「nodejs + docker + github pages 」 定制自己的 「今日头条」 #17
Description
前言
在闲暇之余,我们经常会逛各种社区,逛掘金看技术软文,逛虎扑看今日赛事,逛头条看热门时事,逛 91……
每个社区都有各种各样的资讯,但有时我们只想看某个社区的某些资讯。那我们能不能将这些社区里我们想要的信息做一下整合 定制成自己的“今日头条”呢?
思路
每天定时抓取 资讯的标题和链接 整合后发布到自己的网站 这样每天只要打开自己的网站就可以看到属于自己的今日头条啦~
- 抓取资讯 puppeteer
- 定时任务 node-schedule
- 部署 docker + github pages
我的今日头条
- 掘金社区 前端热门文章
- 今日头条 热门时事
- 虎扑社区 nba 赛事
- QQ 音乐 热门音乐
ok,开撸...
项目初始化
npm init -ytoday's hot
│ README.md
└───html
│ │ index.html // 网站入口,用于部署github pages
└───resource
│ │ index.json // 资讯数据,爬取存放文件
└───tasks // 任务队列
│ │ index.js
│ │ juejin.js
│ │ top.js
│ │ nba.js
│ │ music.js
│ │ jianshu.js
└───tools // 工具类
│ index.js
│ index.js // 工程入口
│ package.json
抓取资讯
抓取资讯 我使用的是 puppeteer,它是 Google Chrome 团队官方的一个工具,提供了一些 API 来控制 chrome!(一听就很刺激。)
npm i puppeteer --save
我们先写一个简单的 demo 来了解一些 puppeteer 的基本 api.
const puppeteer = require("puppeteer");
const task = async () => {
// 打开chrome浏览器
const browser = await puppeteer.launch({
// 关闭无头模式,方便查看
headless: false
});
// 新建页面
const page = await browser.newPage();
// 跳转到掘金
await page.goto("https://juejin.im");
// 截屏保存
await page.screenshot({
path: "./juejin.png"
});
};
task();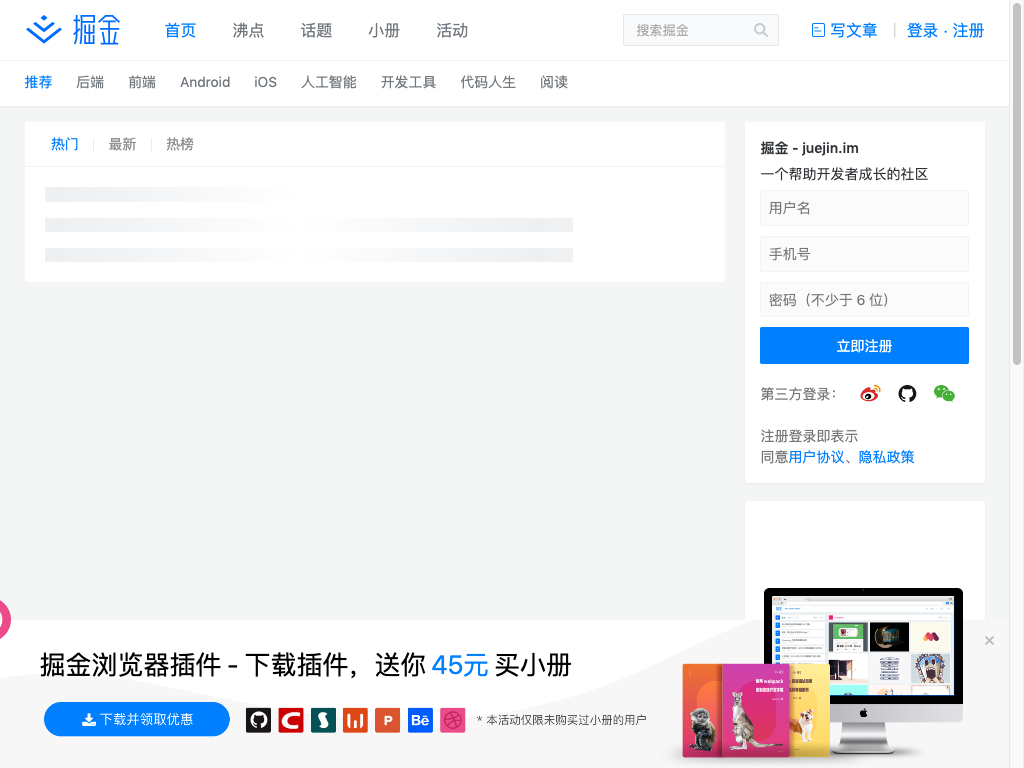
ok~我们趁阴明站长不在的时候,来掘金"拿点"东西~
掘金的前端热门文章是我比较关注的模块,我们来"拿"这个模块的资讯.
const puppeteer = require("puppeteer");
const task = async () => {
// 打开chrome浏览器
const browser = await puppeteer.launch({
headless: false
});
// 新建页面
const page = await browser.newPage();
// 跳转到掘金
await page.goto("https://juejin.im");
// 菜单导航对应的类名
const navSelector = ".view-nav .nav-item";
// 前端菜单
const navType = "前端";
// 等待菜单加载完成...
await page.waitFor(navSelector);
// 菜单导航名称
const navList = await page.$$eval(navSelector, ele =>
ele.map(el => el.innerText)
); // [ '推荐', '后端', '前端', 'Android', 'iOS', '人工智能', '开发工具', '代码人生', '阅读' ]
// 找出菜单中前端模块对应的索引
const webNavIndex = navList.findIndex(item => item === navType);
// 点击前端模块并等待页面跳转完成
await Promise.all([
page.waitForNavigation(),
page.click(`${navSelector}:nth-child(${webNavIndex + 1})`)
]);
// 截屏保存
await page.screenshot({
path: "./juejin-web.png"
});
};
task();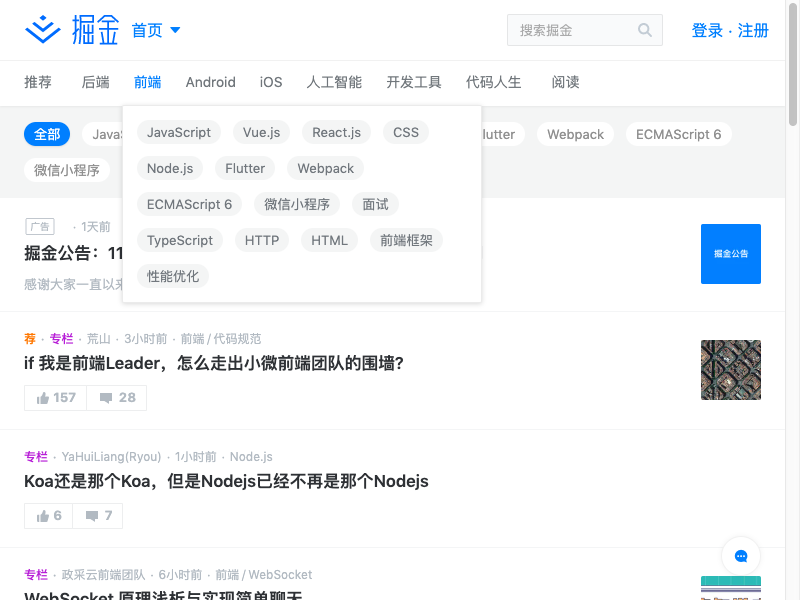
上图可以看到,我们已经跳转到了前端模块.
接下来,我们只要找出文章列表对应的类名就可以对它进行爬取.
const puppeteer = require("puppeteer");
const task = async () => {
// 打开chrome浏览器
const browser = await puppeteer.launch({
headless: false
});
// 新建页面
const page = await browser.newPage();
// 跳转到掘金
await page.goto("https://juejin.im");
// 菜单导航选择器
const navSelector = ".view-nav .nav-item";
// 文章列表选择器
const listSelector = ".entry-list .item a.title";
// 菜单类别
const navType = "前端";
await page.waitFor(navSelector);
// 导航列表
const navList = await page.$$eval(navSelector, ele =>
ele.map(el => el.innerText)
);
// 前端导航索引
const webNavIndex = navList.findIndex(item => item === navType);
await Promise.all([
page.waitForNavigation(),
page.click(`${navSelector}:nth-child(${webNavIndex + 1})`)
]);
// 等待文章列表选择器加载完成
await page.waitForSelector(listSelector, {
timeout: 5000
});
// 通过选择器找到对应列表项的标题和链接
const res = await page.$$eval(listSelector, ele =>
ele.map(el => ({
url: el.href,
text: el.innerText
}))
);
// [ { url: 'https://juejin.im/post/5dd55512f265da47a807cc06',
// text: 'if 我是前端Leader,怎么走出小微前端团队的围墙?' },
// { url: 'https://juejin.im/post/5dd49a45e51d45400206a655',
// text: 'Koa还是那个Koa,但是Nodejs已经不再是那个Nodejs' },
// { url: 'https://juejin.im/post/5dd4b991e51d450818244c30',
// text: 'WebSocket 原理浅析与实现简单聊天' },...
};
task();ok,我们已经成功拿到了掘金前端热门文章的内容,趁站长还没来,赶紧溜~其他网站也是一样的方法,这里就不啰嗦了~
我们拿到了资讯,接下来对它进行保存。
保存资讯
因为只是玩具级别的 demo,这里就不用数据库了,简单的用 json 进行保存。
// resource/index.json
{
"data": []
}我们基于 nodejs fs 文件操作模块,简单封装读写方法。
// tools/index.js
const fs = require("fs");
const fileServer = {
// 写文件
write(path, text) {
fs.writeFileSync(path, text);
},
// 读文件
read(path) {
return fs.readFileSync(path);
}
};接下来,我们只要在每次获取完资讯,将内容写进文件就好了
const { fileServer } = require("./tools");
const path = require("path");
const task = () => {
// 获取资讯任务
const getMsgTask = Promise.all(tasks());
getMsgTask.then(res => {
// 读取json
const { data } = JSON.parse(
fileServer.read(path.join(resourcePath, "./index.json")).toString()
);
// ... 此处省略对资讯 格式化内容
const text = msgHandle(res);
// 写入资讯
fileServer.write(
path.join(resourcePath, "./index.json"),
JSON.stringify({
data: [
{
date: now,
text
},
...data
]
})
);
});
};保存完资讯,我们只要请求这个文件,将它渲染出来就好了~
// html/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>今日资讯</title>
<script src="https://cdn.bootcss.com/marked/0.7.0/marked.min.js"></script>
<script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.min.js"></script>
</head>
<body>
<div id="content"></div>
</body>
<script>
(function() {
$(document).ready(function() {
$.ajax({
url: "http://localhost:8888/index.json",
dataType: "json",
success(data) {
const content = data.data.reduce((a, b) => a + b.text, "");
// 资讯我使用的是markdown进行保存,所以用marked进行转换
$("#content").html(marked(content));
}
});
});
})();
</script>
</html>定时任务
定时任务使用的是node-schedule,非常简单易用的一个 nodejs 库。
// 每日18时定时任务
function crontab() {
schedule.scheduleJob(`00 00 18 * * *`, mainTask);
}
// 任务
function mainTask(){...}部署
部署我采用的是 docker + github pages 。
docker 部署这里有两个要注意的地方
-
时区问题:docker 时区是 UTC,和北京时间差了 8 小时,会导致我们的定时任务时间失准.
-
docker 和 puppeteer chorium 源问题 ...
# Dockerfile
FROM node:10-slim
# 创建项目代码的目录
RUN mkdir -p /workspace
# 指定RUN、CMD与ENTRYPOINT命令的工作目录
WORKDIR /workspace
# 复制宿主机当前路径下所有文件到docker的工作目录
COPY . /workspace
# 清除npm缓存文件
RUN npm cache clean --force && npm cache verify
# 如果设置为true,则当运行package scripts时禁止UID/GID互相切换
# RUN npm config set unsafe-perm true
RUN npm config set registry "https://registry.npm.taobao.org"
RUN npm install -g pm2@latest
# Install latest chrome dev package and fonts to support major charsets (Chinese, Japanese, Arabic, Hebrew, Thai and a few others)
# Note: this installs the necessary libs to make the bundled version of Chromium that Puppeteer
# installs, work. 此处有墙...
# https://github.com/GoogleChrome/puppeteer/blob/master/docs/troubleshooting.md
RUN wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add - \
&& sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list' \
&& apt-get update \
&& apt-get install -y google-chrome-unstable fonts-ipafont-gothic fonts-wqy-zenhei fonts-thai-tlwg fonts-kacst fonts-freefont-ttf \
--no-install-recommends \
&& rm -rf /var/lib/apt/lists/*
# 只安装package.json dependencies
RUN npm install --production
RUN npm i puppeteer
# 设置时区
RUN rm -rf /etc/localtime && ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
EXPOSE 8888
CMD [ "pm2-docker", "start", "pm2.json" ]
构建镜像 shell
# build.sh
docker build -t today-hot .启动容器 shell
# run.sh
curPath=`cd $(dirname $0);pwd -P`
docker run --name todayHot -d -v $curPath:/workspace -p 8888:8888 today-hot� 接下来只要把 html 文件部署到网站上即可,我们这里使用 github-pages ,免费的静态网站托管平台~
npm install gh-pages --save在 package.json 定义 scripts
"scripts": {
"deploy": "gh-pages -d html"
}
npm run deploy 将前端资源推送到github上,然后通过 xxx.github.io/xxx 就可以访问了结语
本文主要讲解的是思路,具体代码如下,爬虫 服务并没有部署到服务器,大家可以 download 代码自行尝试。
如果觉得有帮助到你,你懂的~