[ICCV 2025] Yuheng Liu1,2, Xinke Li3, Yuning Zhang4, Lu Qi5, Xin Li1, Wenping Wang1, Chongshou Li4, Xueting Li6*, Ming-Hsuan Yang2*
1Texas A&M University, 2The University of Cailfornia, Merced, 3City University of HongKong, 4Southwest Jiaotong University, 5Insta360 Research, 6NVIDIA
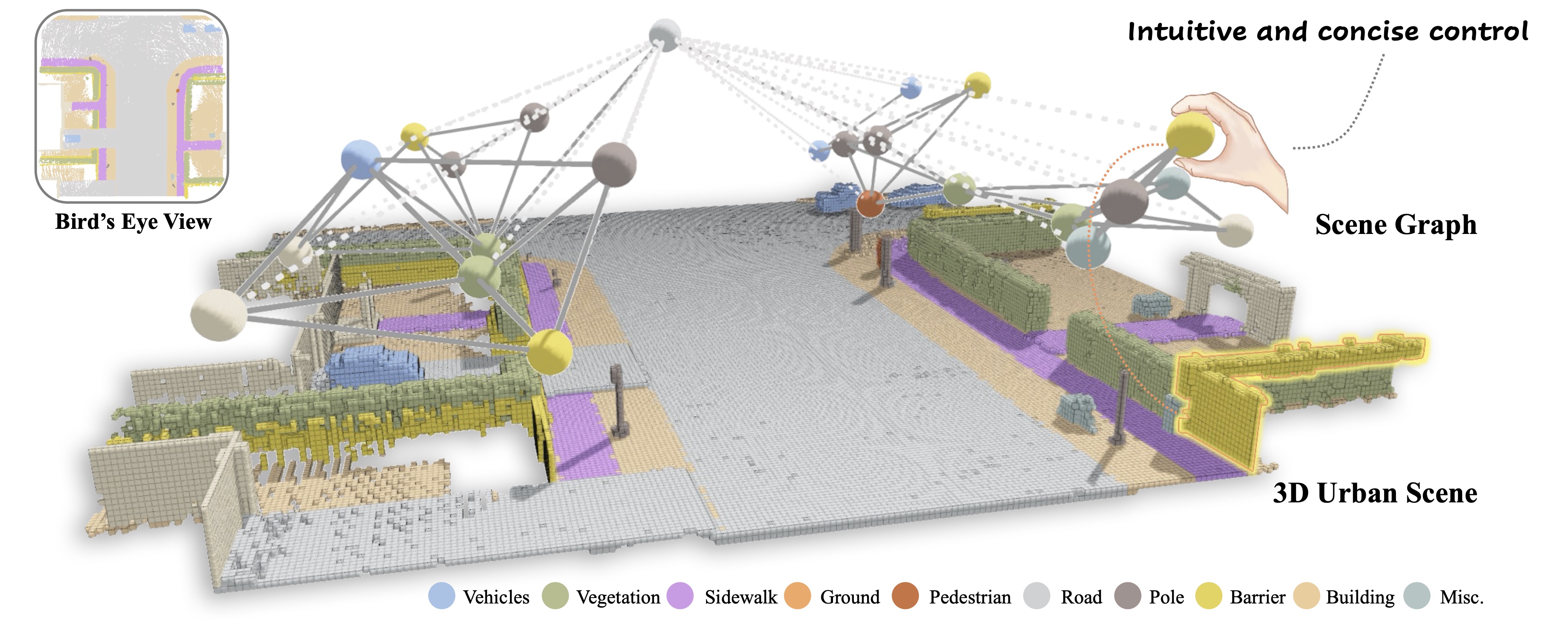
Three-dimensional scene generation is crucial in computer vision, with applications spanning autonomous driving, gaming and the metaverse. Current methods either lack user control or rely on imprecise, non-intuitive conditions. In this work, we propose a method that uses scene graphs—an accessible, user-friendly control format—to generate outdoor 3D scenes. We develop an interactive system that transforms a sparse scene graph into a dense BEV (Bird's Eye View) Embedding Layout, which guides a conditional diffusion model to generate 3D scenes that match the scene graph description. During inference, users can easily create or modify scene graphs to generate large-scale outdoor scenes. We create a large-scale dataset with paired scene graphs and 3D semantic scenes to train the BEV embedding and diffusion models. Experimental results show that our approach consistently produces high-quality 3D urban scenes closely aligned with the input scene graphs.
- [2025/06/25] Our work is accepted by ICCV 2025.
- [2025/03/10] Our work is now on arXiv.
- [2024/11/15] Official repo is created, code will be released soon.