fix(apiWatch): deep watch should support symbols, performance tweaks #402
Conversation
| // to register mutation dep for existing keys | ||
| traverse(value.get(key), seen) | ||
| }) | ||
| const keys = [...value.keys()] |
There was a problem hiding this comment.
The cost here is almost the same because it involves spreading the iterator into a plain array. The array spread can often be deceivingly expensive. Not really worth it IMO.
There was a problem hiding this comment.
I tested set iterating in some browsers:
Chrome 79.0.3941.4 (64 bit, V8 7.9.293)

Firefox 70.0 (64 bit) (мс stands for millisecond in Russian, таймер закончился = timer ended)

I ran tests in Node too, but I had to call functions separately since console gets clogged but I don't want to change the task:
Node v12.8.0 (64 bit):
I loaded the same start code:
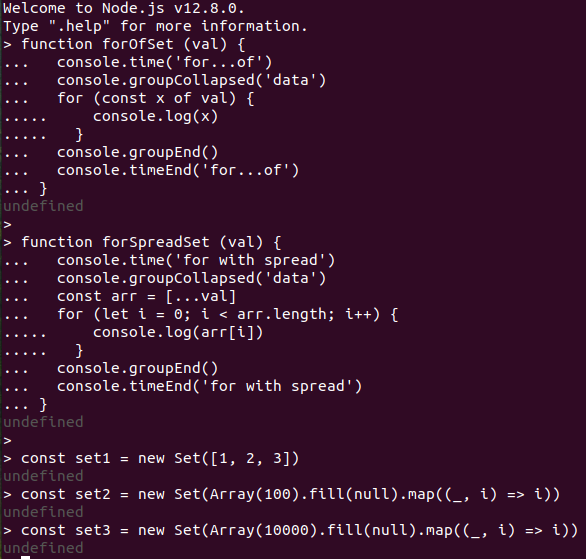
Small set:
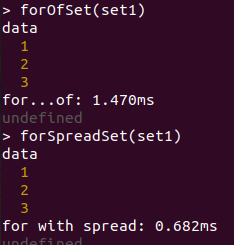
100 elements:
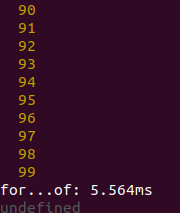
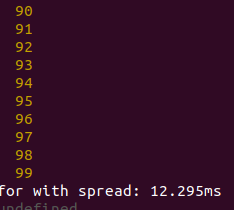
Now, 10k elements:
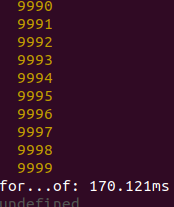
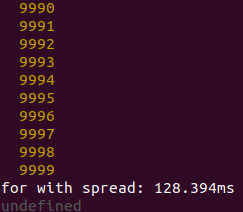
So, spread method gives better performance than for...of, but (why?) was worse in Chrome and Node with 100-element set
Code:
function forOfSet (val) {
console.time('for...of')
console.groupCollapsed('data')
for (const x of val) {
console.log(x)
}
console.groupEnd()
console.timeEnd('for...of')
}
function forSpreadSet (val) {
console.time('for with spread')
console.groupCollapsed('data')
const arr = [...val]
for (let i = 0; i < arr.length; i++) {
console.log(arr[i])
}
console.groupEnd()
console.timeEnd('for with spread')
}
const set1 = new Set([1, 2, 3])
const set2 = new Set(Array(100).fill(null).map((_, i) => i))
const set3 = new Set(Array(10000).fill(null).map((_, i) => i))
forOfSet(set1)
forSpreadSet(set1)
forOfSet(set2)
forSpreadSet(set2)
forOfSet(set3)
forSpreadSet(set3)There was a problem hiding this comment.
On my side I see no significant difference even with a million items in the set. I've looked at both timing and memory performance indicators, refreshing the page for each particular method (so run test with spread, change code to for..of and refresh, a few times over).
Chrome Version 79.0.3945.88 (Official Build) (64-bit) on MacOS Catalina (10.14.6) (spec 2.4GHz i5, 16GB 2133MHz LPDDR3) by launching chrome with:
/Applications/Google\ Chrome.app/Contents/MacOS/Google\ Chrome --enable-precise-memory-info --js-flags="--trace-opt --trace-deopt"
function forOfSet(val, index) {
console.time('for set' + index)
const acc = []
// const arr = [...val]
for (const x of val) acc.push(x)
// for (let i=0; i<arr.length; i++) acc.push(arr[i])
console.timeEnd('for set' + index)
console.log('memory: total, used, sizeLimit:', window.performance.memory.totalJSHeapSize, window.performance.memory.usedJSHeapSize, window.performance.memory.jsHeapSizeLimit)
console.log(acc)
}
const set1 = new Set([1,2,3])
const set2 = new Set(Array(100).fill(null).map((_,i) => i))
const set3 = new Set(Array(1000).fill(null).map((_,i) => i))
const set4 = new Set(Array(1000000).fill(null).map((_,i) => i))
// forOfSet(set1, 1)
// forOfSet(set2, 2)
// forOfSet(set3, 3)
forOfSet(set4, 4)
The timing varies with each refresh in a range of 30 to 45 ms, regardless of the loop method being used.

| for (const key in value) { | ||
| traverse(value[key], seen) | ||
| const keys = [ | ||
| ...Object.getOwnPropertyNames(value), |
There was a problem hiding this comment.
Not sure if this should be the case here. This would iterate over non-enumerable properties too.
There was a problem hiding this comment.
I think the technically correct implementation here is using getOwnPropertyDescriptors and then traverse enumerable properties. But I don't know if it's worth it. May want a benchmark to evaluate the perf cost compared to a simple for...in.
There was a problem hiding this comment.
I can try to make a benchmark just as in upper comment :).
There was a problem hiding this comment.
But for...in seems not to list symbols.
There was a problem hiding this comment.
Benchmark (anything as the first comment):
Chrome:

FF:

Node:






Results of this benchmark are questionable, and I think both of these should be validated in e.g. a CI env, since my CPU frequency and load isn't really stable.
Code:
function forInObject (val) {
console.time('for...in')
console.groupCollapsed('data')
for (const x in val) {
console.log(x)
}
console.groupEnd()
console.timeEnd('for...in')
}
function forSpreadSet (val) {
console.time('for with spread keys')
console.groupCollapsed('data')
const arr = [...Object.keys(val)]
for (let i = 0; i < arr.length; i++) {
console.log(arr[i])
}
console.groupEnd()
console.timeEnd('for with spread keys')
}
const obj1 = { '1': 1, '2': 2, '3': 3 }
const obj2 = {}
for (let i = 0; i < 100; i++) {
obj2[i] = i
}
const obj3 = {}
for (let i = 0; i < 10000; i++) {
obj3[i] = i
}
forInObject(obj1)
forSpreadSet(obj1)
forInObject(obj2)
forSpreadSet(obj2)
forInObject(obj3)
forSpreadSet(obj3)|
I just stumbled upon this thread randomly and I need to say that I would stay away from microoptimizations like this because they have very noisy and unpredictable results. Since this is not the first time I see things like this here, I have a few things to note:
This all combined means, that if you want to reliably optimize something in JS, you can only make very few assumptions and only do things that are reliably better.
Last point is especially a problem with this PR - for example, instead of iterating over Map with builtin Now it's improtant to note - that might actually be faster at the moment. It is possible that you hit some weird edge case that browsers didn't cover. But because it is semantically more work, you can't rely that this will be the case in the future. Browsers may catch up in the next release and optimize the builtin better. Manual iteration can also be a bit sneaky. Even though it is faster than functional iteration in lower level languages, in JavaScript it gives the developer too much freedom, so the engine first need to "figure out" that it actually is manual iteration. If you ask for an element on index with If you use That's why optimizations like this that just "do the same thing but in a slighly different syntax" are usually not worth it. Anyway, this ended up being much longer than I first expected, but I hope it gives some useful information to consider 😉 I don't mean this to be overly negative, it's great to work on performance. I just wanted to clarify some concerns, because I myself lost a lot of time optimizing JS code and it is often very counter intuitive and you can't just make straightforward conclusions. |
Increased perf of
traverseusingfor (let i...) {}instead offor...in/for...of. Fixed traverse so it will track symbols and add a test case for symbol.