{kind=link}
Learning from Guided Play: Improving Exploration for Adversarial Imitation Learning with Simple Auxiliary Tasks
IEEE Robotics and Automation Letters (RA-L) presented at the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS'23), Detroit, MI, USA, Oct. 1-5, 2023
Paper website: https://papers.starslab.ca/lfgp/
Presented as "Learning from Guided Play: A Scheduled Hierarchical Approach for Improving Exploration in Adversarial Imitation Learning" as a poster at the NeurIPS 2021 Deep Reinforcement Learning Workshop.
NeurIPS workshop arXiv paper: https://arxiv.org/abs/2112.08932
The code in this repository has been updated significantly for our new submission, value-penalized auxiliary control from examples (VPACE). For more information on that submission and corresponding experiments, see its repository. For learning from guided play (LfGP), see the remainder of this README.
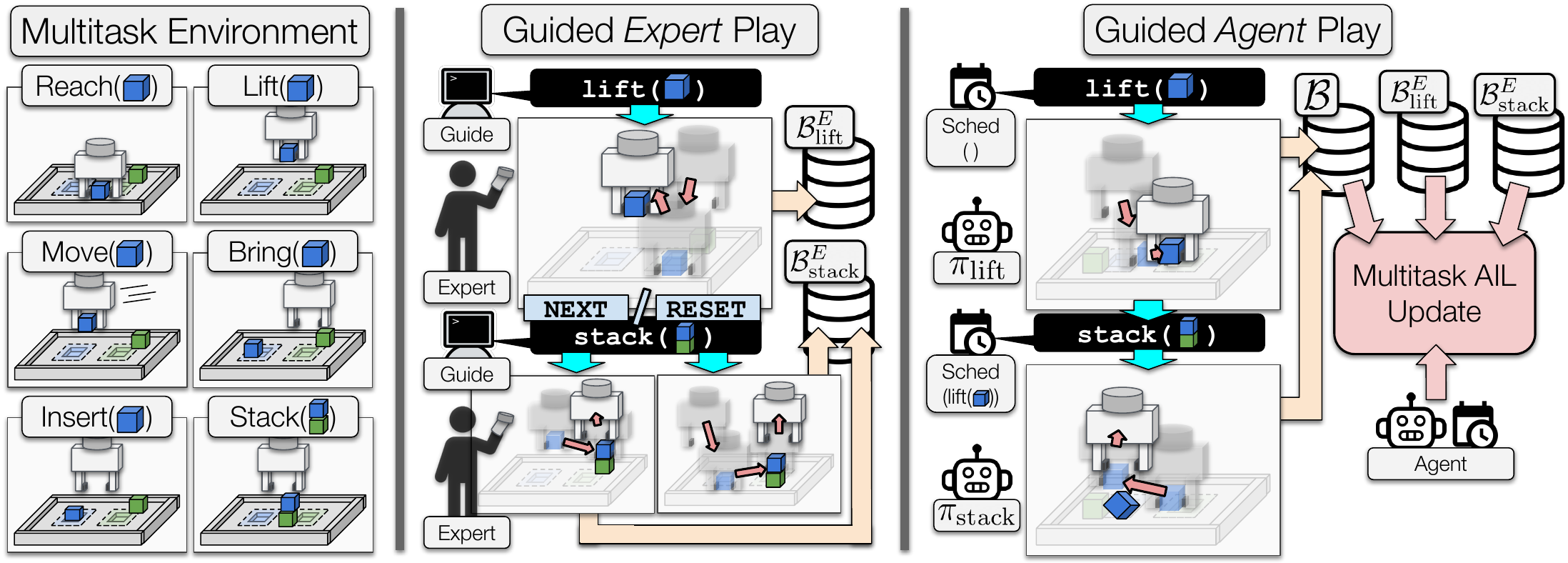
Adversarial Imitation Learning (AIL) is a technique for learning from demonstrations that helps remedy the distribution shift problem that occurs with supervised learning (Behavioural Cloning). In our paper, we show through many experiments and analysis that, in manipulation environments, AIL suffers from deceptive rewards, leading to suboptimal policies. In this work, we resolve this by enforcing exploration of a set of easy-to-define auxiliary tasks, in addition to a main task.
This repository contains the source code for reproducing our results.
We recommend setting up a virtual environment (e.g. virtualenv, conda, pyenv, etc.).
We also recommend using Python 3.9, as that was used for generating our experimental results, but the code should work with other versions as well.
In the following, we assume the working directory is the directory containing this README:
.
├── lfgp_data/
├── pytorch-a2c-ppo-acktr-gail/
├── rl_sandbox/
├── scripts/
├── six_state_mdp.py
└── README.md
To install, simply clone and install with pip, which will automatically install all dependencies:
git clone git@github.com:utiasSTARS/lfgp.git && cd lfgp
pip install rl_sandbox/
To quickly get started training or testing models, first download the expert data (also including trained models) from here (400MB): lfgp_data. Add it to the top level folder as shown above.
First, switch into the scripts folder:
cd scripts/experimentsTo train a Stack model with LfGP, run the following:
bash lfgp.bash 1 cuda:0 stack 1000_steps local wrs_plus_handcraft .95 .1 testTake a look at the bash script to see what each of the arguments means.
Use these scripts to train Multitask BC, DAC, and BC:
bash multi_bc_no_overfit.bash 1 cuda:0 stack 1000_steps local testbash dac.bash 1 cuda:0 stack 6000_steps local .95 .1 testbash bc_no_overfit.bash 1 cuda:0 stack 6000_steps local testFor reference, on a V100 gpu, our train times (to 2M steps) were approximately:
| Algorithm | Time |
|---|---|
| LfGP | 32h |
| Multitask BC | 20h |
| DAC | 12h |
| BC | 3h |
To evaluate and/or view a trained Stack model, switch into the evaluation folder, and run the following script:
bash visualize_model.bash 42 "stack/lfgp_wrs_hc" "state_dict.pt" "lfgp_experiment_setting.pkl" 50 2 true false ""Switch the second last argument from false to true to turn on simple rendering.
You can recreate our datasets or create new ones using the scripts in create_data.
To create a multitask dataset for the stack task, with 1000 (s,a) pairs per task and without extra final transition pairs, run:
cd scripts/create_data
bash create_expert_data.bash stack 1000To create a modified stack dataset that has 400 regular (s,a) pairs and 100 extra final transitions, run
bash create_modified_data.bash stack 1000 400 100 1Note that the datasets contained in our provided lfgp_folder already include the extra final transitions (e.g., the 1000_steps datasets actually have 800 (s,a) pairs and 200 extra final transitions per task).
In this paper, we evaluated our method in the four environments listed below:
bring # bring blue block to blue zone
stack # stack blue block onto green block
insert # insert blue block into blue zone slot
unstack_stack_env_only # remove green block from blue block, and stack blue block onto green block
The expert and trained lfgp models can be found at this google drive link. The zip file is 400MB. All of our generated expert data is included, but we only include single seeds of each trained model to reduce the size.
This subsection provides the desired directory structure that we will be assuming for the remaining README.
The unzipped lfgp_data directory follows the structure:
.
├── lfgp_data/
│ ├── expert_data/
│ │ ├── stack/
│ │ │ ├── 500_steps/
│ │ │ │ ├── int_0.gz
│ │ │ │ ├── int_1.gz
│ │ │ │ ├── ...
│ │ │ │ └── int_6.gz
│ │ │ ├── 1000_steps/
│ │ │ ├── ...
│ │ │ └── 9000_steps/
│ │ │ └── int_2.gz # only one task for single-task models
│ │ ├── bring/
│ │ │ ├── 1000_steps/
│ │ │ │ ├── int_0.gz
│ │ │ │ ├── int_1.gz
│ │ │ │ ├── ...
│ │ │ │ └── int_6.gz
│ │ │ └── 6000_steps/
│ │ │ └── int_2.gz # only one task for single-task models
│ │ ├── insert/
│ │ │ └── (same as bring)/
│ │ └── unstack_stack_env_only/
│ │ └── (same as bring)/
│ └── trained_models/
│ ├── experts/
│ │ ├── stack/
│ │ | ├── sacx_experiment_setting.pkl
│ │ | └── state_dict.pt
│ │ ├── unstack_stack_env_only/
│ │ ├── insert/
│ │ └── bring/
│ ├── stack/
│ │ ├── bc/
│ │ ├── dac/
│ │ ├── lfgp_wrs_hc/
│ │ └── multitask_bc/
│ ├── unstack_stack_env_only_0/
│ ├── insert/
│ ├── bring/
│ └── ablations/
│ ├── data/
│ | ├── half_data/
│ | ├── no_extra_final/
│ | ├── oneandahalf_data/
│ | └── subsampled
│ ├── baseline_alternatives/
│ ├── sampling/
│ └── scheduler/
├── manipulator-learning/
├── pytorch-a2c-ppo-acktr-gail/
├── rl_sandbox/
└── README.md
This repository uses a version of gym that is deprecated, and will not install correctly anymore. To install it you must first execute
pip install setuptools==65.5.0 pip==21 # gym 0.21 installation is broken with more recent versionsThen, you can pip install rl_sandbox as described.
If you use this in your work, please cite:
@misc{ablett2021learning,
title={Learning from Guided Play: A Scheduled Hierarchical Approach for Improving Exploration in Adversarial Imitation Learning},
author={Trevor Ablett and Bryan Chan and Jonathan Kelly},
year={2021},
eprint={2112.08932},
archivePrefix={arXiv},
primaryClass={cs.LG}
}