

performance Rust backend for the Outlines library.
faster_outlines is designed to significantly boost the performance of regex-guided text generation, particularly for LLM inference servers. It's an ideal solution for scenarios where regex patterns for guiding LLM generation are not known in advance.
Key features:
- 🚀 Seamless one-line integration with existing Outlines projects
- 🚀 All the features you already love about outlines
- ⚡ Asynchronous FSM compilation for immediate start of LLM inference
- 🏎️ Substantial performance improvements, especially for complex regex patterns ( like JSON )
- 🔄 Continuous updates to improve speed!
Upcoming:
- 🍴 vLLM fork using faster_outlines
- 🤝 Official integration with vLLM's main repo (hopefully)
- Better FSM Caching
- Redis as a caching backend, for large inference setups
-
Optimized for LLM Inference Servers: Ideal for scenarios where regex patterns are dynamic and not known beforehand.
-
Asynchronous Processing: Unlike the standard Outlines library, faster_outlines allows you to start LLM inference immediately, without waiting for the entire FSM to compile.
-
Significant Performance Boost: Especially noticeable with complex regex patterns and large state spaces.
-
Seamless Integration: Works with your existing Outlines code with minimal changes.
pip install faster_outlinesIntegrating faster_outlines into your project is as simple as adding one line of code:
import outlines
from faster_outlines import patch
patch(outlines)
# Now use outlines as you normally would
# Your code here...import outlines
from faster_outlines import patch
patch(outlines)
model = outlines.models.transformers("mistralai/Mistral-7B-Instruct-v0.2", device="cuda:0", model_kwargs={"load_in_8bit": True})
schema = '''{
"title": "Character",
"type": "object",
"properties": {
"name": {
"title": "Name",
"maxLength": 10,
"type": "string"
},
"age": {
"title": "Age",
"type": "integer"
},
"armor": {"$ref": "#/definitions/Armor"},
"weapon": {"$ref": "#/definitions/Weapon"},
"strength": {
"title": "Strength",
"type": "integer"
}
},
"required": ["name", "age", "armor", "weapon", "strength"],
"definitions": {
"Armor": {
"title": "Armor",
"description": "An enumeration.",
"enum": ["leather", "chainmail", "plate"],
"type": "string"
},
"Weapon": {
"title": "Weapon",
"description": "An enumeration.",
"enum": ["sword", "axe", "mace", "spear", "bow", "crossbow"],
"type": "string"
}
}
}'''
model = outlines.models.transformers("mistralai/Mistral-7B-Instruct-v0.2", device="cuda:0", model_kwargs={"load_in_8bit": True})
print("Model loaded.")
generator = outlines.generate.json(model, schema)
character = generator("Give me a character description")
print(character)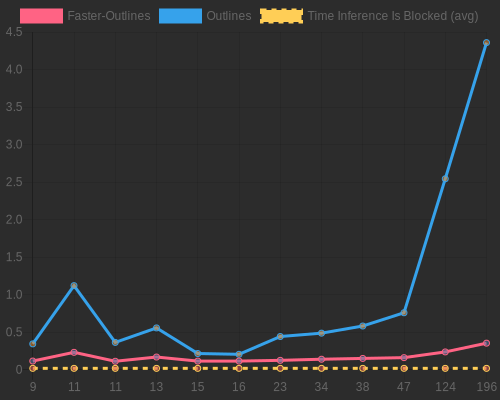
The graph above illustrates the performance advantage of faster_outlines over the standard Outlines library. As the complexity of regex patterns increases (measured by the number of FSM states), faster_outlines maintains significantly lower processing times.
For even faster compilation times on machines with more powerful CPUs ( such as inference servers ), the number of threads is automatically scaled according to the number of available threads. scaling rules are as follows:
- 1-4 CPU threads: Uses 1 thread
- 5-8 CPU threads: Uses 2 threads
- 9+ CPU threads: Uses ~1/4 of available threads (min 2, max 16)
However, if you would like to manually control the number of threads used, you can do so via environment variable:
export FASTER_OUTLINES_NUM_THREADS=<num-threads>Please note that setting the number of threads to a number higher than the number of cores / logical threads on your machine WILL DETERIORATE PERFORMANCE, not improve it.
If you would like to test performance at different thread counts on your machine, you can use the script at tests/test_fsm_comp_time.py, by first running the script using the automatic thread count ( or what ever you are currently using ), and then the number of threads you are thinking of using.
faster_outlines is designed to be fully compatible with the Outlines API, however, currently only full support for version 0.0.46 ( latest as of 7/13/24 ) can be garunteed.
We welcome contributions!
If you would like to support the further development and more speed improvements for faster_outlines, please consider supporting us on Github sponsors, or make a donation using the Buy-Me-A-Coffee link below!

If you have an issue with the lib, please, please open a github issue describing how to reproduce it, and we will be sure to work on fixing it.
- This project builds upon the excellent work of the Outlines library.
Citations:
@article{willard2023efficient,
title={Efficient Guided Generation for LLMs},
author={Willard, Brandon T and Louf, R{\'e}mi},
journal={arXiv preprint arXiv:2307.09702},
year={2023}
}