the read-me file, I followed all the instructions line by line...
and still, these errors persist...
|
|
Uninstall torch and torchvision. Then type in: |
|
still pal, |
|
Do you still have torchvision 0.1.8 installed? |
|
Yes I do!! But it’s still giving me and an error..
Cheers to positive perspectives!
Matt.
…________________________________
From: DP1701 ***@***.***>
Sent: Monday, January 16, 2023 11:17:35 AM
To: ultralytics/yolov5 ***@***.***>
Cc: Symbadian ***@***.***>; Mention ***@***.***>
Subject: Re: [ultralytics/yolov5] Problems with the --multi-scale option with CUDA (Issue #7678)
Do you still have torchvision 0.1.8 installed?
—
Reply to this email directly, view it on GitHub<#7678 (comment)>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AL7WSHNQ7OKNP4M7AXKF6R3WSUU47ANCNFSM5U57YXLA>.
You are receiving this because you were mentioned.Message ID: ***@***.***>
|
|
Install this: But uninstall torch and torchvision beforehand. |
|
Ahh I see.. ok will trying that..
Cheers to positive perspectives!
Matt.
…________________________________
From: DP1701 ***@***.***>
Sent: Monday, January 16, 2023 11:54:04 AM
To: ultralytics/yolov5 ***@***.***>
Cc: Symbadian ***@***.***>; Mention ***@***.***>
Subject: Re: [ultralytics/yolov5] Problems with the --multi-scale option with CUDA (Issue #7678)
Install this:
pip install torch==1.12.0+cu116 torchvision==0.13.0+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
But uninstall torch and torchvision beforehand.
Torchvision 0.1.8 is out of date.
—
Reply to this email directly, view it on GitHub<#7678 (comment)>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AL7WSHNGL3SAZP6LXPBVA4DWSUZFZANCNFSM5U57YXLA>.
You are receiving this because you were mentioned.Message ID: ***@***.***>
|
|
pip install torch==1.12.0+cu116 torchvision==0.13.0+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
Looking in indexes: https://pypi.org/simple, https://download.pytorch.org/whl/cu116
ERROR: Could not find a version that satisfies the requirement torch==1.12.0+cu116 (from versions: none)
ERROR: No matching distribution found for torch==1.12.0+cu116
From: mm gp ***@***.***>
Date: Monday, 16 January 2023 at 11:57
To: ultralytics/yolov5 ***@***.***>, ultralytics/yolov5 ***@***.***>
Cc: Mention ***@***.***>
Subject: Re: [ultralytics/yolov5] Problems with the --multi-scale option with CUDA (Issue #7678)
Ahh I see.. ok will trying that..
Cheers to positive perspectives!
Matt.
…________________________________
From: DP1701 ***@***.***>
Sent: Monday, January 16, 2023 11:54:04 AM
To: ultralytics/yolov5 ***@***.***>
Cc: Symbadian ***@***.***>; Mention ***@***.***>
Subject: Re: [ultralytics/yolov5] Problems with the --multi-scale option with CUDA (Issue #7678)
Install this:
pip install torch==1.12.0+cu116 torchvision==0.13.0+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
But uninstall torch and torchvision beforehand.
Torchvision 0.1.8 is out of date.
—
Reply to this email directly, view it on GitHub<#7678 (comment)>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AL7WSHNGL3SAZP6LXPBVA4DWSUZFZANCNFSM5U57YXLA>.
You are receiving this because you were mentioned.Message ID: ***@***.***>
|
|
@DP1701 got this error: |
|
Here are all the version: You have to check which system, which python version, which Cuda version you have installed. You could also try just: Python >=3.7, <=3.10 is required |
|
@DP1701 Yip, went through those already.. |
|
Can you guide me to the repo? |
|
You need at least torchvision>=0.8.1 for YOLOv5. |
|
@DP1701 I would have to agree with you here! but it or they rather is not installing no matter what I do! Maybe I should just update the repo files and be done with it???!!! |
|
If by repo files you mean the files from YOLO, then nothing will change. Alternatively, you could try miniforge (Conda): Link. After the installation, create a new environment with: Then install Pytorch with the Conda instruction |
|
And then install the rest that YOLOv5 needs with pip |
|
@DP1701 Ok will try that now.. |
Hi @DP1701 I got this: |
|
insert a second - character before name: |
|
ok will try that now |
may I request some guidance on the torch command that I should apply here, please? My confidence is a tad low, I thought I had an idea, but it seems like it's more tricky than expected! Thus far, I have been unsuccessful with my selection of the torch.. |
|
You must first install torch and torchvision with Conda if you have installed and activated the environment correctly. Take a look at the link to Pytorch that I sent you today. |
|
@DP1701 I see but when I check out the compatibility pytorch/pytorch#47776 Torch doesn't work well here??!!!??! SO I tried AND I GOT THE ERROR BELOW* |
I'm in need of some assistance to understand this, please. |
Search before asking
YOLOv5 Component
Training
Bug
Training does not take place if the --multi-scale option is activated. Stops directly in the first epoch at the beginning.
YOLOv5 🚀 v6.1-170-gbff6e51 torch 1.11.0+cu113 CUDA:0 (A100-SXM4-40GB, 40537MiB)
Python 3.8.10
pip list
Package Version
absl-py 1.0.0
albumentations 1.1.0
cachetools 4.2.4
certifi 2021.10.8
charset-normalizer 2.0.9
cycler 0.11.0
fonttools 4.28.3
google-auth 2.3.3
google-auth-oauthlib 0.4.6
grpcio 1.42.0
idna 3.3
imageio 2.13.3
importlib-metadata 4.8.2
joblib 1.1.0
kiwisolver 1.3.2
Markdown 3.3.6
matplotlib 3.5.1
networkx 2.6.3
numpy 1.21.4
oauthlib 3.1.1
opencv-python 4.5.4.60
opencv-python-headless 4.5.4.60
packaging 21.3
pandas 1.3.5
Pillow 8.4.0
pip 20.0.2
pkg-resources 0.0.0
protobuf 3.19.1
pyasn1 0.4.8
pyasn1-modules 0.2.8
pyparsing 3.0.6
python-dateutil 2.8.2
pytz 2021.3
PyWavelets 1.2.0
PyYAML 6.0
qudida 0.0.4
requests 2.26.0
requests-oauthlib 1.3.0
rsa 4.8
scikit-image 0.19.0
scikit-learn 1.0.1
scipy 1.7.3
seaborn 0.11.2
setuptools 44.0.0
six 1.16.0
tensorboard 2.7.0
tensorboard-data-server 0.6.1
tensorboard-plugin-wit 1.8.0
thop 0.0.31.post2005241907
threadpoolctl 3.0.0
tifffile 2021.11.2
torch 1.11.0+cu113
torchaudio 0.11.0+cu113
torchvision 0.12.0+cu113
tqdm 4.62.3
typing-extensions 4.0.1
urllib3 1.26.7
Werkzeug 2.0.2
wheel 0.37.0
zipp 3.6.0
nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Thu_Feb_10_18:23:41_PST_2022
Cuda compilation tools, release 11.6, V11.6.112
Build cuda_11.6.r11.6/compiler.30978841_0
Ubuntu 20.04.3 LTS
The text was updated successfully, but these errors were encountered: