privategpt_zh
privateGPT 是一个开源项目,可以本地私有化部署,在不联网的情况下导入个人私有文档,然后像使用ChatGPT一样以自然语言的方式向文档提出问题,还可以搜索文档并进行对话。新版本只支持llama.cpp中的GGML格式模型。目前对于中文文档的问答还有BUG
如果你是UNIX (macOS或Linux)系统,且已经安装了python3.11环境,只需要以下几行代码就可以创建好使用环境
git clone https://github.com/imartinez/privateGPT && cd privateGPT && \
python3.11 -m venv .venv && source .venv/bin/activate && \
pip install --upgrade pip poetry && poetry install --with ui,local
修改privateGPT根目录下的settings.yaml文件,完整内容如下:
# The default configuration file.
# More information about configuration can be found in the documentation: https://docs.privategpt.dev/
# Syntax in `private_pgt/settings/settings.py`
server:
env_name: ${APP_ENV:prod}
port: ${PORT:8001}
cors:
enabled: false
allow_origins: ["*"]
allow_methods: ["*"]
allow_headers: ["*"]
auth:
enabled: false
# python -c 'import base64; print("Basic " + base64.b64encode("secret:key".encode()).decode())'
# 'secret' is the username and 'key' is the password for basic auth by default
# If the auth is enabled, this value must be set in the "Authorization" header of the request.
secret: "Basic c2VjcmV0OmtleQ=="
data:
local_data_folder: local_data/
ui:
enabled: true
path: /
default_chat_system_prompt: "You are a helpful assistant. 你是一个乐于助人的助手。"
default_query_system_prompt: >
You can only answer questions about the provided context.
If you know the answer but it is not based in the provided context, don't provide
the answer, just state the answer is not in the context provided.
llm:
mode: local
# Should be matching the selected model
max_new_tokens: 512
context_window: 4096
tokenizer: hfl/chinese-alpaca-2-7b
embedding:
# Should be matching the value above in most cases
mode: local
ingest_mode: simple
vectorstore:
database: qdrant
qdrant:
path: local_data/private_gpt/qdrant
local:
prompt_style: llama2
llm_hf_repo_id: hfl/chinese-alpaca-2-7b-gguf
llm_hf_model_file: ggml-model-q4_k.gguf
embedding_hf_model_name: sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
sagemaker:
llm_endpoint_name: huggingface-pytorch-tgi-inference-2023-09-25-19-53-32-140
embedding_endpoint_name: huggingface-pytorch-inference-2023-11-03-07-41-36-479
openai:
api_key: ${OPENAI_API_KEY:}
model: gpt-3.5-turbo
运行以下命令,privateGPT会根据上述settings.yaml中配置的model和tokenizer下载相应权重到models下
./scripts/setup
启动privateGPT API服务器和grado UI
poetry run python3.11 -m private_gpt
在浏览器窗口中打开http://localhost:8001/即可使用privateGPT对话并针对文档进行问答了。
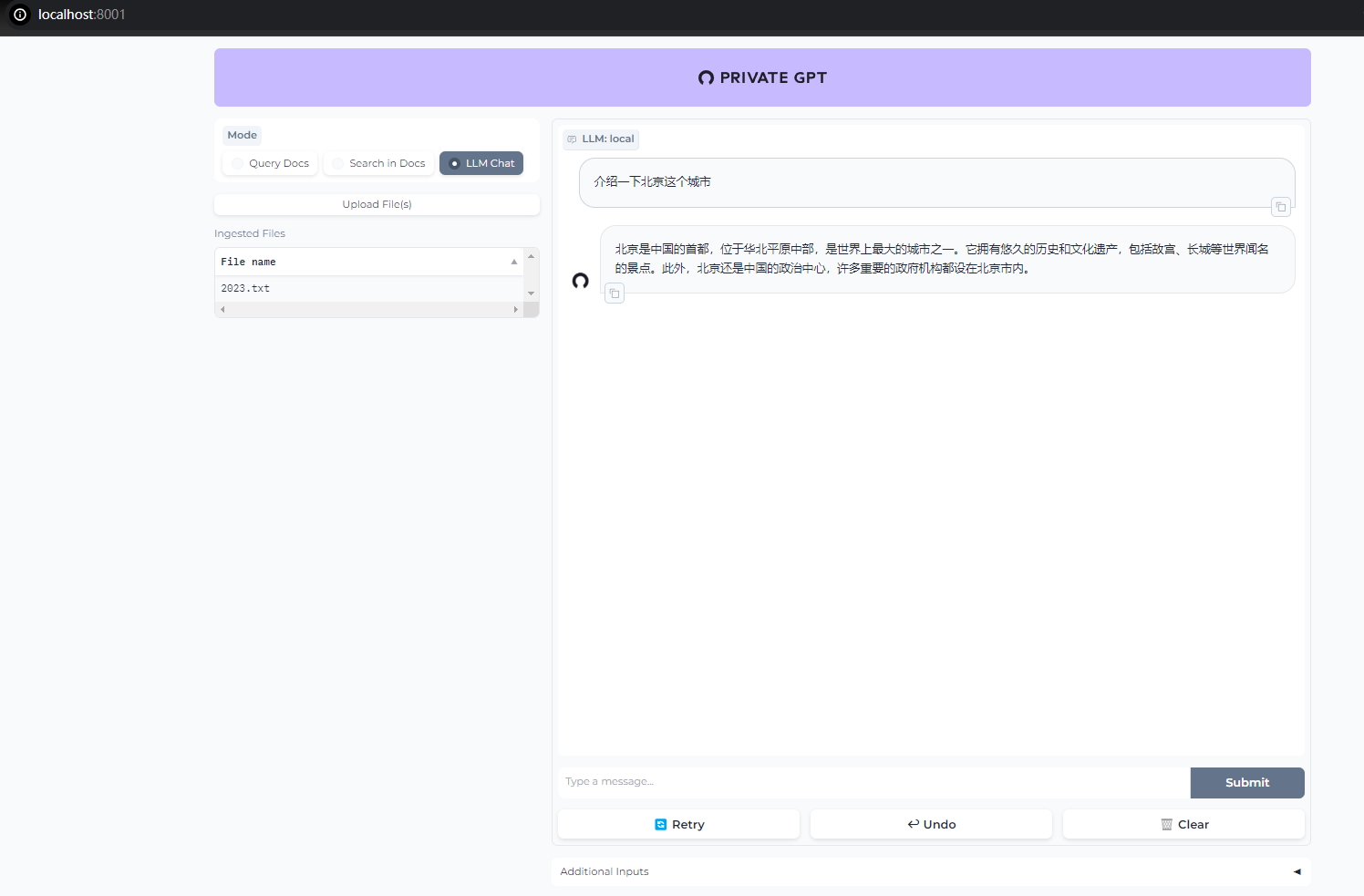
- privateGPT改版后,使用文档尚未完善,使用中可能存在未预知的问题,更详细的内容和用法请参考privateGPT官方目录:https://github.com/imartinez/privateGPT
- 新版privateGPT对中文文档的处理存在一些问题,如保存的数据库信息是乱码,文档问答时存在乱回复、与文档无联系等问题,反之英文文档则无此问题。大家有其它使用问题欢迎在issue/discussions或原privateGPT repo下提出,促进社区的完善。
旧版privateGPT适配流程
privateGPT 是基于llama-cpp-python和LangChain等的一个开源项目,旨在提供本地化文档分析并利用大模型来进行交互问答的接口。用户可以利用privateGPT对本地文档进行分析,并且利用GPT4All或llama.cpp兼容的大模型文件对文档内容进行提问和回答,确保了数据本地化和私有化。本文以llama.cpp中的GGML格式模型为例介绍privateGPT的使用方法。
更详细的内容和用法请参考privateGPT官方目录:https://github.com/imartinez/privateGPT
由于privateGPT中使用了llama.cpp中的GGML模型,这里需要提前安装llama-cpp-python扩展。注意:以下安装方式并没有使用任何加速库。
$ pip install llama-cpp-python💡 (推荐)如果希望安装OpenBLAS/cuBLAS/CLBlast/Metal适配的版本,请参考:https://github.com/abetlen/llama-cpp-python#installation-with-openblas--cublas--clblast
请确保当前安装环境中的python是支持arm64架构的,否则执行速度会慢10x以上。 测试方法是在安装llama-cpp-python之后,执行下述python命令,其中模型路径请替换成你本地的llama.cpp支持的GGML模型文件。
>>> from llama_cpp import Llama
>>> llm = Llama(model_path="./models/7B/ggml-model.bin")显示NEON = 1则表示正常,NEON = 0则表示并没有按arm64架构正确安装。下面给出的是支持ARM NEON加速的日志示例。
system_info: n_threads = 8 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
如果你使用conda,则可以使用以下命令创建相关环境,这里选择Python 3.10以满足privateGPT的要求。
$ CONDA_SUBDIR=osx-arm64 conda create -n privategpt python=3.10 -c conda-forge在正确安装llama-cpp-python之后,则可以继续安装privateGPT,具体命令如下(注意python >= 3.10)。
$ git clone https://github.com/imartinez/privateGPT.git
$ cd privateGPT
$ pip3 install -r requirements.txt在privateGPT根目录下创建一个名为.env的配置文件,写好的配置文件示例:
MODEL_TYPE=LlamaCpp
PERSIST_DIRECTORY=db
MODEL_PATH=your-path-to-ggml-model.bin
MODEL_N_CTX=4096
MODEL_N_BATCH=512
EMBEDDINGS_MODEL_NAME=sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
TARGET_SOURCE_CHUNKS=4- MODEL_TYPE:填写LlamaCpp
- PERSIST_DIRECTORY:填写分析文件存放位置,这里会在privateGPT根目录创建一个
db目录 - MODEL_PATH:指向大模型存放位置,这里指向的是llama.cpp支持的GGML文件
- MODEL_N_CTX:大模型的最大token限制,设置为4096(同llama.cpp
-c参数)。16K长上下文版模型可适当调高,不超过16384(16K)。 - MODEL_N_BATCH:prompt批处理大小(同llama.cpp
-b参数) - EMBEDDINGS_MODEL_NAME:SentenceTransformers词向量模型位置,可以指定HuggingFace上的路径(会自动下载),其他官方支持的模型可参考:https://www.sbert.net/docs/pretrained_models.html
- TARGET_SOURCE_CHUNKS:用于解答问题的chunk数量
privateGPT支持以下常规文档格式分析,例如(仅列举了最常用的):
-
Word文件:
.doc,.docx -
PPT文件:
.ppt,.pptx -
PDF文件:
.pdf -
纯文本文件:
.txt -
CSV文件:
.csv -
Markdown文件:
.md -
电子邮件文件:
.eml,.msg
将需要分析的文档(不限于单个文档)放到privateGPT根目录下的source_documents目录下。这里放入了3个关于“马斯克访华”相关的word文件。目录结构类似:
$ ls source_documents
musk1.docx musk2.docx musk3.docx下一步,运行ingest.py命令对文档进行分析。
$ python ingest.py输出如下(测试环境为M1 Max,解析只经历了几秒钟)。需要注意的是首次使用会下载(如果给出的是huggingface地址,而不是本地路径)配置文件中的词向量模型。
Creating new vectorstore
Loading documents from source_documents
Loading new documents: 100%|██████████████████████| 3/3 [00:02<00:00, 1.11it/s]
Loaded 3 new documents from source_documents
Split into 7 chunks of text (max. 500 tokens each)
Creating embeddings. May take some minutes...
Ingestion complete! You can now run privateGPT.py to query your documents
db目录中已经有相关分析文件,则会对数据文件进行积累。如果只想针对当前文档进行解析,请清空db目录后再ingest。
在正式运行之前,还需要对模型解码相关参数进行修改以便获得最好的速度和效果。
privateGPT.py实际是调用了llama-cpp-python的接口,因此如果不做任何代码修改则采用的默认解码策略。打开privateGPT.py查找以下语句(大约35行左右,根据不同版本有所不同)。
llm = LlamaCpp(model_path=model_path, max_tokens=model_n_ctx, callbacks=callbacks, verbose=False)这里即是LlamaCpp模型的定义,可根据llama-cpp-python的接口定义传入更多自定义参数,以下是其中一个示例,其中:
- n_threads:与llama.cpp中的
-n参数一致,定义解码线程数量,有助于提升解码速度,请根据实际物理核心数酌情配置 - n_ctx:与llama.cpp中的
-c参数一致,定义上下文窗口大小,默认512,这里设置为配置文件的model_n_ctx数量,即4096 - n_gpu_layers:与llama.cpp中的
-ngl参数一致,定义使用GPU的offload层数;苹果M系列芯片指定为1即可 - rope_freq_scale:默认设置为1.0,无需修改。但如果使用16K长上下文版模型,请设置为
rope_freq_scale=0.25
llm = LlamaCpp(model_path=model_path, max_tokens=model_n_ctx,
callbacks=callbacks, verbose=False,
n_threads=8, n_ctx=model_n_ctx, n_gpu_layers=1, rope_freq_scale=1.0)默认解码方法不包含任何的指令模板。接下来将介绍嵌套Alpaca-2指令模板的方法,以便使用正确的方式加载模型。
打开privateGPT.py查找以下语句(大约40行左右,根据不同版本有所不同)。
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff",
retriever=retriever, return_source_documents= not args.hide_source)替换为以下代码(注意调整indent):
alpaca2_prompt_template = (
"[INST] <<SYS>>\n"
"You are a helpful assistant. 你是一个乐于助人的助手。\n"
"<</SYS>>\n\n"
"{context}\n\n{question} [/INST]"
)
from langchain import PromptTemplate
input_with_prompt = PromptTemplate(template=alpaca2_prompt_template,
input_variables=["context", "question"])
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever,
return_source_documents= not args.hide_source,
chain_type_kwargs={"prompt": input_with_prompt})相关示例代码参考 >>> scripts/privategpt/privateGPT.py
在上一步分析文档结束后,可运行以下命令开始对文档提问:
$ python privateGPT.py出现以下提示之后即可输入问题,例如输入以下问题:
Enter a query: 马斯克此次访华可能有什么目的?
结果如下(略去来源文档部分输出):
> Question:
马斯克此次访华可能有什么目的?
> Answer (took 48.29 s.):
根据路透社披露的消息和报道分析,马斯克访华可能有以下一些目的:
1.加强与中国政府高层的互动沟通,推动特斯拉在中国市场的发展计划。此前中国监管部门对特斯拉在销售、售后服务等方面进行了多项整改措施,此次访问也可能涉及解决上述问题并寻求政府的支持。
2.参观特斯拉在上海拥有的超级工厂以及探索进一步扩大规模的可能性。上海工厂是目前全球最大的电动汽车工厂之一,扩建可能有利于加速产能提升和提高产量水平。
3.探讨与中国本土汽车制造商在市场上竞争的问题。随着特斯拉在中国市场的份额逐渐增加,其在与国产品牌之间的竞争关系也可能越来越重要,通过此次访问,马斯克可能会就这一问题提出建议或寻求解决办法。
4.推动电动汽车产业的全球合作和发展。作为全球最大的新能源汽车市场之一,中国市场对特斯拉的发展具有重要的战略意义。如果成功地拓展到中国,特斯拉将能够进一步扩大其在全球范围内的影响力并加速电动车普及进程。
阅读过程并不是非常快,解答过程比较快,整体上等了半分钟左右给出了相关结果,并且会给出4个数据来源。
输入exit则可结束脚本运行。
privateGPT.py中调用LangChain时默认使用的是stuff策略。该策略并不适用于处理特别长的文本。所以如果在处理长文档或多文档时效果不佳,可以换用refine或map_reduce等策略。若要使用refine,需先定义两个prompt模版(注意调整indent):
alpaca2_refine_prompt_template = (
"[INST] <<SYS>>\n"
"You are a helpful assistant. 你是一个乐于助人的助手。\n"
"<</SYS>>\n\n"
"这是原始问题:{question}\n"
"已有的回答: {existing_answer}\n"
"现在还有一些文字,(如果有需要)你可以根据它们完善现有的回答。"
"\n\n{context}\n\n"
"请根据新的文段,进一步完善你的回答。 [/INST]"
)
alpaca2_initial_prompt_template = (
"[INST] <<SYS>>\n"
"You are a helpful assistant. 你是一个乐于助人的助手。\n"
"<</SYS>>\n\n"
"以下为背景知识:\n{context}\n"
"请根据以上背景知识,回答这个问题:{question} [/INST]"
)并用如下方式初始化qa,替换原代码中的39行左右处的qa定义(注意调整indent):
from langchain import PromptTemplate
refine_prompt = PromptTemplate(
input_variables=["question", "existing_answer", "context_str"],
template=alpaca2_refine_prompt_template,
)
initial_qa_prompt = PromptTemplate(
input_variables=["context_str", "question"],
template=alpaca2_initial_prompt_template,
)
chain_type_kwargs = {"question_prompt": initial_qa_prompt, "refine_prompt": refine_prompt}
qa = RetrievalQA.from_chain_type(
llm=llm, chain_type="refine",
retriever=retriever, return_source_documents= not args.hide_source,
chain_type_kwargs=chain_type_kwargs)相关示例代码参考 >>> scripts/privategpt/privateGPT_refine.py System.out.println("Hello to see U!");